Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
AWS Well-Architected Framework
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2022-12-01
2022-11-24
2899
### 목적 AWS Well Architected Framework는 좋은 아키텍처를 만들기 위한 길잡이 역할을 한다. 방대한 내용을 담고 있지만 전체 문서를 가로지르는 핵심은 한 문장으로 정리 할 수 있다. > 측정할 수 없다면 관리할 수 없고 관리할 수 없으면 개선할 수 없다. 이 문서는 Well Architected framework를 지탱하는 6개 Pillars(기둥 혹은 원칙)을 다룰 것이다. 이 6개 Pillars는 "측정"에서 시작한다. ### 좋은 아키텍처를 가져가기 위해서는 좋은 아키텍처를 만들기 위한 3가지 수행활동들이다. 1. 전략과 모범사례 연구 : 바퀴를 재 발명할 필요는 없다. 지금 클라우드는 전 세계 모든 산업에서 활발히 사용되고 있으며, AWS는 이런 사용 사례를 기반으로 각 산업/도메인별 모범사례, 레퍼런스 아키텍처들을 제공하고 있다. 이들 문서에서 부터 시작하자. AWS Well Architect 문서를 출발점으로 삼아보자. 2. 아키텍처의 측정 : 모범사례는 참조목으로 사용 할 수 있는 일반화된 가이드일 뿐이다. 물론 훌륭한 가이드이기는 하지만, 100개의 비즈니스는 100개의 모습을 하고 있기 때문에 지금 우리가 구축하려는 비즈니스의 요구사항에 맞게 아키텍처를 측정해야 한다. 3. 문제점 해결 : 비즈니스 가치를 구축하기 위해서는 성능, 보안, 기능, 비용, 시간 등 여러가지 문제점을 해결해야 한다. 좋은 아키텍처는 이들 요구사항들을 절충(trade-off)해서 최적의 솔류션을 제안해야 한다. 시간(빠르게 시장에 출시해야 한다면)이 높은 우선순위를 가진다면, EKS(kubernetes)가 아닌 ECS를 선택해야 할 수 있다. 연구와 개발에 많은 시간이 걸리는 NoSQL(DynamoDB, DocumentDB 등)를 사용하는 대신에, 익숙한 RDS(MySQL)을 선택해야 할 수 있다. 이렇게 타협을 하면서 동시에 REDIS(ElastiCache)등을 제안하여 시간과 성능을 담는 아키텍처를 만들 수 있어야 한다. > 컴포넌트가 아닌 시스템을 최적화하라. [](https://www.youtube.com/watch?v=KWB5FYALvH0) ### Well-Archited 의 목적 1. 정보 기반의 결정. : 측정이 힘든 모든 것을 측정가능하도록 만들어야 하며, 가능한 모든 데이터를 수집해야 한다. 다행히 혼자 이런일을 할 필요가 없다. CSP(Cloud Service Provider - AWS 같은)와 MSP의 도움을 받을 수 있다. 이들로 부터 모범 사례에 기반한 데이터를 수집해서 결정하자. 2. Cloud native 하게 생각하기 : Cloud는 온-프레미스와 다르다. 확장성, 유연성, 복원력, 프로그래밍 가능성, 재무관리 등 여러 영역에서 기존과는 다른 방식으로 접근해야 한다. 3. 잠재적인 영향을 이해. ### AWS Well-Architected Framework 워크로드란 비즈니스 또는 운영가치를 제공하기 위해서 AWS에서 실행되는 관련된 애플리케이션, 인프라, 정책, 거버넌스 및 작업의 모음이다. 이 문서를 읽음으로써 아래의 것들을 얻을 수 있다. * 설계 모범사례에대한 인식을 높인다. * 종종 무시되는 기본 영역들에 대한 준비. * 워크로드 아키텍처를 평가하기 위한 일관된 접근.  AWS Well-Architected Framework 는 Questions, Pillars, Design Principles로 이루어진다. * Pillars : 소프트웨어 시스템을 만드는 것은 건물을 짓는 것과 비슷하다. Pillars는 견고한 소프트웨어 시스템을 위한 6가지의 주요 요소(기능 - Pillars)들을 의미한다. * Design Principles : 6개의 pillars(운영 우수성, 보안, 안정성, 성능 효율성, 비용 최적화, 지속 가능성)를 달성하기 위한 설계원칙들이다. * Question : 6개의 Pillars를 세우기 위해서는 각 조직과 프러덕트를 평가할 수 있는 정보가 필요하다. Question은 평가 및 의사결정을 도와줄 주요 질문들을 포함하고 있다. ## 디자인 원칙 > 좋은 의도만으로는 부족합니다. 무언가를 해내려면 좋은 메커니즘이 필요한 법이죠 - Jeff Bezos. 전통적인 환경에서의 디자인 원칙과 AWS 클라우드에서의 디자인 원칙에는 차이가 있을 수 있다. 왜냐하면 AWS 클라우드에서는 전통적인 환경에서 달성하기 어려웠던 디자인 원칙을 쉽게(그리고 빠르게-거의 실시간으로) 달성할 수 있기 때문이다. 전통적인 환경에서는 아래와 같은 어려움이 있다. * 인프라 담당자는 High-Level의 비즈니스 요구사항으로 부터 인프라를 설계해야 했다. High-Level이라는 것은 대략적인 청사진을 의미하는 것이기 때문에 인프라 담당자는 직감과 추측에 기대어서 대략적인 인프라의 모습, 용량, 비용, 구축 기간등을 산정해야 했다. * 물리적인 인프라의 구축에는 많은 시간과 비용이 들어간다. 그리고 한번 비용을 내고 지불한 장비는 처리 할 수 있는 방법이 없다. 따라서 대규모 테스트를 수행하기 어렵다. * 물리적 공간과 장비를 기반으로 설계를 해야하기 때문에 한번 수립된 설계를 되돌리는 것은 매우 어렵다. 따라서 인프라 담당자는 실패하기 어려운 보수적인 설계를 해야 한다. * 리소스를 확보하는데 많은 시간과 노력이 들기 때문에 개념증명, 실험, 테스트가 힘들다. 어찌어찌해서 리소스를 확보했다고 하더라도 메뉴얼하게 시스템을 구축해야 했기 때문에 재연하기가 어렵다. * 물리적인 공간과 장비에 의존성이 걸리기 때문에, 한번 구축한 설계를 변경하는게 쉽지 않다. 시간이 지나면서 녹쓴 설계가 되며, 기술부채가 쌓이게 된다. 어느 시점에서는 시장의 요구사항에 대응하기 힘든 설계가 반영된 시스템으로 남게 된다. 소위 말하는 레거시이며, 주기적으로 고도화 작업이라는 것을 하게 된다. (금융 시스템에서는 차세대 프로젝트라는 방식으로 실행된다.) AWS 클라우드는 위의 문제점을 해결 할 수 있다. * AWS 클라우드는 사용한 기간만큼만 비용을 지불하면 된다. 리소스도 소프트웨어 방식으로 즉시(거의 실시간으로) 사용 혹은 중지가 가능하기 때문에, **용량을 추측할 필요가 없다**. * 상용과 동일한 규모로 테스트 환경을 만들 수 있다. * 실험환경을 쉽게 구성할 수 있다. 탐색과 실험, 테스트는 혁신을 위한 중요한 요소들이다. * 물리적인 환경에 비해서 유연하게 구조를 변경 할 수 있기 때문에, 비즈니스 목표와 시장변화에 대응 할 수 있는 **진화하는 아키텍처**가 가능하다. * 데이터 기반(Data-Driven) 아키텍처를 수행 할 수 있다. AWS 클라우드는 데이터 수집, 분석에서 ML, AI 까지 다양한 데이터 서비스를 제공하고 있다. 이러한 데이터 서비스는 인프라와 강력하게 통합되어 있으므로 기본 서비스 아키텍처를 데이터 기반 아키텍처로 확장 할 수 있다.  ### 클라우드 일반 설계 원칙 앞서 클라우드 환경이 기존 환경과 다르다는 점을 간단하게 설명했다. Well-Architected Framework 에서 제안하는 일반 설계원칙을 알아보자. **필요 용량에 대한 추측이 필요없다.** : 워크로드를 배포할 때 용량을 잘못 설정하면 리소스를 낭비하거나 제한된 용량으로 인해서 충분한 성능을 제공하지 못하는 문제를 처리해야 한다. 클라우드 환경에서는 필요한 만큼의 용량을 즉시 확장 혹은 축소할 수 있기 때문에 이러한 문제에서 자유롭다. **프로덕션 규모에서 테스트 할 수 있다.** : 클라우드는 프로덕션과 동일한 규모로 테스트 환경을 만들고 테스트 한다음 해당 리소스를 폐기 할 수 있다. 테스트 환경을 실행하는 동안에만 비용을 지불하기 때문에, 온프레미스의 몇 분의 1에 불과한 비용으로 실제 환경을 시뮬레이션 할 수 있다. **자동화를 통해서 간단하게 아키텍처를 실험 할 수 있다.** : 자동화를 통해 수작업 없이 빠르게 워크로드를 생성하고 복제할 수 있다. Terraform, Pulumi 와 같은 IaC 도구를 사용하면 인프라를 코드화 하여서 변경 사항을 추적하고 그 효과를 감시하고 이전 상태로 복원하는 작업을 할 수 있다. **아키텍터의 지속적인 혁신** : 클라우드는 온디멘드 방식의 자동화 및 테스트 기능을 가지고 있어서 설계 변경에 따른 위험이 줄어든다. 따라서 시간이 지날수록 시스템은 진화하고, 기업은 혁신을 표준 사례로 활용 할 수있다. **실전 테스트를 통한 개선** : 프로덕션 환경과 동일한 환경에서 이벤트를 시뮬레이션 할 수 있다. 이러한 실전 테스트를 정기적으로 실시하여 아키텍처와 프로세스가 어떻게 작동하는지 테스트 할 수 있다. 그러면 어느 분야에서 개선이 필요한지 파악하고 조직이 이벤트에 대처하는 경허을 쌓도록 도울 수 있다. ## Pillars AWS Well-Architected Framework는 6개의 Pillars(원칙)로 구성된다. | Pillar | 설명 | | ------- | ------ | | 운영 우수성 | 효과적인 개발 및 워크로드 실행을 지원하고, 작업에 대한 인사이트를 얻고, 지원 프로세스 및 절차를 지속적으로 개선하여 비즈니스 가치를 제공할 수 있는 능력. | 보안 | 보안 원칙에는 클라우드 기술을 활용하여 보안을 강화하고 데이터, 시스템 및 자산을 보호하는 능력. | 안정성 | 필요할 때 의도한 기능을 정확하고 일관되게 수행하는 워크로드의 기능이다. 여기에는 전체 수명 주기에 걸쳐 워크로드를 운영 및 테스트할 수 있는 기능이 포함됩니다. 이 백서는 AWS에서 안정적인 워크로드를 구현하기 위한 세부적인 모범 사례 지침을 제공한다. | 성능 효율성 | 컴퓨팅 리소스를 시스템 요구 사항에 맞게 효율적으로 사용하고, 수요 변화 및 기술 변화에 따라 이러한 효율성을 유지하는 기능을 포함한다. | 비용최적화 | 시스템을 실행하여 최저 가격으로 비즈니스 가치를 제공할 수 있는 기능을 포함한다. | | 지속가능성 | 프로비저닝된 리소스의 이점을 극대화하고 필요한 총 리소스를 최소화하여 워크로드의 모든 구성 요소에서 에너지 소비를 줄이고 효율성을 높임으로써 지속 가능성에 미치는 영향을 지속적으로 개선할 수 있다. |  소프트웨어 시스템을 제작하는 것은 건물을 짓는 것과 매우 비슷하다. 토대(pillars - 기둥)가 단단하지 않으면 구조적 문제가 발생하여 건물의 기능이 약해지는 것은 물론 건물 자체가 무너질 수 있다. 기술 솔루션을 설계할 때 **운영 우수성, 보안, 안정성, 성능 효율성, 비용 최적화 및 지속 가능성**이라는 여섯 가지 기반 원칙을 간과하면 기대 및 요구에 충실한 시스템을 구축하기가 어려울 수 있다. 이러한 기반 원칙을 아키텍처에 통합하면 안정적이고 효율적인 시스템을 구축하는 데 도움이 된다. 또한 이를 바탕으로 기능적 요구 사항 등 설계의 다른 측면에 집중할 수 있다. ### 운영 우수성(Operational Excellence) 시스템의 목적은 비즈니스 가치를 제공하는 것이다. 운영 우수성은 시스템의 실행하고 운영하고 모니터링하여서 지원 프로세스와 절차를 지속적으로 개선하는 것을 의미한다. 이를 통하여 비즈니스 가치를 효과적으로 제공 할 수 있게 된다. #### 설계원칙 AWS 클라우드는 운영 우수성에 대한 5개의 설계 원칙이 있다. * 코드를 통한 운영 : 애플리케이션과 인프라를 포함하는 전체 워크로드를 코드로 정의하는 것이다. Terraform, CloudFormation, pulumi 등을 이용해서 달성 할 수 있다. IaC(Infrastructure as a Code)로 잘 알려져 있다. * 점진적인 업데이트 : 점진적으로 업데이트될 수 있도록 워크로드를 설계하고, 실패하더라도 쉽게 되돌릴 수 있도록 증분기반으로 변경 내용을 적용한다. * 운영 절차를 수시로 점검한다. : 운영 절차가 개선여지가 있는지 확인한다. 워크로드가 개선되면 절차도 적절하게 개선한다. * 실패 예측 : 사전 분석을 수행하여 잠재적인 실패요소를 식별하고 이를 해소하거나 완화할 수 있도록 한다. * 모든 실패로부터 학습 : 운영 이벤트와 실패로부터 파악한 내용을 기록하고, 개선한다. #### 정의 AWS 는 운영 우수성을 달성하기 위한 4개 영역의 모범사례를 제안하고 있다. **조직(Organization)** : 기획팀, 개발팀, 운영팀, 보안팀 등의 주요 관계자와 함께 내부및 외부 고객의 요구사항을 평가하고 우선순위를 설정해서 주력할 영역을 결정한다. 고객의 요구사항을 평가하면 비즈니스 성과를 달성하기 위해서 어떤 지원이 필요한지 파악 할 수 있다. 또한 비즈니스에 대한 위협요소 즉, 비즈니스상의 위험 및 법적 책임, 정보보안 위협을 평가하고 위험 목록을 작성해서 이를 관리한다. 보안은 다른 이해 관계 당사자와 상충관계에 있을 수 있으므로, 여러 대안 사이의 장단점을 평가 할 수 있어야 한다. 예를들어 출시시기가 중요하다면, 비용을 최적화 하는대신에 출시를 앞당기기 위해서 작업을 간소화 할 수 있는(그렇지만 상대적으로 비싼) 솔류션을 선택해야 할 수 있다. 출시시기가 중요하다면, 일부 보안 위협을 감수해야 할 수 있는데 이를 위한 조치를 취해야 한다. 어떤 프로젝트를 진행 할 때는 혁신성과 안정성 두가지 측면에서 조직의 균형을 맞춰야 한다. 안정성이라면 실패할 가능성이 적은 조직 구성안이 될 것이다. **역할과 책임을 명확히 하라**는 고전적인 조직 구성안에 충실하면, 실패 가능성을 크게 낮출 수 있을 것이다. 애플리케이션, 워크로드, 플랫폼 및 인프라 마다 소유자를 명시하고 각 프로세스와 절차를 정의하고 실행할 담당자를 명시한다. 각 구성요소에 대한 소유권을 명확히하면 팀원이 무슨일을 하는지 알 수 있다. 하지만 이렇게 해서는 혁신에 제약이 생길 수 있을 것이다. 따라서 혁신을 가로막지 않도록 추가, 변경, 예외를 요청하는 메커니즘을 마련해야 한다. 실험을 권장하여 학습을 가속화하여 팀원의 관심과 참여 동기를 유지한다. 햑습을 위한 전용 시간을 제공하는 것은 좋은 방법이 될 것이다. 팀원이 비즈니스와 개인의 성장을 지원하기 위해서 필요한 도구들이 충분히 확보되었는지를 확인해야 한다. **준비(Prepare)** : 운영 우수성 달성을 위해서 우리는 역할과 책임에 기반한 조직을 설정했다. 또한 비즈니스와 개인의 성장, 혁신을 도모하기 위한 메커니즘도 마련했다. 이제 운영 우수성을 달성하기 위한 실질적인 활동이 필요하다. 운영을 준비함에 있어서 가장 중요한 것은 **데이터**이다. 문제를 관찰하고 조사할 수 있도록 모든 구성요소에서 지표, 로그, 이벤트 등 필요한 정보를 제공하도록 워크로드를 설계해야 한다. 또한 상태변경, 사용자 활동, 액세스(권한을 가지고 있는지), 사용율등의 광범위한 데이터를 캡춰해야 한다. AWS의 워크로드를 코드(IaC)로 준비 할 경우 많은 이점을 얻을 수 있다. 애플리케이션 코드를 개발하는 것과 동일하게 워크로드를 코드화하고, 조직간에 공유하고 업데이트 함으로써 운영 절차 및 실패 사례를 코드에 반영할 수 있다. 효과적인 준비를 위해서 아래의 질문사항에 답할 수 있어야 한다. * 운영 상태를 파악할 수 있도록 워크로드를 설계했는가 ? * 결함을 줄이고 쉽게 수정하고, 프로덕션 환경으로 이루어지는 프로세스를 가지고 있는가 ? * 배포위험을 취소화하기 위한 정책/시스템을 가지고 있는가 ? * 서비스 운영을 지원할 준비가 되었는지 어떻게 확인 할 수 있는가 ? **운영(Operate)** : 고객, 비즈니스 담당자, 개발자, 운영에 맞는 알림 및 대시보드를 통해 워크로드 운영 상태를 전달하여 적절한 조치를 취하고 정상 운영이 시작될때 알림을 받을 수 있도록 한다. AWS의 CloudWatch, OpenSearch, CloudTrail, Prometheus, AWS X-Ray 혹은 타사의 애플리케이션을 활용하여 정보를 수집하고 가시성을 확보 할 수 있다. 운영 우수성을 달성하기 위한 중요한 질문은 아래와 같다. * 워크로드가 정상인지 어떻게 판단하는가 ? * 운영 업무가 정상인지 어떻게 판단하는가 ? * 서비스/운영 이벤트를 어떻게 관리하는가 ? **개선(Evolve)** 운영 우수성을 유지하려면 학습하고, 실패로부터 배우고 지속적으로 개선해야 한다. 이러한 과정은 연속적이고 증분적이어야 한다. 고객에게 영향을 미치는 모든 이벤트들을 수집하고 사후 분석을 수행해야 한다. 또한 재발 방지를 위한 필요한 조치를 수행해야 한다. 워크로드 및 운영 절차 모두를 포함하여 "기능", "문제 해결", "규정 준수 요구사항" 등을 정기적으로 평가하고 우선순위를 조정해야 한다. Sprint와 같은 활동은 개발팀 뿐만 아니라 DevOps(인프라 관리팀)에도 많은 도움이 될 수 있다. Sprint를 통해서 평가 항목을 조정하고, 데이터를 수집하고 분석하고 우선순위에 기반하여 Task를 만들고 수행하는 것을 권장한다. 개선을 위해서는 데이터가 있어야 한다. AWS에서 발생하는 모든 데이터는 Cloudwatch를 통해서 S3에 저장할 수 있다. S3를 기반으로 Data Lake를 구성하고 AWS Glue를 사용하여 분석할 수 있는 환경을 구축하자. 개선단계에서 중요한 질문은 아래와 같다. * 어떻게 운영을 개선할 수 있는가 ? ## Security pillar  Security pillar은 정보, 시스템, 자산을 보호하는 동시에 위험을 평가하고 완화 전략을 통해서 비즈니스 가치를 지키는 능력을 의미한다. AWS 클라우드에서 보안은 아래의 5가지 영역으로 구성된다. 1. Identity and access management(자격 증명 및 액세스 관리) 2. Detection(탐지): 3. Infrastructure protection(인프라보호): 4. Data protection(데이터보호) 5. Incident response(사고대응) ## Reliability pillar 안정성 원칙(Reliability pillar)는 워크로드의 기능이 필요할 때에 정확하고 일관되게 수행할 수 있는 역량을 다룬다. 여기에는 전체 수명주기에 걸쳐 워크로드를 운영 및 테스트 할 수 있는 기능이 포함된다. AWS 클라우드는 안정성을 높일 수 있는 몇가지 주요 원리들을 제공한다. * 장애 자동 복구 : 워크로드의 **핵심 성능지표**를 모니터링하고 임계값을 설정 할 수 있다. 임계값을 위반했을 때, 자동적으로 트리거할 작업을 설정 할 수 있다. * 복구 절차 테스트 * 수평적 확장으로 워크로드 전체의 가용성 증대 * 용량추정 불필요. * 변경사항관리의 자동화 ## Performance Efficiency pillar 성능 효율성 원칙(Performance Efficiency pillar)는 컴퓨팅 리소스를 효율적으로 사용하여 시스템 요구 사항을 충족하고 수요 변화 및 기술 발전에 따라 효율성을 유지하는 능력이다. AWS에서 성능 효율성을 달성하기 위해서는 아래의 영역에 집중해야 한다. **선택** : 문제를 해결하는 한 가지 이상의 방법이 있다는 것을 명심하자. 특정 워크로드에 대한 솔류션은 다양하며, 종종 여러 접근방식이 결합된 솔류션을 사용하여 각 특성을 조합하여 성능을 높여야 한다. AWS 솔류션스 아키텍트, AWS 참조 아키텍처, 관련지식을 가지고 있는 AWS 파트너가 이 과정을 도울 수 있다. 선택을 위한 모범 사례는 다음과 같다. 1. 먼저 [사용가능한 서비스와 리소스](https://docs.aws.amazon.com/ko_kr/wellarchitected/latest/performance-efficiency-pillar/perf_performing_architecture_evaluate_resources.html)를 파악한다. 클라우드에서 사용 가능한 방대한 서비스와 리소스를 알아보고 이해하고 있어야 한다. 워크로드와 관련있는 서비스들과 구성 옵션등을 확인하고 성능을 최적화 하는 방법을 파악해야 한다. 2. 다음 [아키텍처를 선택하기 위한 프로세스](https://docs.aws.amazon.com/ko_kr/wellarchitected/latest/performance-efficiency-pillar/perf_performing_architecture_process.html)를 정의 한다. 클라우드에 대한 내부 경험과 지식, 사용 사례, 백서 등을 사용하여 리소스와 서비스를 선택하는 프로세스를 정의한다. 아키텍처에 대한 중요한 사용자 사례를 작성 할 때, 사용자가 요구하는 성능 요구사항도 함께 포함해야 한다. 중요하게 고려해야 할 것은 * 아키텍처는 동적이다. 시간이 지나면서, 시장이 변하면서, 새로운 기술 및 서비스, 아키텍처 방법등이 도입되면서 업데이트(진화) 할 수 있다고 가정해야 한다. * 아키텍처의 변경에는 시간, 비용, 기능, 성능, 운영및 유지보수 등 여러 관점에서 타당한 이유가 있어야 한다. **검토** : 워크로드 설계시 선택할 수 있는 옵션은 한정되어 있다. 우리는 데이터를 기반으로 하여 아래의 사항을 검토하는 **성능 검토 프로세스**를 구현해야 한다. * 인프라의 코드화 * 지속적인 통합배포를 위한 CICD의 구축 * 잘 정의된 지표: KPI를 측정하기 위한 지표와 모니터링을 설정한다. * 자동 성능 테스트 * 부하 테스트 * 성능 측정 * 시각화 **모니터링** : 성능을 최적화하기 위해서는 **기준데이터**가 있어야 한다. 성능 데이터를 수집하고 모니터링을 하며 임계치를 설정하여, 임계치를 초과할 경우 알람이 생성되도록 해야 한다. CloudWatch를 이용해서 인프라 성능 지표와 로그 파일을 수집/모니터링하고 알람을 생성 할 수 있다. 이 모니터링은 5가지 단계로 이루어진다. * 생성 : 모니터링 범위, 지표 및 임계 값 * 집계 : 여러 소스에서 전송되는 모니터링 정보를 확인 할 수 있는 view 생성 * 실시간 처리 및 알람 * 스토리지 : 데이터의 관리 및 보존 정책 * 분석 : 대시보드, 보고 및 분석 정보 파악 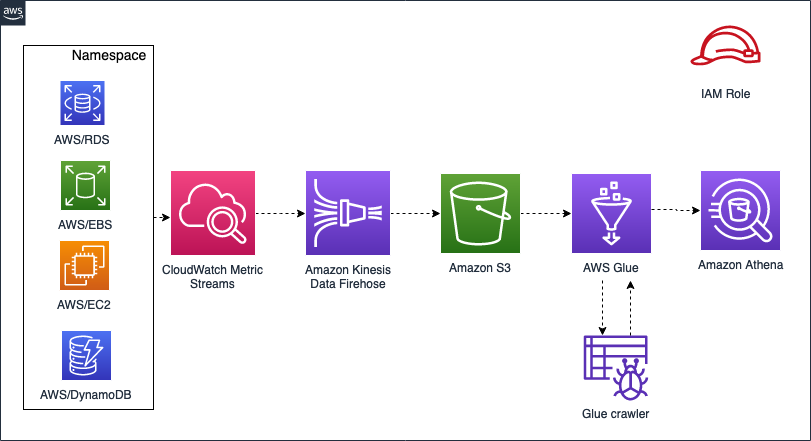 **절충**: AWS를 문제를 해결하기 위한 다양한 서비스 및 리소스를 제공한다. 또한 고객은 비용, 시간, 기능, 품질과 관련하여 여러 제약사항을 가지고 있기 때문에, 최적의 솔류션을 찾을 수 있도록 각 방식의 장단점을 고려해야 한다. 예를 들어 더 나은 성능을 제공하기 위해서 일관성, 내구성, 비용을 희생하고 시간/지연을 우선으로 선택할 수 있다. ## Cost Optimization pillar 낮은 가격으로 비즈니스 요구사항을 달성하는 것을 의미한다. AWS 클라우드는 용량 산정없이 즉시 사용 할 수 있는 장점이 있는데, 이 때문에 비용을 크게 낭비 할 수 있다. 누군가가"AWS 클라우드가 저렴한 줄 알았는데, 그렇지 않지"라고 주장한다면, 둘 중 하나의 이유 때문일 것이다. 1. 비용을 관리하지 않고 리소스를 낭비하고 있다. 2. 자체 데이터 센터를 유지 할 수 있는 공간, 인력이 있어서 굳이 클라우드를 사용 할 필요가 없다. 비용 최적화를 위한 설계원칙은 아래와 같다. **클라우드 재무 관리 구현** : 워크로드를 클라우드에 전개할 경우 가장 먼저해야 할 일은 재무부와 함께 재무 정책을 수립하는 것이다. 전통적인 IT 재무관리는 용량산정, 예산책정, 리소스 구매/대여 계약 방식으로 이루어진다. 클라우드는 사용한 만큼 비용을 지불하기 때문에 재무관리 방식이 달라진다. 따라서 사용량 모니터링/관리를 위한 기능을 구축하는데 시간과 리소스를 할애해야 한다. 또한 비용 효율적인 업무를 위해서 필요한 지식, 프로그램 등을 전파 및 공유 해야 한다. 새로운 정책 환경을 만드는 어려운 작업이 될 수 있는데, MSP에게 도움을 얻는 걸 고려해보자. **전반적인 효율성 측정**: 비즈니스와 전개된 워크로드에 대한 비용을 측정한다. 클라우드는 비용 추적을 위한 기능을 제공하기 때문에, 비용을 얼마나 효율적으로 사용하고 있는지 파악할 수 있다. **획일적 업무 부담에 대한 비용 지출 중단** : 상면을 계약하고 랙과 서버를 쌓아올리고, 장비 테스트, 잔원 공급, 운영체제 설치, 장비 모니터링과 같은 힘든 데이터 운영 작업을 AWS가 처리한다. IT 조직은 IT 인프라 대신에 고객 및 비즈니스 가치의 구현에 집중할 수 있다. **지출 분석** : 클라우드에서는 워크로드의 비용을 어카운트(account), 시스템/네트워크 리소스 단위로 정확하게 식별할 수 있다. 그러므로 조직별, 프로덕트별 비용지출과 수익흐름에 대한 투명한 모니터링이 가능하며, 이를 통한 개선 계획을 수립할 수 있다. ### Cost Optimization을 위한 핵심 솔류션 클라우드는 물리적 인프라를 **소프트웨어 API** 방식으로 제공한다. 리소스와 서비스는 동적이며, 마치 소프트웨어를 개발하듯이 디버깅, 최적화 할 수 있다. 클라우드 관리자는 고정된 자산이 아닌 소프트웨어를 개발/관리하는 느낌으로 비용을 최적화 해야 한다. * 클라우드 재무 관리 시행 * 지출 및 사용량 인식 * 비용 효율적인 리소스 * 수요 관리 및 리소스 공급 * 시간 경과에 따른 최적화 지출 및 사용량 인식의 경우 직접 비용추적 애플리케이션을 개발 할 수 있겠으나 그보다는 MSP의 비용관리 서비스를 사용하는 것을 권장한다. 그다음 가장 중요한 것은 **시간 경과에 따른 최적화** 이다. 워크로드와 클라우드 기술들을 분석하면서, 지출 모니터링 내용을 기반으로 점진적으로 비용을 최적화 한다. 처음 프러덕트를 오픈했을 때는 정확한 용량을 알 수가 없다. CPU, DISK, MEMORY, 트래픽을 모니터링하면서, 정확한 사용량이 예측되면 각 리소스를 다운사이징(downsizing) 하고 워크로드에 맞는 솔류션을 찾아서 개선해 나간다. 예를 들어 가장 많이 사용하는 S3의 경우, 짧은 지연시간이 중요하지 않은 워크로드라면 값비싼 S3 Standard 대신, S3 Glacier 를 사용 할 수 있을 것이다.  ## 참고 * [The 6 Pillars of the AWS Well-Architected Framework ](https://aws.amazon.com/ko/blogs/apn/the-6-pillars-of-the-aws-well-architected-framework/) * [AWS Well-Architected Framework - 질문 및 모범사례](https://docs.aws.amazon.com/ko_kr/wellarchitected/latest/framework/a-organization.html)
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
architecture
aws
cloud
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags