Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
Elasticsearch 설치
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2024-09-19
2024-09-19
609
 # 소개 Elasticsearch를 설치하는 다양한 방법이 있는데, 개발 및 테스트 목적으로 가장 간단한 방법으로 설치해보려 한다. 로컬 PC에 설치하며, 보안 등도 신경쓰지 않는다. ❗이 방법은 테스트 목적으로만 사용한다. 학습 목적으로는 편리하게 사용 할 수 있지만 프로덕션 환경에서는 이런 방식으로 서비스를 실행하면 안된다. # ElasticSearch Install ### 환경 변수 설정 아래와 같이 환경 변수를 구성한다. 파일의 이름은 .env이다. ``` export ELASTIC_PASSWORD="<ES_PASSWORD>" # "elastic" 유저가 사용할 패스워드 export KIBANA_PASSWORD="<KIB_PASSWORD>" # kibana를 위해서 사용할 패스워드. 반드시 6자 이상이어야 한다. ``` 환경 변수를 로딩한다. ``` source .env ``` ### Docker Network 생성 ElasticSearch와 Kibana를 위한 도커 네트워크를 생성한다. ``` docker network create elastic-net ``` ### ElasticSearch 실행 아래 명령을 실행한다. ```shell docker run -p 127.0.0.1:9200:9200 -d --name elasticsearch --network elastic-net \ -e ELASTIC_PASSWORD=$ELASTIC_PASSWORD \ -e "discovery.type=single-node" \ -e "xpack.security.http.ssl.enabled=false" \ -e "xpack.license.self_generated.type=trial" \ docker.elastic.co/elasticsearch/elasticsearch:8.15.1 ``` curl로 잘 실행됐는지 테스트해보자. ``` curl -u elastic:$ELASTIC_PASSWORD localhost:9200 { "name" : "c143ca2968ec", "cluster_name" : "docker-cluster", "cluster_uuid" : "2ObZ0s48QtuM-Jzik-lBOA", "version" : { "number" : "8.15.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "253e8544a65ad44581194068936f2a5d57c2c051", "build_date" : "2024-09-02T22:04:47.310170297Z", "build_snapshot" : false, "lucene_version" : "9.11.1", "minimum_wire_compatibility_version" : "7.17.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "You Know, for Search" } ``` # Kibana 설치 Kibana는 Elastic Stack의 시각화 도구로 Elasticsearch에서 수집된 데이터를 탐색, 분석, 모니터링 할 수 있다. 로그나 성능 데이터를 대시보드 형식으로 시각화하고 실시간으로 모니터링 하며 검색 및 필터링을 통해 다양한 분석 작업을 할 수 있다. Kibana를 설치하기 전에 반드시 Elasticsearch 컨테이너에 **kibana_sytem** 패스워드를 설정해야 한다. ```shell curl -u elastic:$ELASTIC_PASSWORD \ -X POST \ http://localhost:9200/_security/user/kibana_system/_password \ -d '{"password":"'"$KIBANA_PASSWORD"'"}' \ -H 'Content-Type: application/json' ``` Kibana 컨테이너를 실행한다. ``` docker run -p 127.0.0.1:5601:5601 -d --name kibana --network elastic-net \ -e ELASTICSEARCH_URL=http://elasticsearch:9200 \ -e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \ -e ELASTICSEARCH_USERNAME=kibana_system \ -e ELASTICSEARCH_PASSWORD=$KIBANA_PASSWORD \ -e "xpack.security.enabled=false" \ -e "xpack.license.self_generated.type=trial" \ docker.elastic.co/kibana/kibana:8.15.1 ``` ### Kibana 로그인  기본 유저는 elastic이다. 그리고 앞서 설정한 kibana 패스워드로 로그인한다. # Index 테스트 Kibana를 이용해서 JSON 데이터를 색인하고 검색해보자. Elasticsearch API를 이용해서 색인을 자동화 해야 겠으나 여기에서는 **kibana dev tools** 를 이용해서 빠르게 테스트해보려 한다. ### Kibana Dev Tools Kibana에 로그인 한 후 왼쪽 메뉴에서 **Dev Tools**를 찾아서 클릭한다. 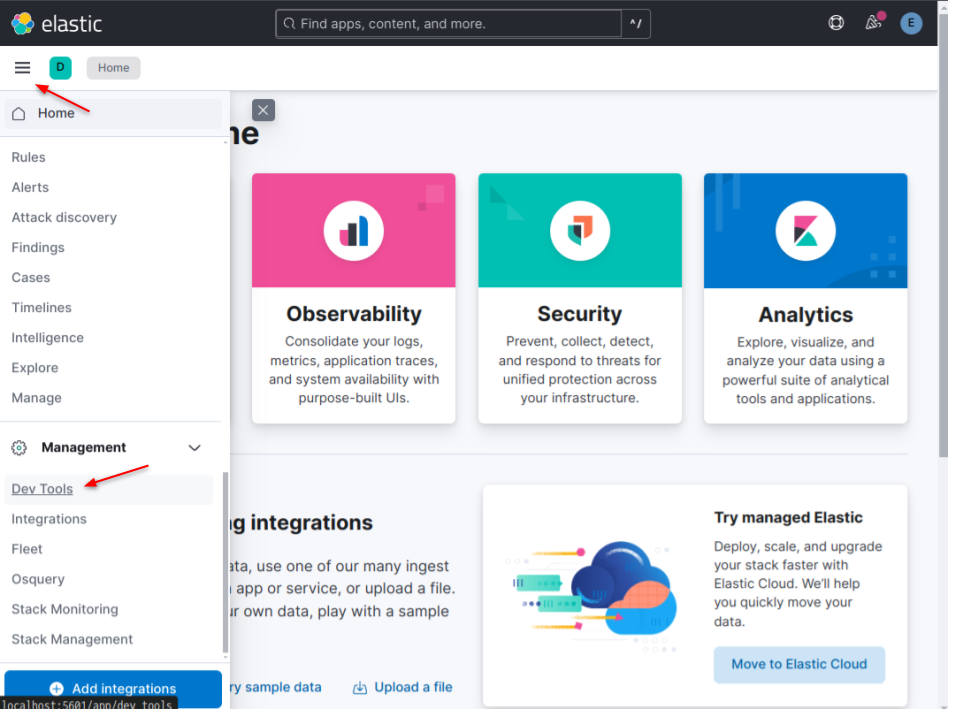 그러면 아래와 같이 API를 실행 할 수 있는 Console 창이 나타난다. Python Notebook 처럼 명령을 입력하고 실행 버튼을 클릭해서 바로 명령을 실행 할 수 있다. 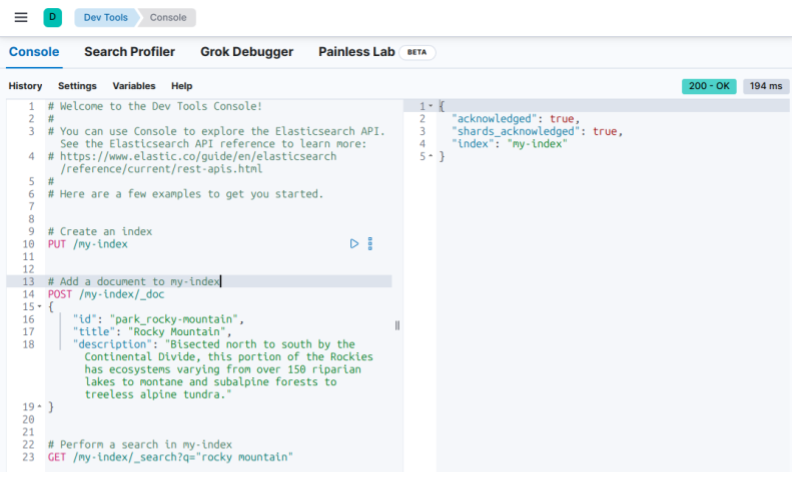 ### 인덱스 생성 관계형 데이터베이스(RDBMS)는 "테이블"에 데이터를 저장한다. Elasticsearch에서는 **인덱스(index)** 에 데이터를 저장하는데, 관계형 데이터베이스의 테이블이라고 보면 된다. 관계형 데이터베이스에서 테이블은 행(row)과 열(column으로 구성되는데), Elasticsearch는 document가 이를 대신한다. * 관계형 데이터베이스의 테이블 = Elasticsearch의 Index * 테이블의 행 = elasticsearch의 document * 테이블의 열 = elasticsearch의 field Dev console에서 **PUT**으로 account-index 를 만들어보자. ``` PUT /account-index ``` 생성된 인덱스는 "왼쪽메뉴 > Management > Stack Management" 로 Management로 접속한 다음 "Data > Index Management"에서 확인 할 수 있다. 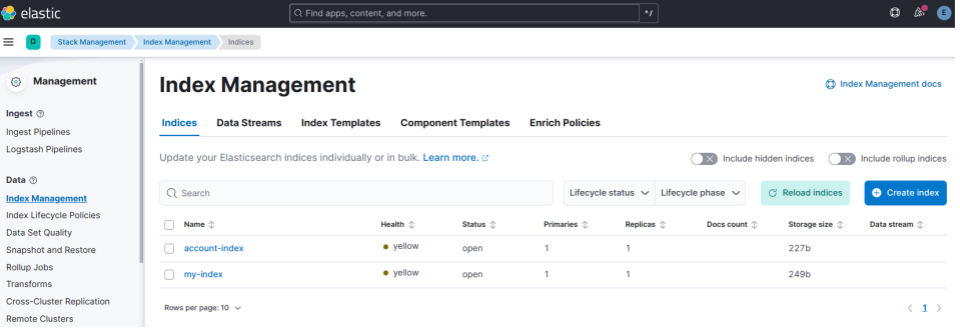 ### Document 색인 문서(Document)를 account-index에 색인 해보자. Elasticsearch도 데이터베이스 이므로 **schema** 와 같은 개념을 가지고 있다. Elasticsearch에서는 매핑(mapping)이 인덱스 내의 문서 구조를 정의하는 역할을 한다. 즉 문서에 어떤 필드가 있으며, 각 필드의 데이터 타입(예: 문자열, 숫자, 날자 등)이 무엇인지를 명시한다. 대부분의 문서기반 데이터베이스들이 그렇듯이 Elasticsearch도 매핑을 만들지 않아도 된다. 명시적으로 매핑을 설정하지 않으면, Elasticsearch는 동적 매핑(dynamic mapping)기능을 사용하여 자동을 매핑을 생성한다. 하지만 자동으로 설정된 필드 타입은 원하는 타입과 다를 수 있다. 예를 들어 특정 문자열 필드를 **keyword** 로 처리해야 하는데 자동으로 **text** 로 설정될 수 있다. 우리가 만든 account-index 색인을 위한 매핑을 만들어볼 생각이다. 맵핑을 만들려면 색인할 데이터의 데이터를 알아야 한다. 아래와 같은 json 데이터를 저장하려 한다. ```json { "account_number" : 952, "address" : "659 Reeve Place", "age" : 33, "balance" : 21430, "city" : "Turpin", "email" : "angeliqueweeks@exodoc.com", "employer" : "Exodoc", "firstname" : "Angelique", "gender" : "M", "lastname" : "Weeks", "state" : "MD" } ``` 위 json 데이터를 저장하기 위해서 아래와 같은 매핑을 만들었다. dev console에서 실행하자. ```json PUT /account-index { "mappings": { "properties": { "account_number": { "type": "integer" }, "address": { "type": "text" }, "age": { "type": "integer" }, "balance": { "type": "integer" }, "city": { "type": "keyword" }, "email": { "type": "keyword" }, "employer": { "type": "keyword" }, "firstname": { "type": "text" }, "gender": { "type": "keyword" }, "lastname": { "type": "text" }, "state": { "type": "keyword" } } } } ``` * account_number, age, balance는 숫자이므로 **integer**로 지정한다. * address, firstname, lastname는 **text**로 지정한다. * city, email, employer, gender, state는 주로 고유한 값을 사용하므로 **keyword**로 설정해서 빠르게 검색할 수 있도록 했다. 데이터베이스도 테이블을 만들 때 스키마를 설정하는 것처럼, Elasticsearch로 인덱스를 만들 때 맵핑을 생성한다. 처음 account-index를 생성하면서 매핑을 설정하지 않아씩 때문에 지금은 동적 맵핑 상태다. 이 경우 새로운 인덱스를 만들거나 account-index를 삭제하고 다시 만들어야 한다. **Index Management** 에서 account-index를 삭제하고 인덱스를 새로 만들자. GET /index_name/\_mapping API로 맵핑정보를 확인 할 수 있다. dev console에서 매핑 정보를 확인해보자.  예제 데이터를 색인해보자. POST /index_name/\_doc API로 색인 할 수 있다. ```json POST /account-index/_doc { "account_number" : 952, "address" : "659 Reeve Place", "age" : 33, "balance" : 21430, "city" : "Turpin", "email" : "angeliqueweeks@exodoc.com", "employer" : "Exodoc", "firstname" : "Angelique", "gender" : "M", "lastname" : "Weeks", "state" : "MD" } ``` GET /index_name/\_search API로 문서를 검색할 수 있다. ```json GET /account-index/_search { "query": { "match": { "city": "Turpin" } } } ``` 검색결과는 대략 아래와 같다. ```json { "took": 0, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 0.2876821, "hits": [ { "_index": "account-index", "_id": "ZCajCpIBGe3c2K7rdfrp", "_score": 0.2876821, "_source": { "account_number": 952, "address": "659 Reeve Place", "age": 33, "balance": 21430, "city": "Turpin", "email": "angeliqueweeks@exodoc.com", "employer": "Exodoc", "firstname": "Angelique", "gender": "M", "lastname": "Weeks", "state": "MD" } } ] } } ```
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
Elasticsearch
search
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags