Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
AI / LLM에 대한 친절한 소개
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2024-09-17
2024-09-17
796
# 📚 소개 생성 AI(Generative)와 LLM(Large Language Model - 대규모 언어모델)는 "인공지능"이라는 수식어 때문에 많은 오해가 존재하는 기술이다. 온갖 마케팅 용어, 오해, 환호와 불신, 공포스러운 전문용어 까지 어디에서 시작해서 어떻게 접근해야 하는 두려움을 들게 한다. 이 글은 컴퓨터 공학에 대한 배경 지식이 없는 사람들에게 GPT-3, GPT-4, Bing Chat, Bard, Gemini 등이 어떻게 작동하는지에 대한 정보를 제공하기 위해서 만들어졌다. ChatGPT은 LLM위에 구축된 AI 애플리케이션의 많은 응용 프로그램 중 하나 이다. "성공을 해서" 대중에게 많이 알려졌다 정도의 차이가 있을 것이다. 이 글에서 LLM의 핵심 개념을 설명할 것이다. 여기에 기술적 배경이나 수학적 배경 지식을 요구하지는 않을 것이다. 그리고 핵심 개념이 작동하는 방식과 ChatGPT와 같은 LLM이 할 수 있는 것과 할 수 없는 것, 앞으로 기대 할 수 있는 것들에 대해서 이야기 할 것이다. # 📚 AI와 LLM의 족보 아래 그림은 AI와 LLM의 관계를 묘사하고 있다.  인간과 유사한 학습, 문제 해결 능력을 가지는 AI를 만드는게 궁극의 목표이고, ML은 그 목표를 달성하기 위한 여러 기술 중 하나다. 딥러닝은 인간의 뇌 신경망에서 아이디어를 얻어서 구현한 머신러닝의 한 분야이고, Transformer는 자연어처리를 특히 잘하는 딥러닝 아키텍처(구조)다. 이 Transformer 구조를 기반으로 만들어진 "모델"들이 바로 ChatGPT, Llama3, qwen, Gemini와 같은 대규모 언어 "모델"이다. "모델"은 "실제 시스템이나 현상의 동작을 설명하거나 예측하기 위해서 사용하는 수학적, 통계적인 구조"다. 즉 대규모 언어 모델은 대량의 텍스트(언어)를 DL의 Tranformer 구조로 훈련하여서 "인간의 자연어를 이해하고 출력할 수 있도록 만든 모델"인 것이다. 사용한 데이터, 훈련 방법에 따라서 ChatGPT, Claude 와 같은 다양한 LLMs들이 만들어진 것이다. # 📚 오픈소스 LLM과 독점 LLM 대규모 언어 모델을 훈련하기 위해서 사용한 데이터와 훈련방법의 공개여부에 따라서 오픈소스 LLM과 독점 LLM으로 구분한다. * 독점 LLM * GPT-4: OpenAI * Claude: Anthropic * Bard: Google * Cohere: Cohere * 오픈소스 LLM: 자세한 목록은 [open-llms](https://github.com/eugeneyan/open-llms) 목록 확인 * Bert: Google * LLama2, LLama3: Meta * Falcon * Mistral 7B * Phi-2 # 📚 인공지능이란 ? > 사람이 행동할 경우 합리적으로 지적으로 부를 만한 행동을 수행하는 개체 "지능"이라는 단어를 사용해서 인공지능을 정의하는 것은 오해를 일으킬 수 있는 좋은 단어가 아니다라는 의견에 동의 하기는 하지만 목적하는 바가 무엇인지 쉽게 직관적으로 이해할 수 있기 때문에 괜찮은 단어 선택이라고 생각한다. 예를들어 게임속에 등장하는 NPC 캐릭터의 경우 지능을 가지고 있지 않지만, 합리적으로 행동하는 것처럼 보이면 우리는 그것을 "게임의 인공지능이 괜찮다"라고 말한다. 이러한 대부분의 캐릭터는 if-then-else(예: 플레이어와 직선 상에 있으면 가까운 엄폐물로 이동해서 사격을 하라. 플레이어가 다른 곳을 보고 있으면 자세를 낮추고 조준 사격을 하라.)로 작동하지만, "바보처럼 행동하지 않는다면" 정교하게 행동한다고 생각 할 수 있다. 다시 말하자면 "우리는 무언가가 어떻게 작동하는 지를 이해하게 되면, 그다지 감명 받지 못 할 수 있다는 점"이다. 이 것은 무대 뒤에서 어떤 일이 일어나는지에 대해서 무엇을 알고 있는지에 달려있다. > 즉 인공지능은 마법이아니며, 마법이 아니기 때문에 설명이 가능하다는 것이다. # 📚 머신러닝이란 ?  인공지능과 관련하여 자주 듣게 될 또 다른 용어는 **머신러닝** 이다. > 데이터를 수집하여 모델을 만든 다음 모델을 실행하여 행동을 하도록 하는 수단이다. 언어와 같은 복잡한 현상은 if-then-else로 만드는 것이 너무 어렵다. 이 경우, 우리는 **많은 데이터**로 부터 언어의 패턴을 찾아서 이를 모델링 할 수 있는 알고리즘을 사용한다. 모델은 복잡한 현상을 단순화 한 것이다. 예를 들어 모델 자동차는 실제 자동차의 작고 단순한 버전이다. 실제 자동차는 매우 많은 속성을 가지고 있지만, 모델 자동차는 핵심 속성을 제외한 많은 속성을 포기한다. 즉 원래 자동차를 완전히 대체 할 수 없다. 하지만 우리는 그것을 특정 목적에 유용하게 사용 할 수 있다. 자동차의 단순한 버전을 만들 수 있는 것처럼, 우리는 인간언어를 구사하는 더 작고 단순한 버전을 만들 수 있다. 이것을 우리는 **대규모 언어 모델** 이라고 한다. 자동차 모델의 경우 세부속성을 더 많이 자세히 구현할 수록 더 자동차처럼 움직일 것이다. 대규모 언어 모델도 더 많은 세부속성을 가질 수록 더 인간언어를 잘 이해하고 대화 할 수 있다. GPT-3.5 GPT-4와 같은 프로덕션에서 사용하는 가장 큰 모델들은 데이터 센터에서 실행되는 거대한 슈퍼 컴퓨터가 필요하다. 반면 개인 PC에서 실행 할 수 있는 모델들도 있다. # 📚 신경망(Neural Network) 이란? 데이터에서 모델을 학습하는 여러 가지 방법이 있다. 신경망은 그러한 방법 들 중 하나다. 인간의 뇌는 뉴런으로 상호 연결되어서 전기신호를 주고 받는 뇌 세포 네트워크를 기반으로 작동을 한다. 인간은 이러한 뇌 구조를 바탕으로 세상을 이해하고 사고, 추론, 행동을 할 수 있다. "인간의 이러한 뇌 구조를 모방해서 인간처럼 사고하는 컴퓨터를 만들 수 있지 않을까?" 라는 아이디어에서 출발한게 "신경망(Neural Network)"이다. 신경망의 기본 개념은 1940년에 발명되었으며, 훈련방법에 대한 개념은 1980년에 발명되었다. 하지만 대규모로 사용이 가능하게 된 시점은 2017년 경으로 보고 있다. 인간의 신경망이든 컴퓨터로 구현하는 신경망이든 결국은 전기의 흐름이라서 전기회로로 비유하면 신경망을 좀 더 쉽게 이해할 수 있다. 전기회로라는 것은 전기가 쉽게 흐르거나 혹은 흐를 수 없도록 스위치를 구성하는 것이라는 것을 알 수 있다. 고속도로를 주행하는 자율 주행차를 만든다고 상상해보자. 이 차량은 충돌방지를 위해서 차량의 앞, 뒤, 측면에 근접 센서를 장착하고 있다. 이 센서는 가까이에 물체가 접근하면 1.0을 근처에 아무것도 없으면 0.0의 값을 보고 한다. 또한 브레이크와 가속 페발을 밟을 수 있는 장치를 만들었다. 가속 페달이 1.0의 값을 받으면 최대 가속이고 0이면 가속이 없는 상태다. 브레이크도 1.0이면 브레이크를 밟고 0이면 밟지 않는다. 스티어링은 -1.0 에서 1.0의 값을 가지며 음수이면 좌회저, 0은 직진 양수면 우회전이다. 이제 센서 데이터를 기반으로 운전하게 하면 된다. 앞 도로에 장애물이 없으면 가속하고 차가 있으면 속도를 줄인다. 왼쪽에 차가 가깝다면 오른쪽으로 방향을 틀어서 차선을 바꾼다. 사람은 할 수 있는 작업이고 그 과정도 글로 쉽게 묘사할 수 있지만 다양한 센서의 정보를 조합하여 다양한 동작이 조합되는 복잡한 프로세스다. 이 센서를 자동 주행 장치에 연결하려면 어떻게 해야 할까 ? 여기에서는 정답을 말하지는 않을 것이다. 간단히 보자면 모든 센서를 자동 주행 장치에 연결하면 된다. 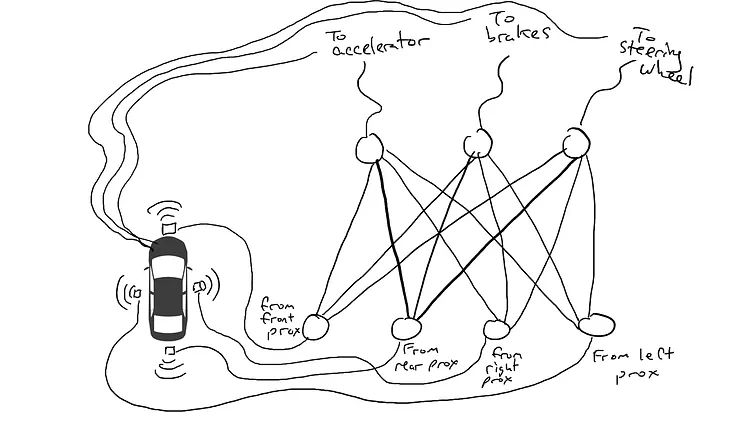 운행을 하게 되면 어떤일이 발생할까. 전류가 모든 센서에서 주행장치로 흐르고 차는 동시에 좌회전, 우회전, 가속, 제동을 하게 될 것이다. 엉망진창이 될 것이다.  << 특정 센서에 정보가 감지되면 모든 회로로 전기가 흐른다 >> 이렇게 해서는 안된다. 그래서 특정 상황에서 전기가 더 잘 흐를 수 있도록 하는 **저항기**를 설치했다. 예를 들어, 전면 근접 센서가 작동을 하면 전기는 브레이크로 더 잘 흐르도록 하고 스티어링 휠로는 흐르지 않도록 할 수 있다. 또 게이트를 설치해서 충분한 전기가 축적될 때까지 전기 흐름을 멈추게 하거나, 입력 강도가 낮을 때 전기를 흐르도록 했다.(예. 전면 근접 센서가 낮은 값을 보고할 때 가속 페달에 더 많은 전기를 보낸다) 차량을 잘 제어하기 위해서는 **저항**과 **게이트**를 둬서 전기신호를 제어 해야 할 것이다. 저항과 게이트를 두고 무작위로 배치를 하고 테스트를 하면서 최적의 조합을 찾는 것이다. 충분한 테스트를 하고 아래와 같이 배치를 했을 때 잘 작동한다는 것을 발견하게 됐다. 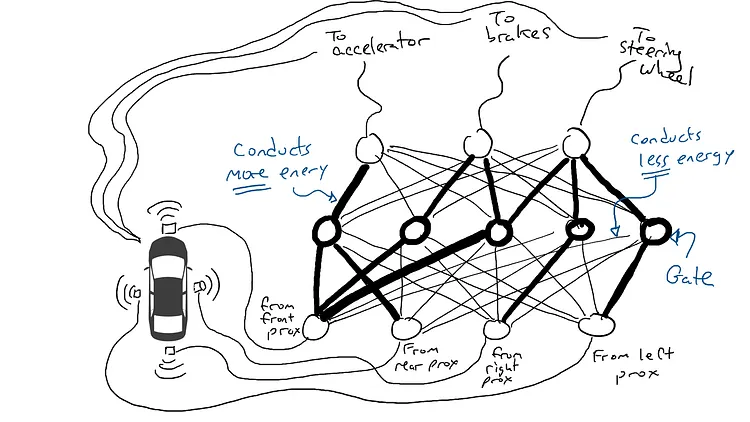 << 완전히 훈련된 신경망, 굵은 선은 에너지가 더 자유롭게 흐르는 회로를 의미한다. 가운데 원은 에너지를 위로 보내기 전에 에너지를 축적하거나 혹은 아래에서 에너지가 거의 없을 때 에너지를 위로 보내는 게이트 역할을 한다. >> 인간의 뇌에서도 이러한 메커니즘이 작동한다. 뉴런은 전기 신호를 시냅스를 통해서 다른 뉴런으로 전달한다. 이 과정을 **신경 전달** 이라고 한다. 뉴런은 수천 개의 다른 뉴런과 연결이 되는데, 모든 뉴런과 동일한 강도로 연결되는 것이 아니다. 학습(운동, 공부, 경험)등에 의해서 시냅스가 강화 되거나 약화될 수 있다. 즉 전기가 잘 흐르는 경로와 그렇지 않은 경로가 만들어 지는 것이다. * 시냅스 강화: 시냅스의 전기적 연결 강도가 증가하여 신호 전달이 더 효율적으로 이루어진다. 반복적인 자극에 의해 시냅스의 연결이 강화 된다. * 시냅스 약화: 시냅스의 전기적 연결 강도가 감소하여 신호 전달이 덜 효율적으로 이어진다. 자주 사용되지 않는 경로의 연결 강도가 약해진다. 다시 한번 차를 운전해 보자. 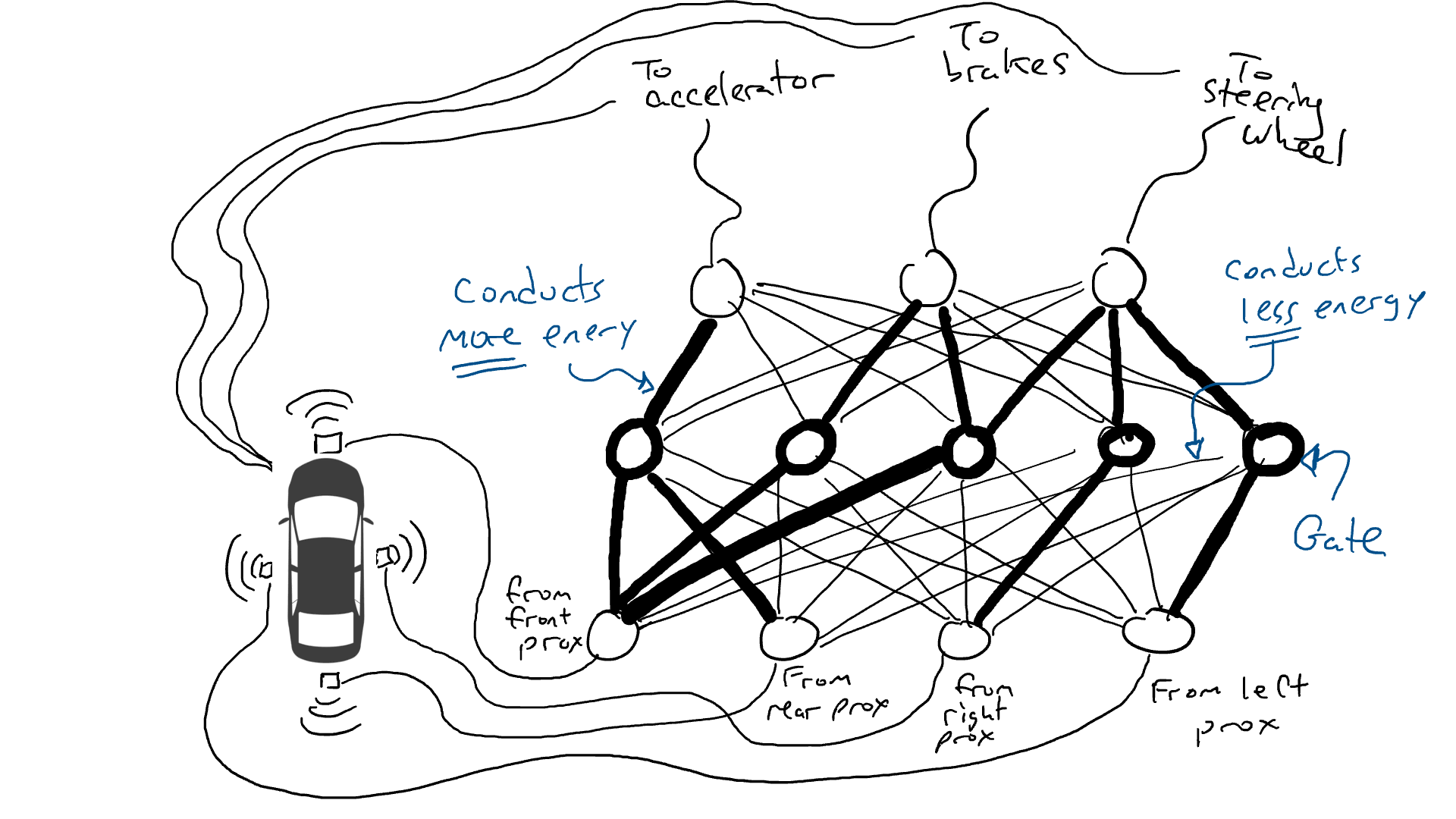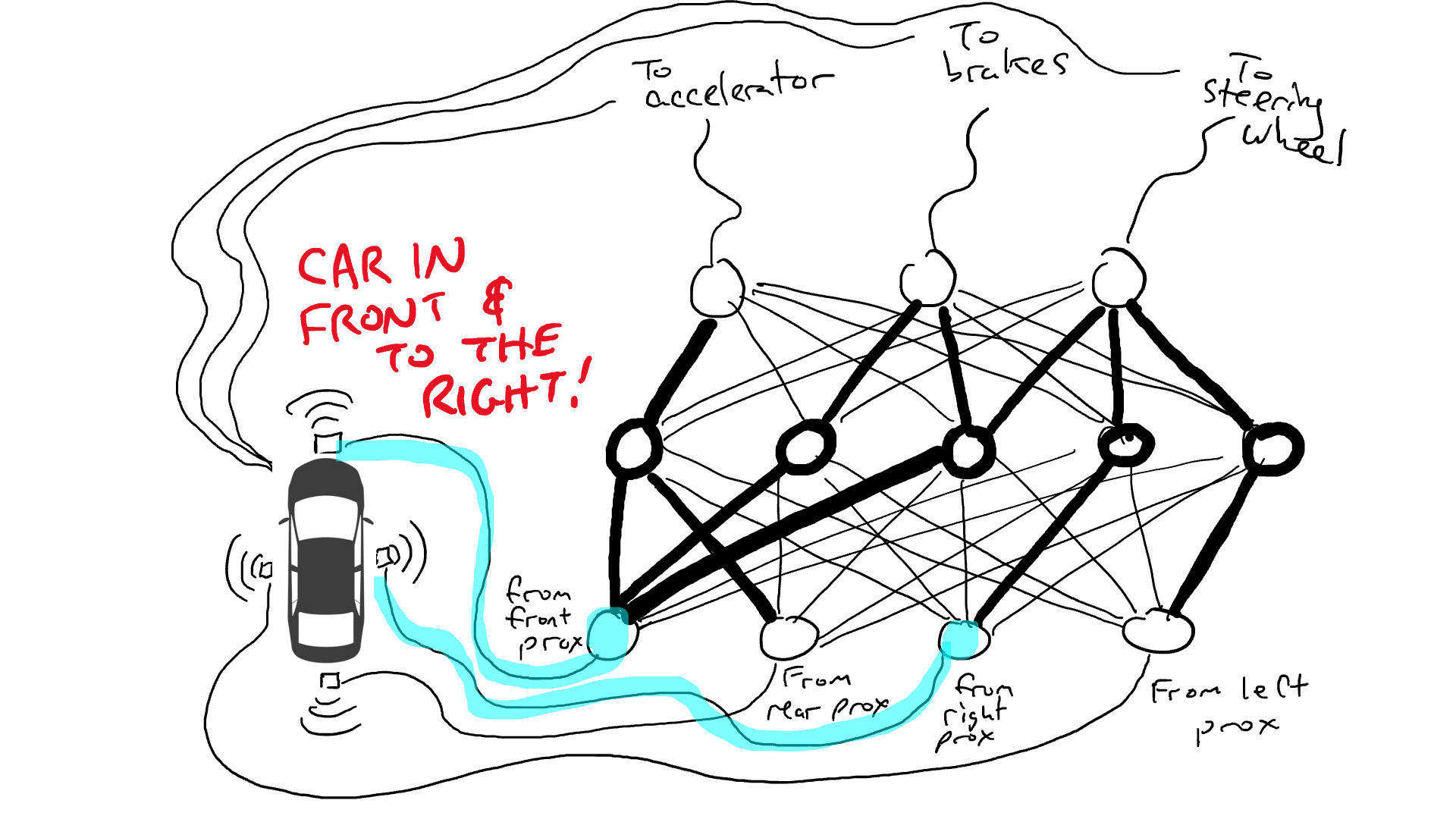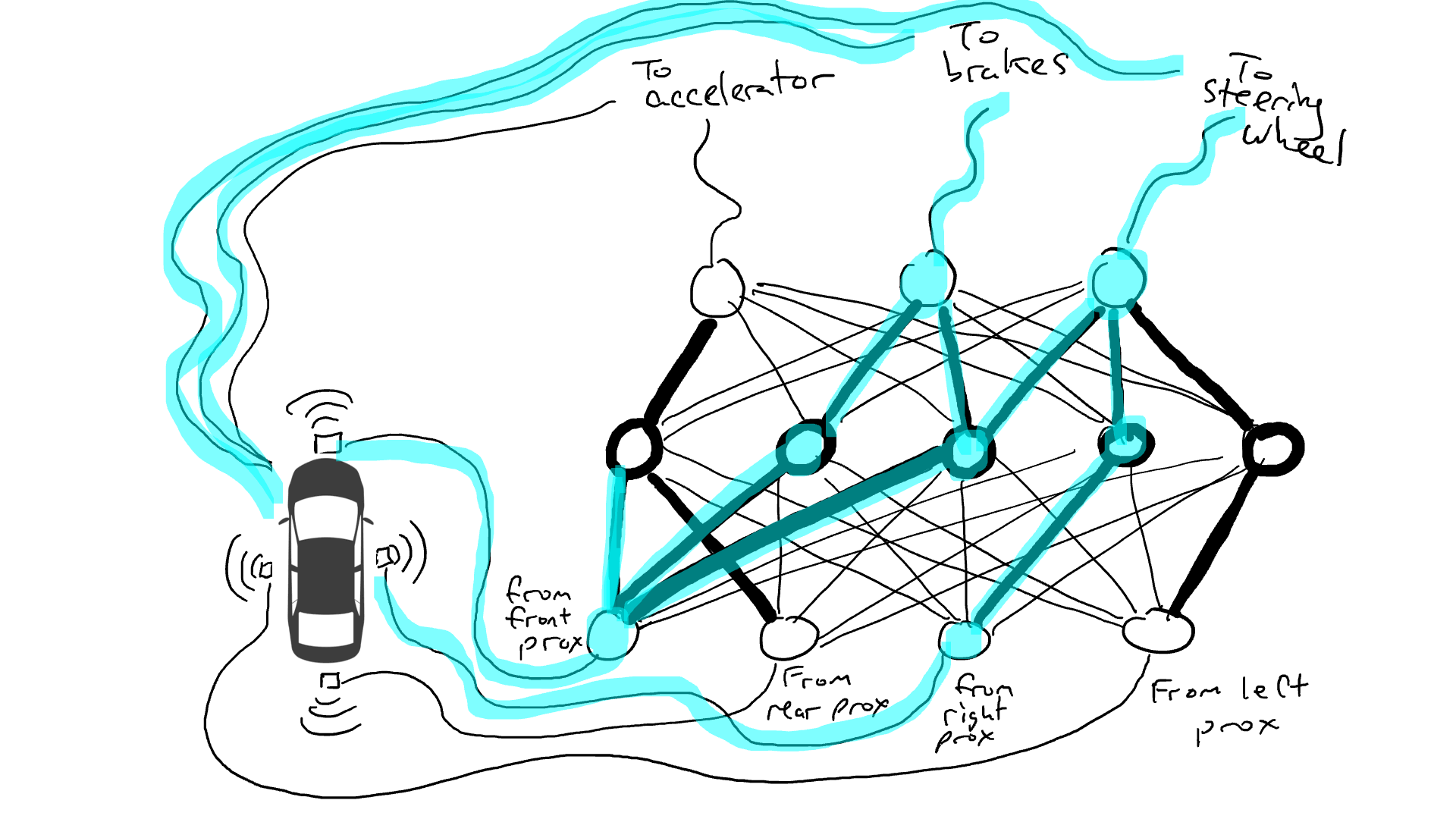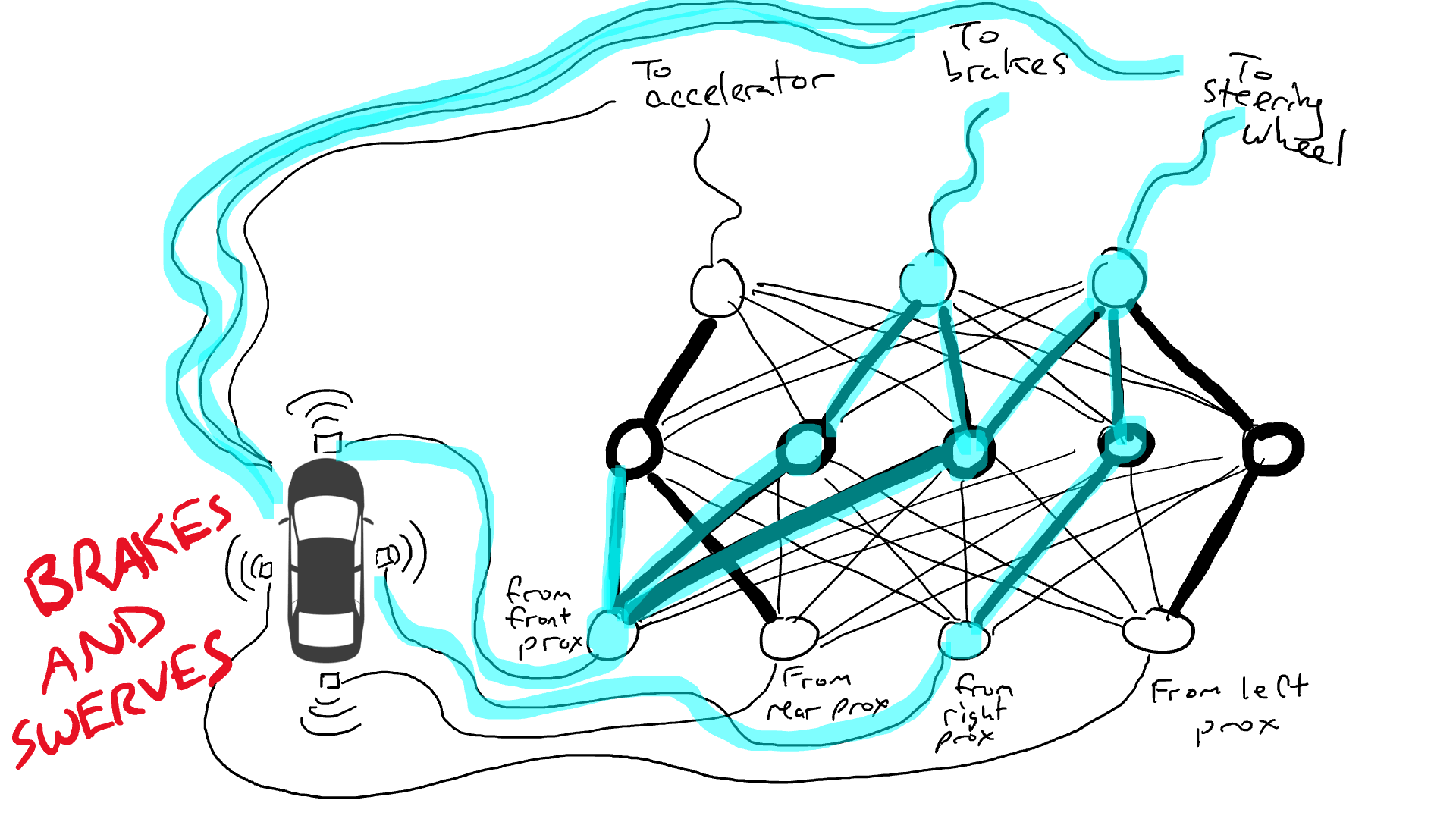 학습한 상황에 따라 전기가 흘러야 하는 경로와 강도가 조정되면서 원하는 행동을 하는 것을 알 수 있다. 여기에서는 알고리즘의 세부사항을 알 필요는 없다. 결국 자율 주행 알고리즘이라는 것은 회로가 데이터가 제안하는 것에 가깝게 작동하도록 하기 위해서 회로에 작은 변경을 가하고 수천 혹은 수백만번의 조정을 거쳐서 제안된 데이터(특정 상황에 브레이크, 가속페달, 휠을 어떻게 작동해야 하는지)에 더 가깝게 작동하도록 학습 시키는 것이라는 것을 개념적으로 이해하면 된다. 여기에서 저항기와 게이트를 **매개변수**라고 부른다. 매개변수가 많으면 복잡한 패턴을 인식할 수 있기 때문에 (일반적으로)성능 향상을 기대 할 수 있다. 메타의 오픈소스 대규모 언어 모델인 LLama3의 경우 LLama3 8B, LLama3 70B 등, 매개변수의 크기별로 모델이 존재하는데 8B는 매개변수가 8억, 70B는 70억이란 의미다. Llama3 70B는 매개변수가 많으므로 그만큼 더 높은 성능을 제공한다. # 📚 딥러닝 이란 우리가 위에서 설계한 설계도는 입력과 출력 사이에 "1개의 층"이 존재하고 있다. 이 층에 저항과 게이트를 배치했는데, 더 많은 층을 넣을 수 있다. 즉 전기를 다음 층으로 보내기 전에 여러가지 곱과 합 연산을 하는 수학적 계산을 할 수 있다. 딥러닝은 많은(깊은)층을 사용하여 복잡한 패턴을 학습 할 수 있도록 설계된 신경망의 특수한 형태다. 신경망은 간단한 모델에서도 사용 할 수 있지만, 딥러닝은 이미지 인식, 자연어 처리, 음성 인식과 같은 대규모 데이터와 복잡한 문제를 처리하는 데 적합하다. # 📚 언어모델이란 앞에서 우리는 신경망 기술을 이용해서 자율 주행 모델을 만들었다. 그리고 딥러닝을 이용해서 좀 더 정교한 모델을 만들 수 있다는 것을 알게 됐다. 이 방식은 **언어**에도 적용 할 수 있다. 우리는 인간이 쓴 글을 보고 인간이 쓴 것과 비슷한 문장을 쓰도록 시퀀스를 생성 할 수 있다. 예를 들어 > "Once upon a ....." 이라는 텍스트가 주어졌다고 가정해보자. "a" 다음에는 아마도 **time** 이라는 단어가 등장해야 할 것이다. 이 외에 대략 아래와 같은 단어들이 등장 할 수 있을 것이다. * Once upon a **dream** * Once upon a **forest** * Once upon a **kingdom** * Once upon a **journey** 반면 "armadillo"같은 단어가 나오면 안될 것이다. 흔히 우리는 언어모델을 확률의 관점에서 이야기 하는 경향이 있는데, 수학적으로는 아래와 같이 나타낼 수 있다. ``` P(time | once, upon, a) ``` 어렵게 생각 할 필요 없다. 이것은 "once upon a" 라는 단어가 주어졌을 때, time 이라는 단어가 나올 확률 *P* 를 의미한다. 좋은 언어 모델이라면 "armadillo" 라는 단어 보다 "time"이라는 단어가 나올 확률이 더 높을 것으로 예상 할 수 있다. 이를 일반화 하면 아래와 같다. ``` P(word_n| word_1, word_2, ..., word_n-1) ``` 이는 주어진 모든 단어 1 ~ n-1 을 기준으로 n 번째 단어가 나올 확률을 계산한다는 것을 의미한다. 이론적으로 우리는 one upon a 다음에 "dream, forest, kingdom, ..." 등의 단어가 잘 나오도록 하면 된다. 하지만 현실은 간단 하지가 않은데 영어 단어의 갯수가 많기 때문이다. 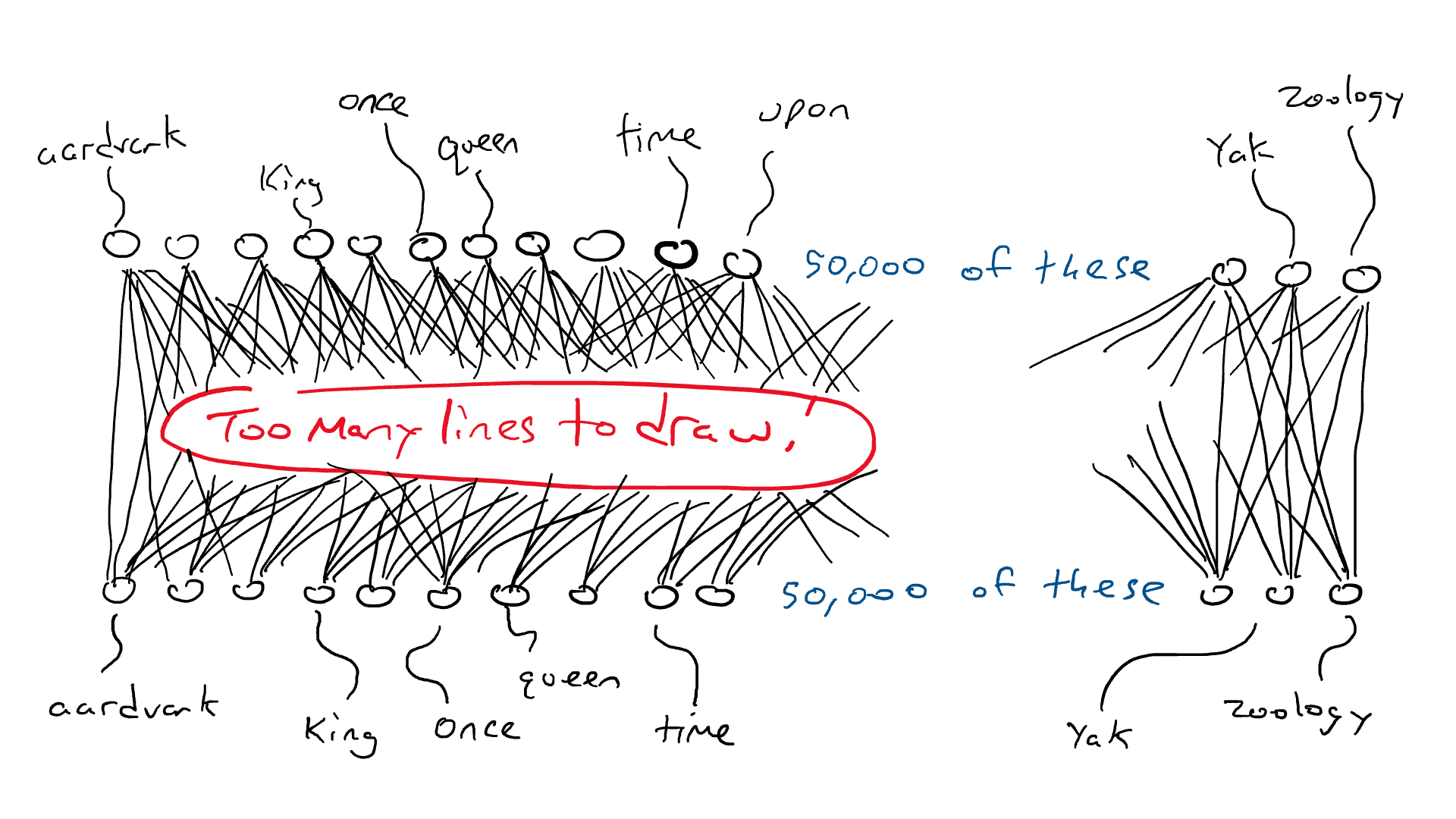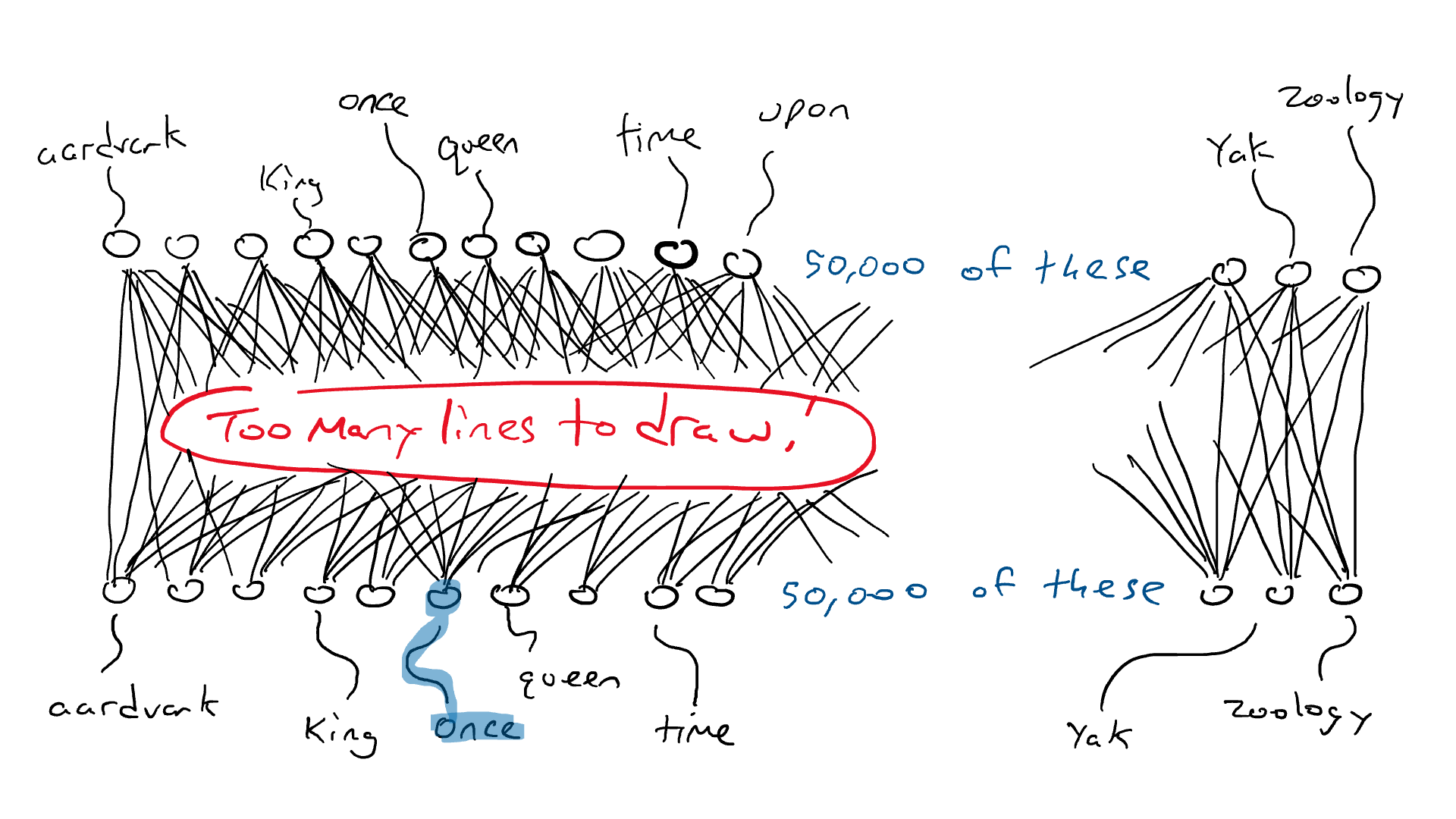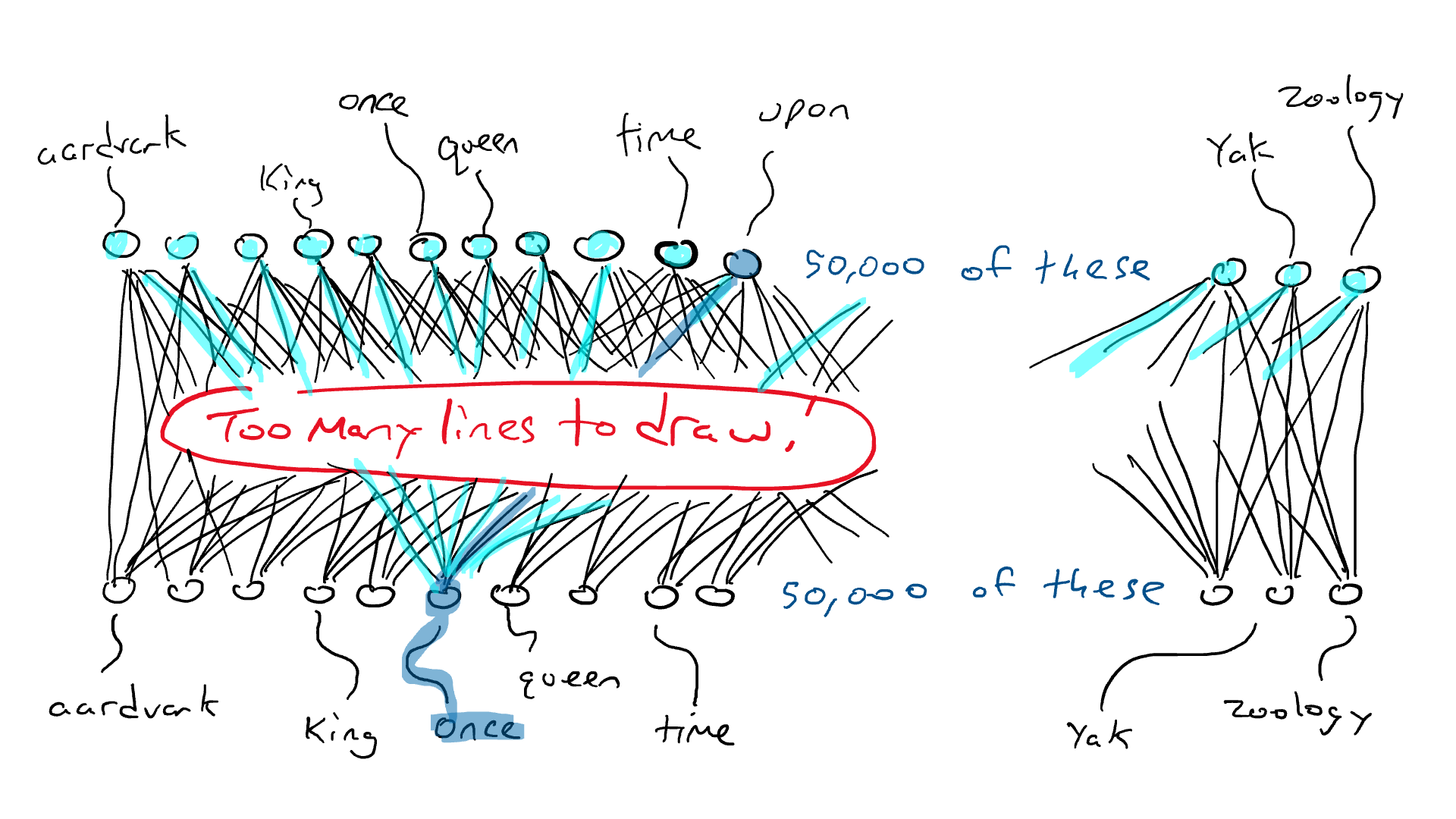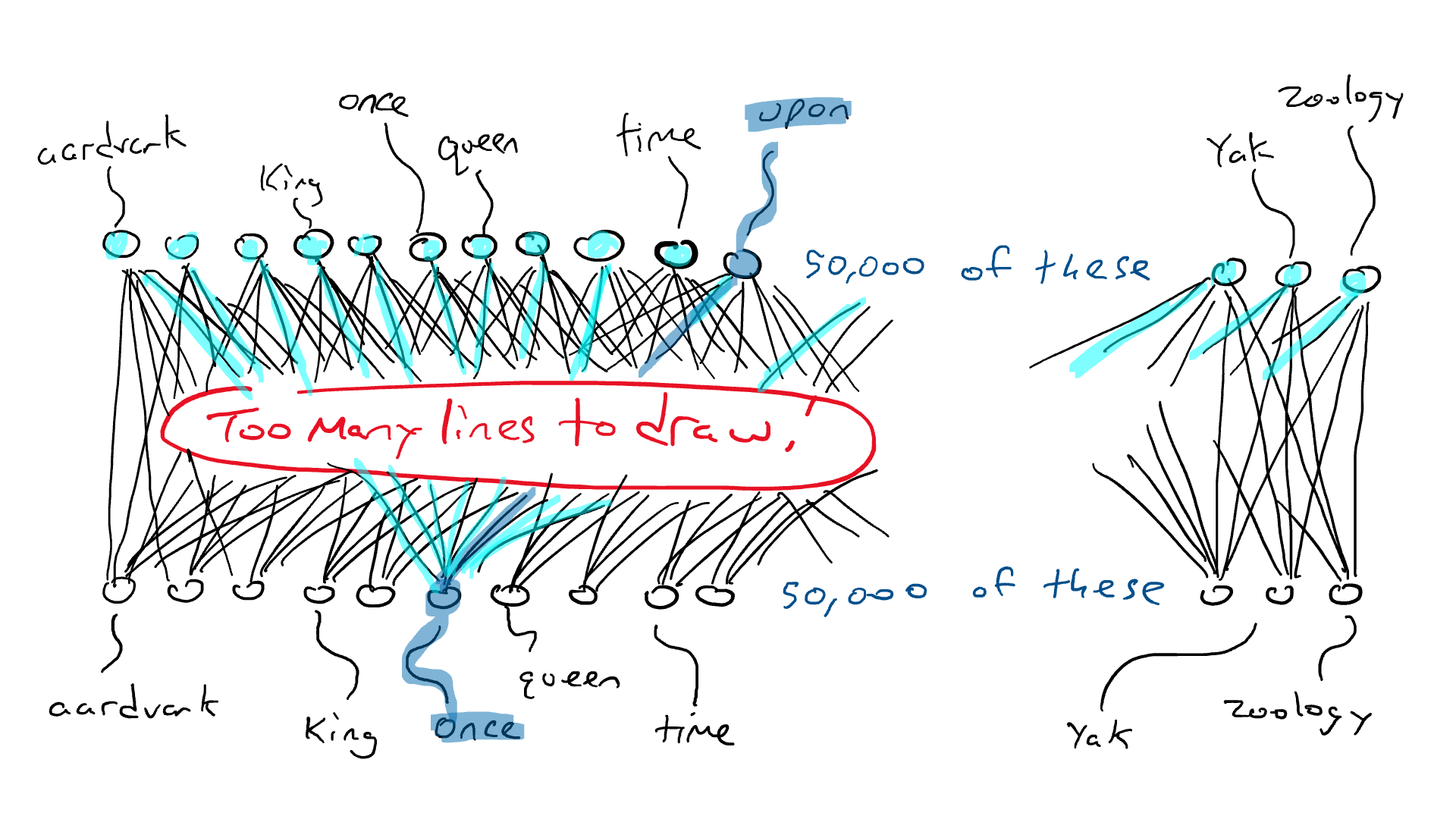 예를 들어 50,000 개의 단어가 있다고 가정해보면 입력과 출력은 50,000 x 50,000 즉 25억개의 연결이 만들어져야 한다. 엄청난 크기의 네트워크다. 게다가 상황은 더 나빠진다. "Once upon a" 3개의 단어가 주어지기 때문에 50,000 * 3 = 150,000 따라서 150,000 x 50,000 = 75 억 개의 연결이 생긴다. 현재 대규모 언어 모델이 32,000 개 정도의 단어를 처리할 수 있다는 것을 가정하면, 절망적인 복잡도다. 이 상황을 처리하기 위해서 몇 가지 요령이 필요하다. 우리는 단계적으로 처리를 할 것이다. ### 인코더(Encoder) 우리가 첫 번째 할 일은 회로를 두 개의 회로로 나누는 것이다. 하나는 **인코더**라 하고 다른 하나는 **디코더**라고 한다. 기본적인 아이디어는 많은 단어들이 대략적으로 같은 것을 의미한다는 점이다. 아래의 구문을 보자. > The king sat on the ___ > The queen sat on the ___ > The princess sat on the ___ > The regent sat on the ___ 위의 모든 빈칸에 대한 합리적인 추측은 throne(왕좌) 일 것이다. 즉 "king"과 "throne", "queen"과 "throne" 사이에 개별적인 연결이 필요하지 않을 수 있다. 대신 king과 queen을 묶을 수 있는 **royalty(왕족)** 과 같은 의미가 있을 것이고 king과 queen, princess을 만날 때마다 royalty 단어를 사용하면 좋을 것이다. 즉 입력을 그룹핑(범주화)하여서 크기를 줄일 수 있는 것이다. 이것을 인코더라고 하는데, 거대한 단어셋을 압축하는 일을 한다. 압축하는 방법은 대략 아래와 같다. 1. 비슷한 단어를 그룹화: 단어들 사이의 의미적인 관계를 학습하여서, 이들을 그룹화한다. 2. 차원 축소 및 정보 압축: 고차원 공간에서 표현된 데이터를 더 작은 차원으로 압축하여 중요한 정보만을 남긴다. 3. 의미적 압축: 단순한 차원 축소뿐 아니라, 단어의 문맥에 따른 의미를 추출하고 중요한 패턴을 압축하는 역할을 한다. 일단은 인코더는 **비슷한 단어를 그룹화** 하고, 의미적, 구조적 정보를 압축하는 과정으로 설명할 수 있다. 이를 통해서 정보량을 줄여서 입력 데이터를 좀 더 효율적으로 처리하며, 텍스트의 중요한 의미적 요소를 학습 할 수 있다. 이제 우리가 할 일은 다음과 같다. 50,000 개의 단어 세트가 아닌 256 개와 같은 더 작은 출력 세트에 맵핑하는 하나의 회로를 설정한다. * royalti = {king, queen, princess} 마찬가지로 입력도 **royalti** 와 같은 범주(예: 장갑 포유류) 단위로 트리거 할 수 있다. 이렇게 전체 입력을 몇개의 출력으로 압축하는 회로를 인코더라고 한다. 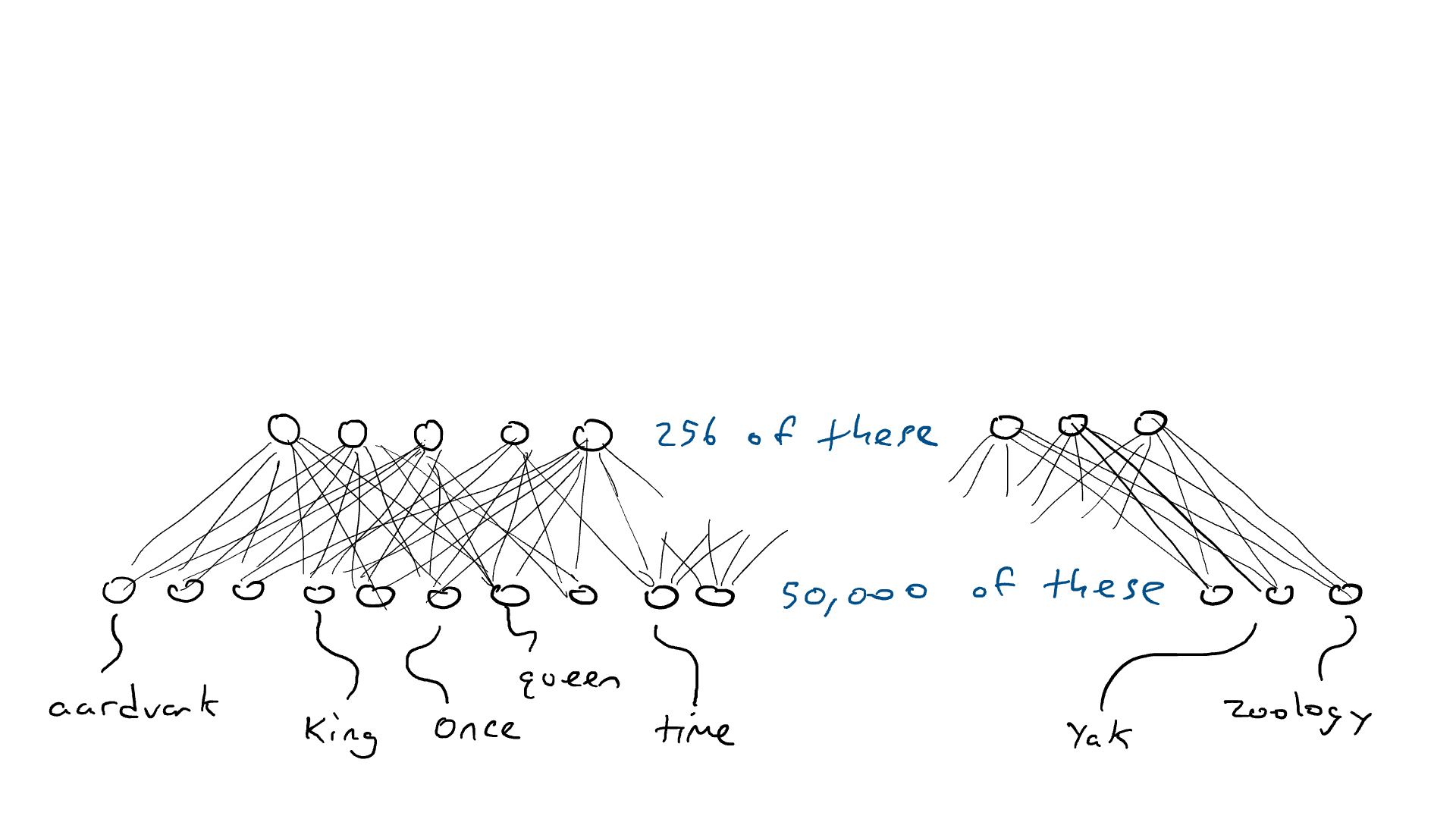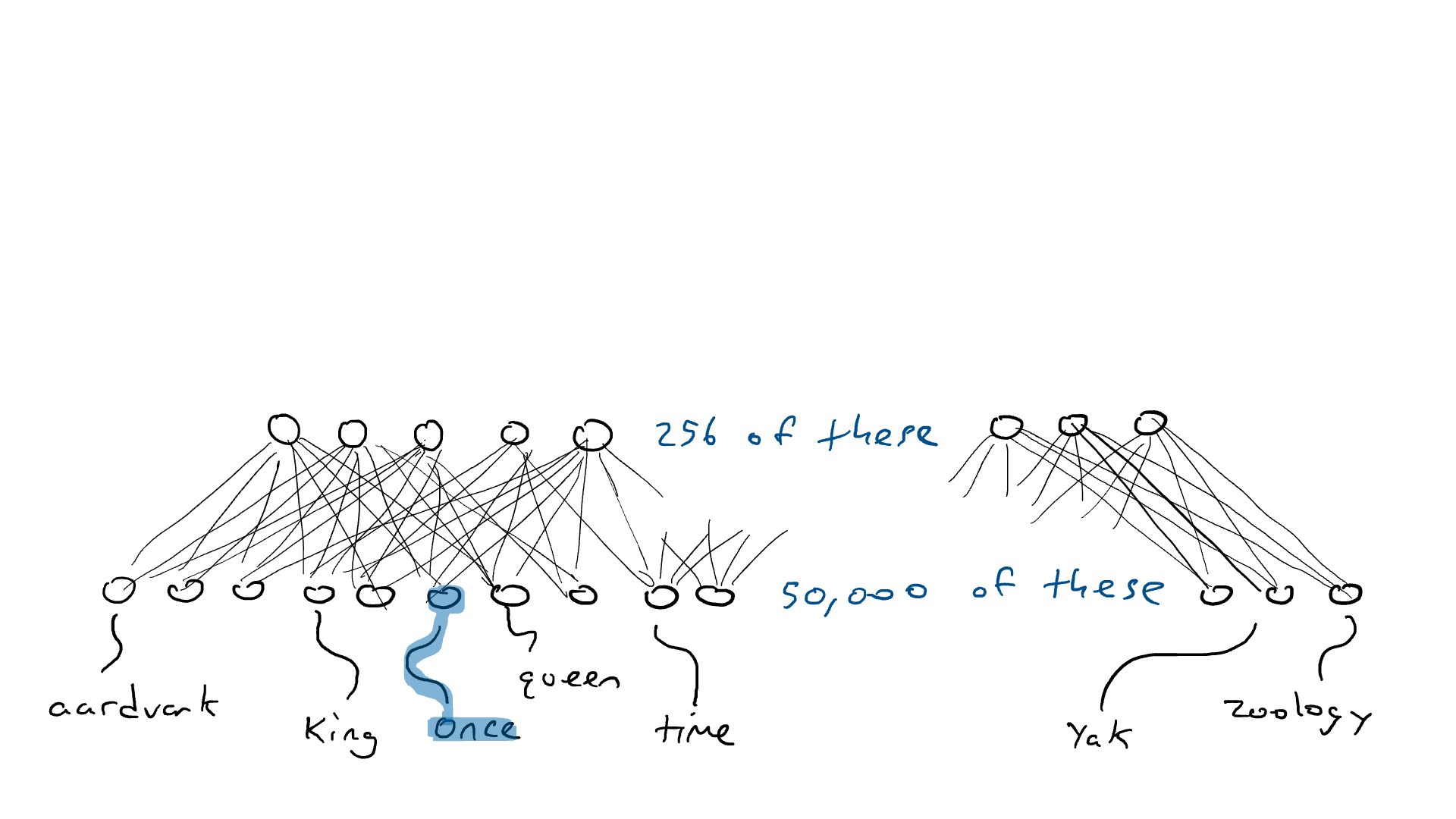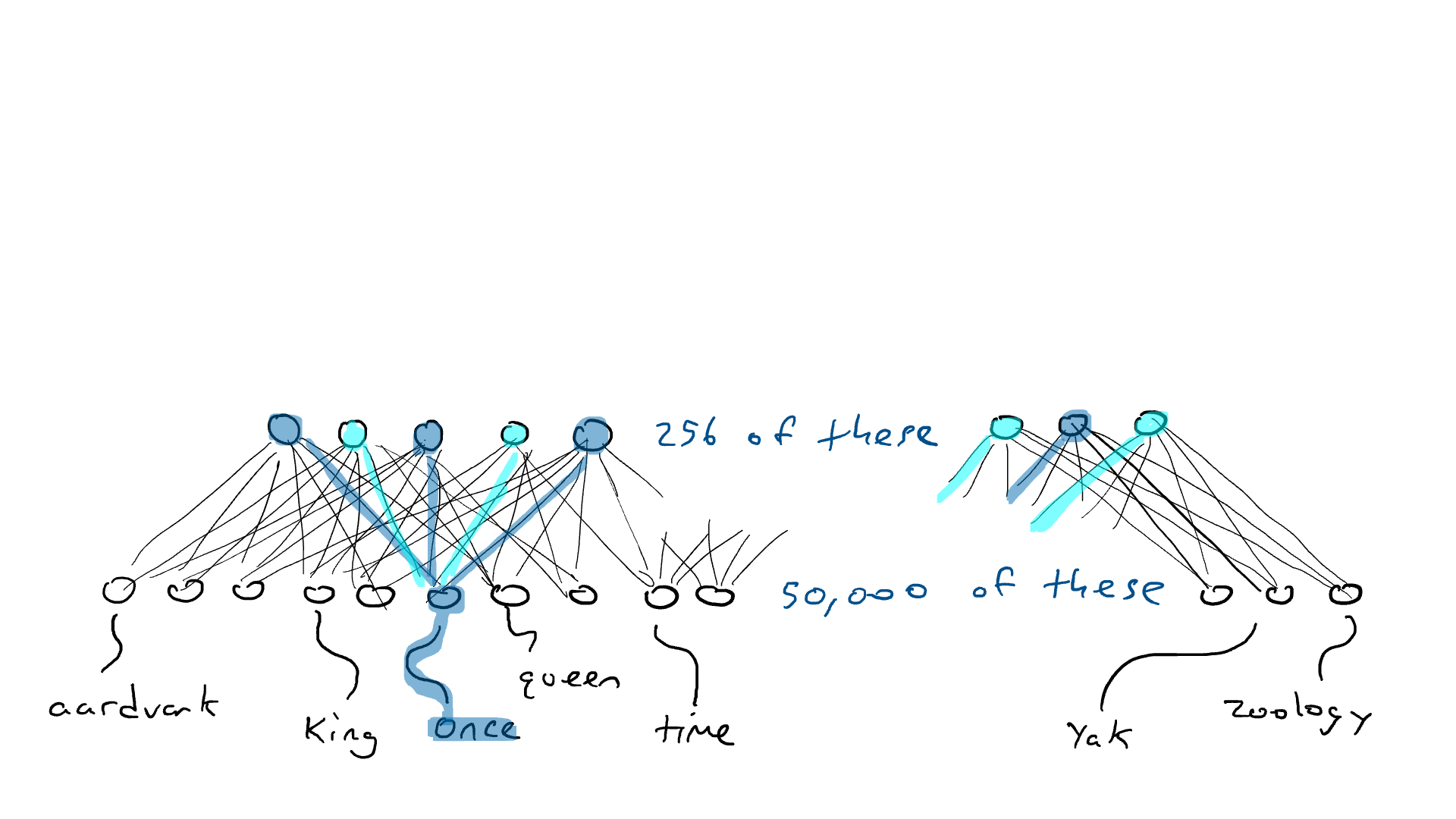 이렇게 우리는 50,000 개의 단어(센서)를 256 개의 출력으로 압축하는 회로를 만들었다. ### 디코더 인코더의 목적은 입력된 데이터를 이해하고, 그 의미를 더 압축된 형식으로 변환하는 것이다. 하지만 인코더는 다음에 어떤 단어가 나와야 하는지를 알려주지는 않는다. 그래서 우리는 인코더를 디코더 네트워크와 페어링 한다. 디코더는 인코딩을 구성하는 256 개의 숫자를 취하고 각 단어에 대해서 하나씩 원래 50,000 개의 단어와 연결되는 또 다른 회로다. 그리고 가장 출력이 높은 단어를 선택한다. 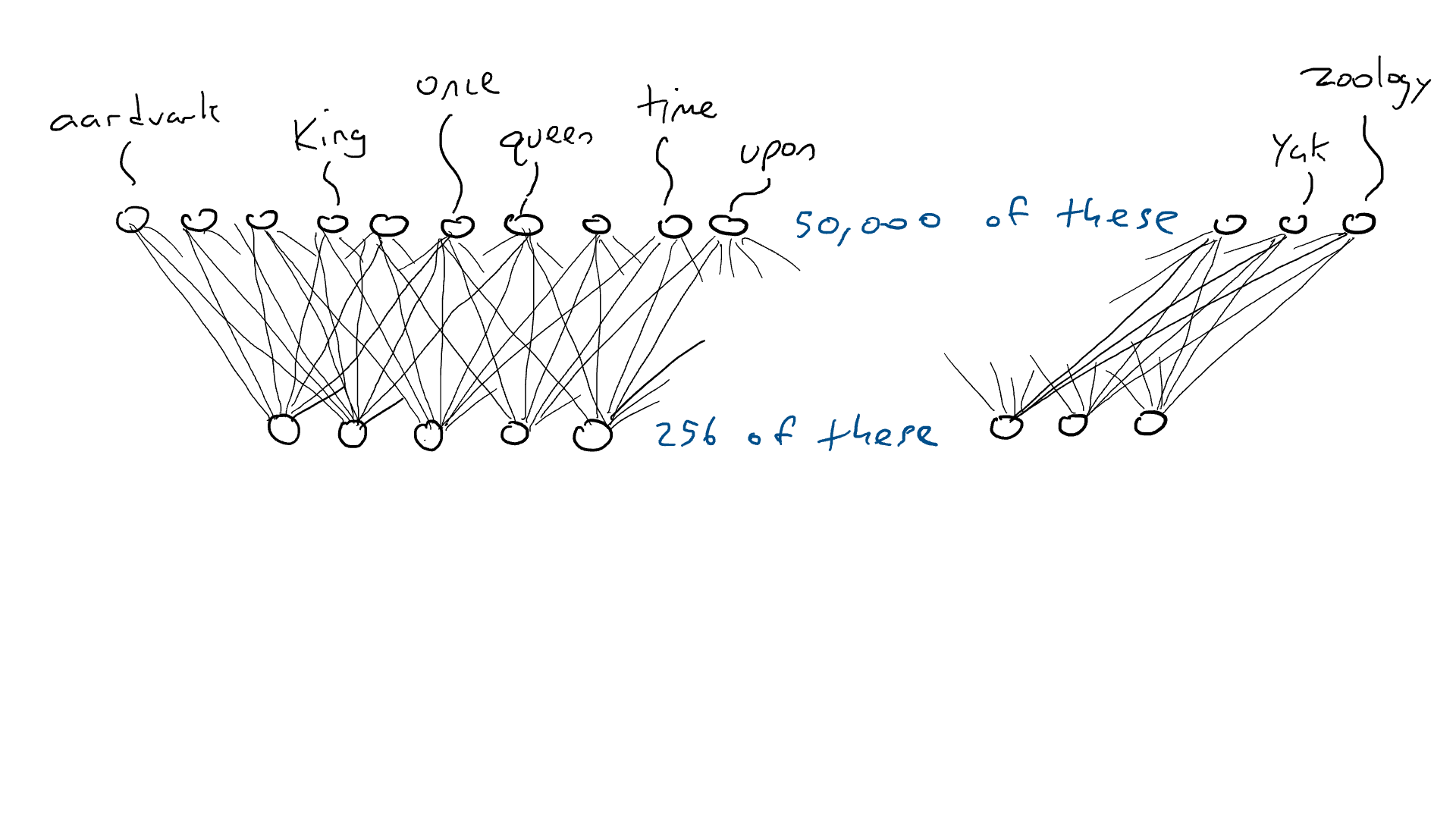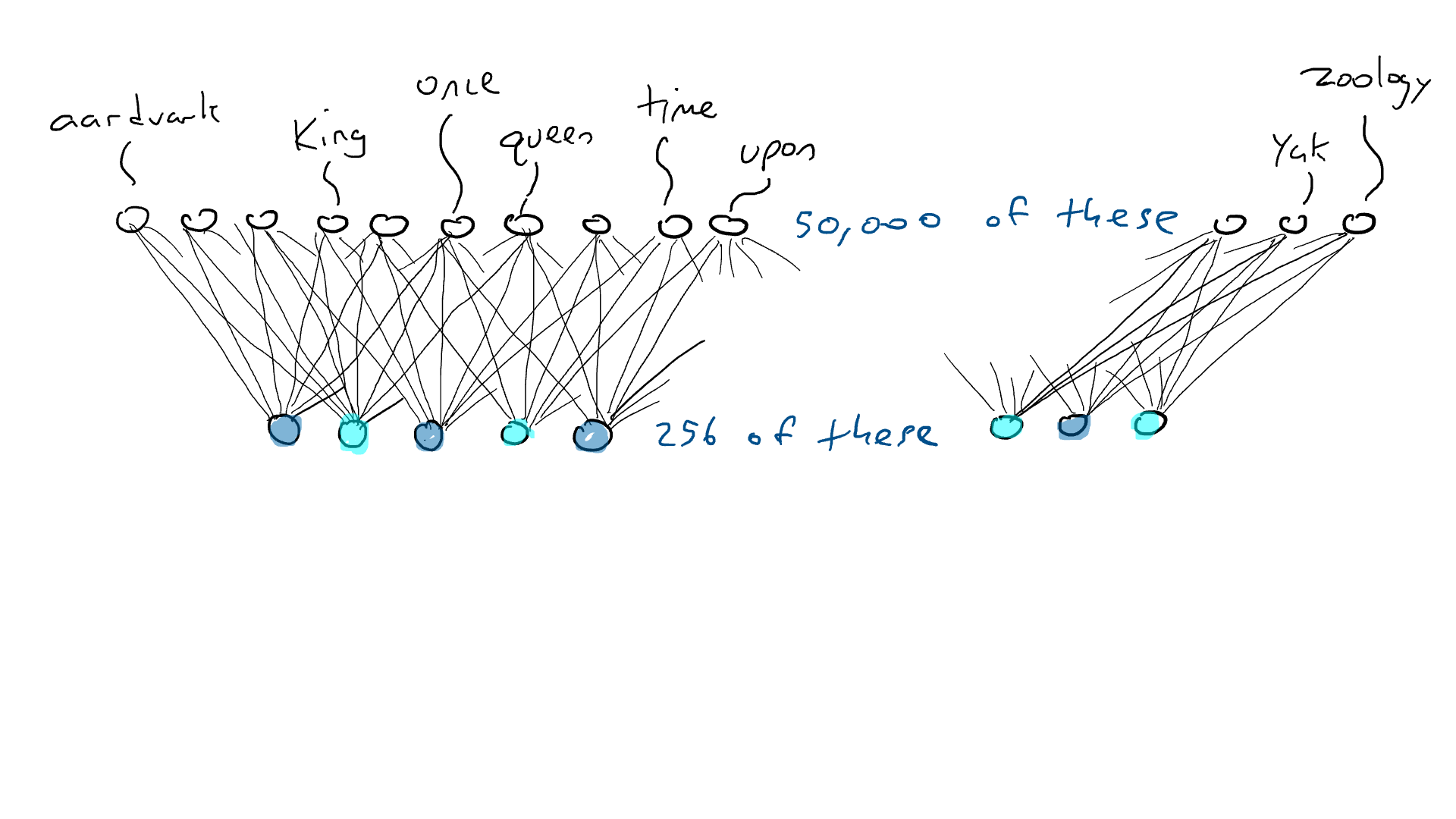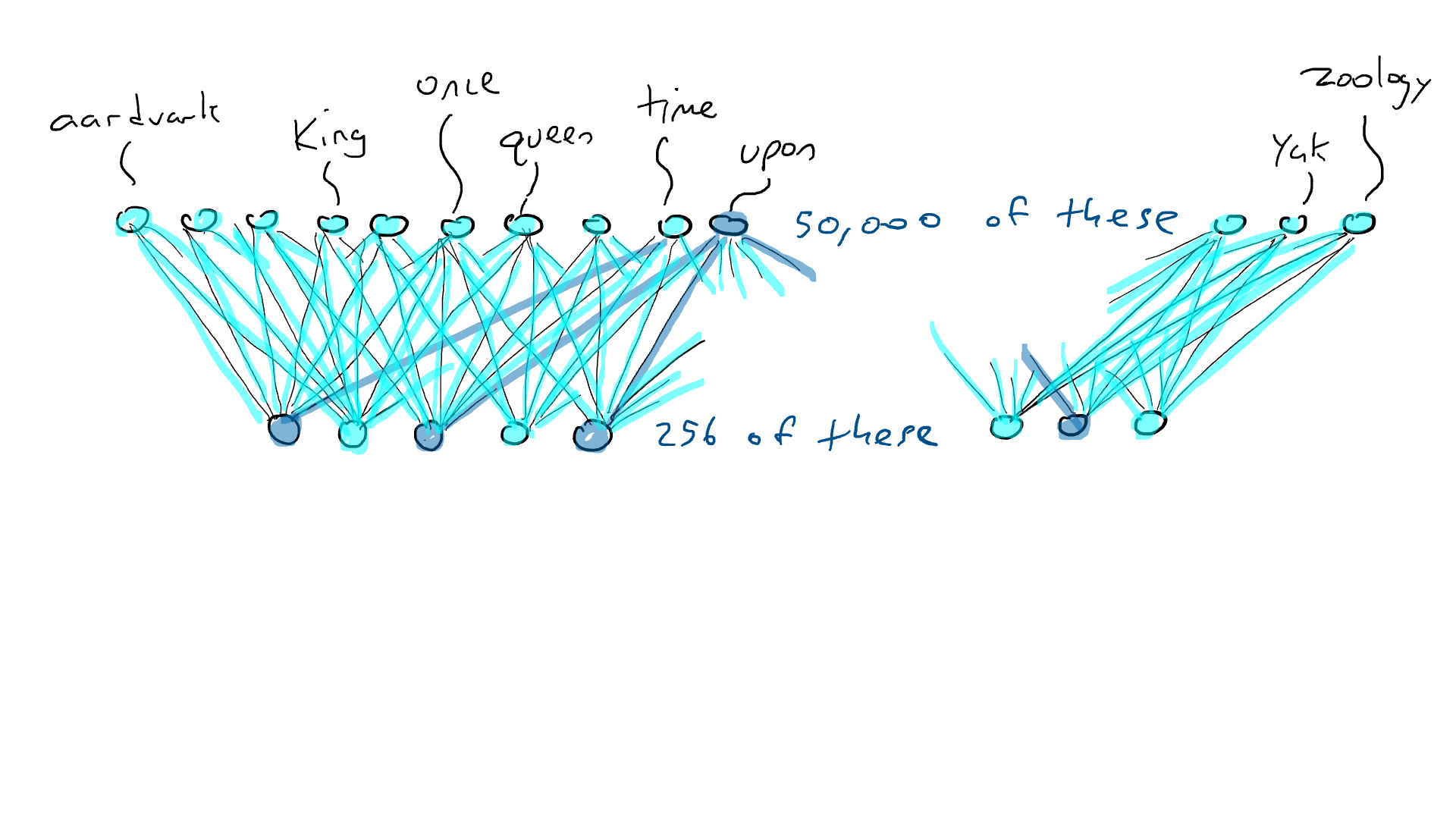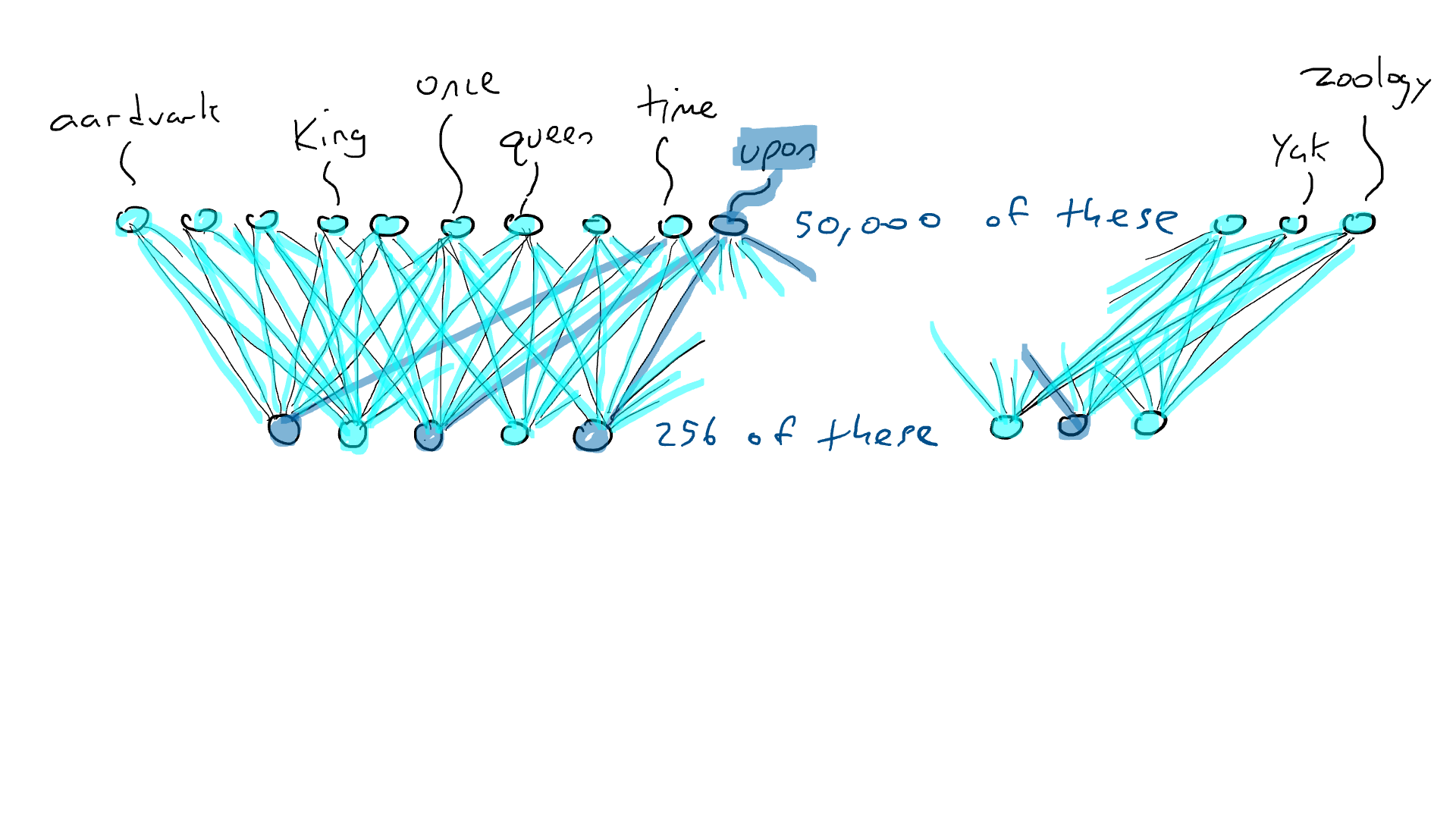 ### 인코더와 디코더 이렇게 인코더와 디코더를 합치면 하나의 신경망을 만들 수 있다. 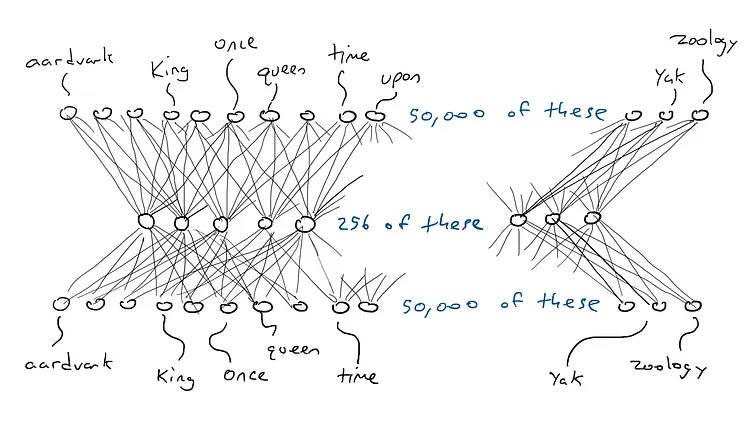 이때 필요한 매개변수는 (50,000 \* 256) \* 2 = 2560 만개로 25억 보다는 훨씬 낫다. 50,000 을 256으로 압축하고 다시 50,000 으로 풀었다. 이는 파일의 압축과 매우 유사하다. 파일을 압축하면 공간을 크게 절약 할 수 있다. 그리고 압축을 풀면 원래 읽을 수 있는 텍스트를 복구 할 수 있다. 인코더와 디코더 회로는 의미 기반으로 단어를 압축하고 압축을 푸는 저항기와 게이트를 구성해서 학습을 한다. ### Self-Supervision 각 단어에 대해서 어떤 인코딩이 가장 좋은지 어떻게 알 수 있을까 ? 다시 말해 "king"에 대한 인코딩이 "armadillo"가 아닌 "queen"과 유사해야 한다는 것을 어떻게 알 수 있을까 ? 사고실험을 해보자, 단일 단어(50,000 개의 센서)로 부터 정확히 동일한 단어를 출력하는 인코더-디코더 네트워크가 있다고 가정해보자. 쓸모없는 모델이지만 다음 일어날 일을 이해하는데 도움이 될 것이다. 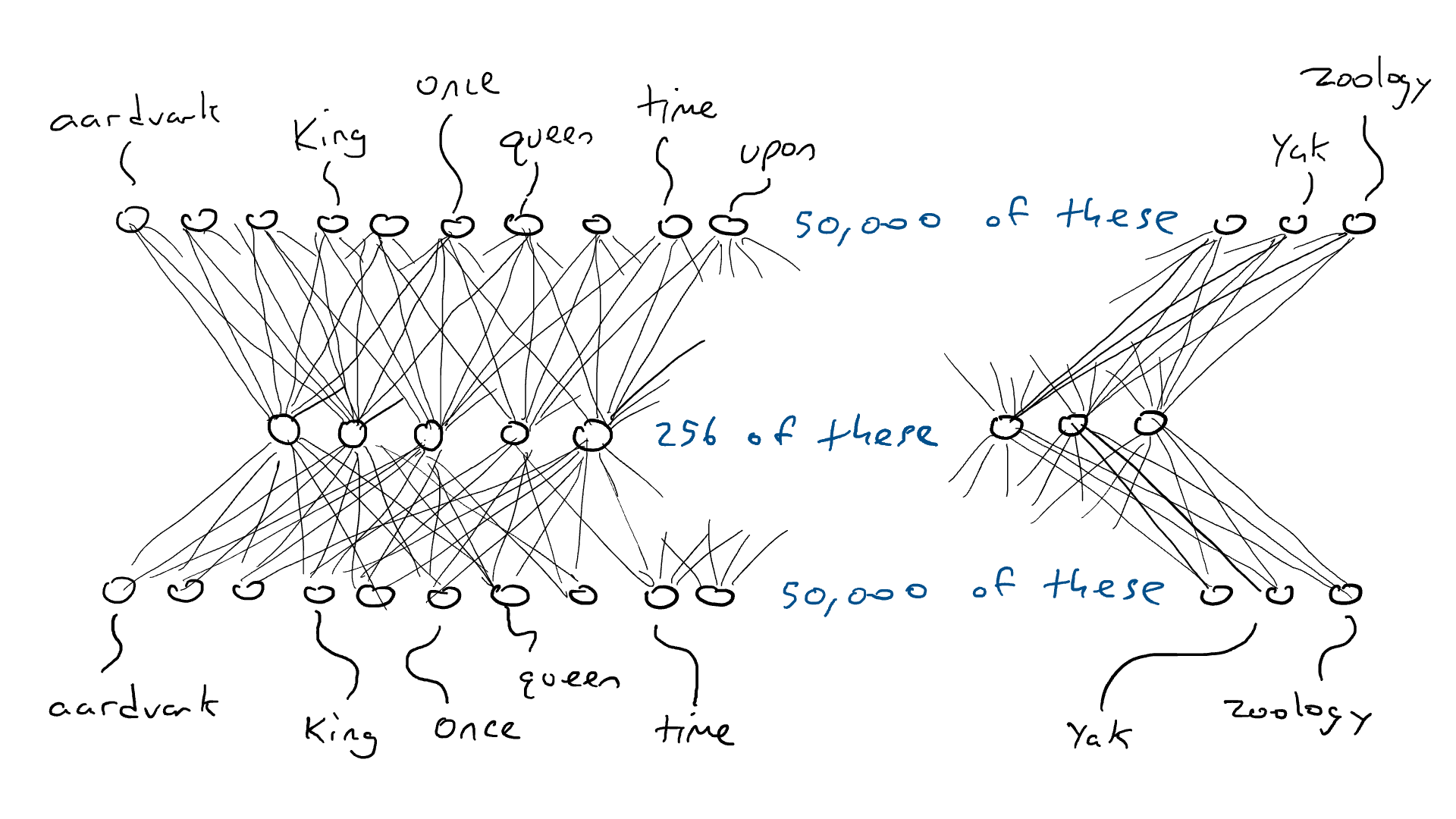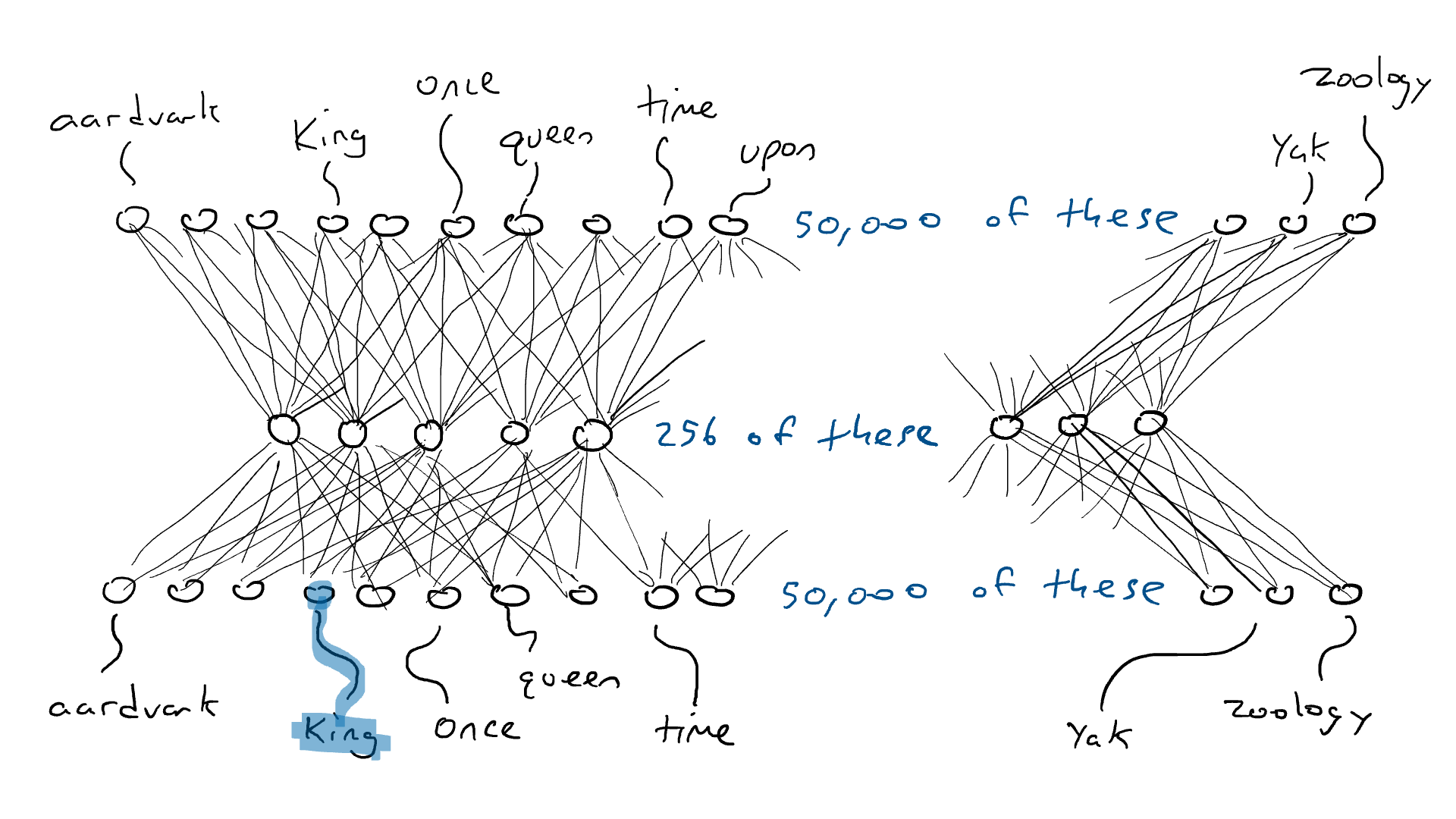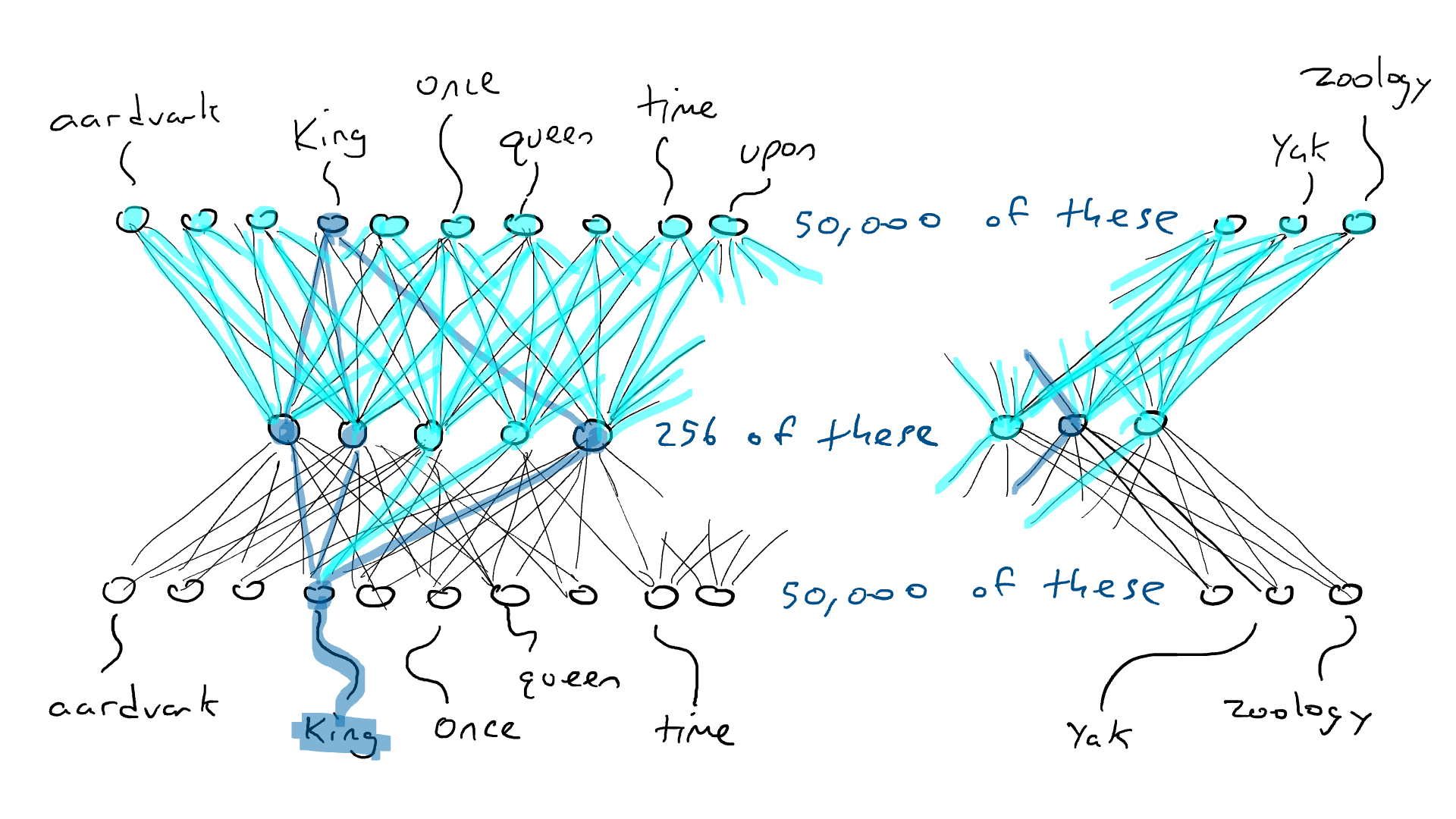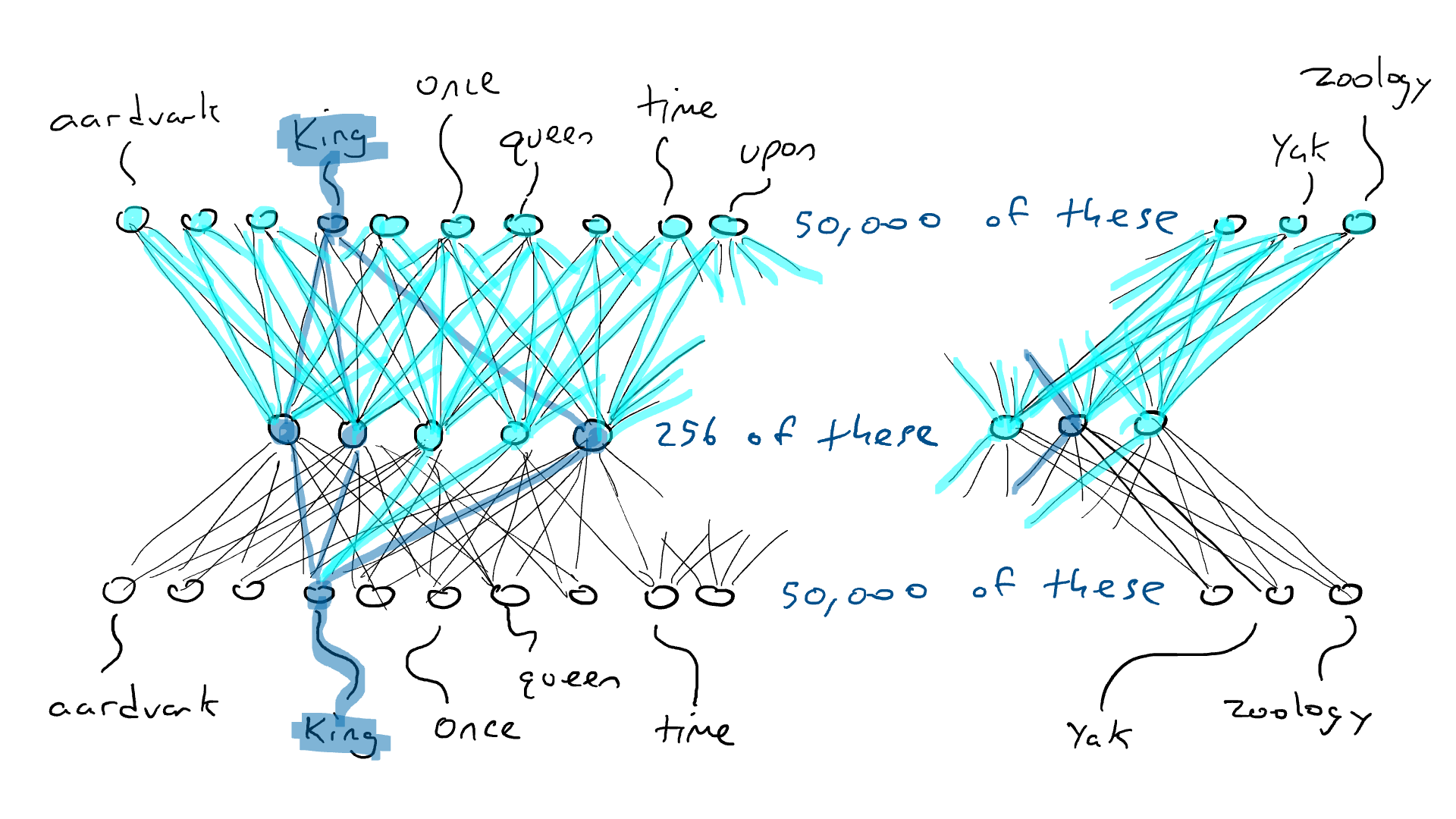 King을 입력하면 센서는 인코더를 통해서 256개 중 하나를 활성화한다. 그리고 디코더는 가장 높은 신호 값을 가지는 King으로 보낸다. 디코딩 부분을 살펴보면 King는 0.51 이고 upon 은 0.02 가 될 것이다. King의 출력 에너지는 0.51로 1이 아님을 알 수 있다. 0.51에서 1.0의 차이는 오류(혹은 손실이라고도 함)이다. 중요한 것은 가장 높은 값이 0.51이므로 King이 출력 된다는 점이다. 디코더는 Queen에 대해서는 0.48 정도의 값을 가지는 것으로 추측할 건데, King과 아주 관련성이 적은 upon은 0.02 이므로 모델 스스로 어떤 출력이 가장 적당한지를 결정 할 수 있다. 모델은 출력을 입력과 비교할 뿐이고 이를 위해서 별도의 데이터를 수집할 필요가 없다. 이를 Self-Supervision 이라고 한다. ### Masked Language Models 마스크 언어 모델은 "단어 시퀀스에서 일부분을 숨기고(Mask)" 그 부분을 예측하는 방식으로 학습하는 모델이다. **BERT(Bidirectional Encoder Representations from Transformers)** 가 이 방식을 사용한다. ``` The <Mask> sat on the throne. ``` 핵심 개념은 아래와 같다. * Masking: 텍스트의 일부 단어를 가리고, 모델이 그 가려진 단어를 예측할 수 있도록 훈련한다. 즉 The \<Mask\> sat on the 에서 Mask에 들어갈 단어를 예측하는 것이다. 작동 방식을 살펴보자. 1. 입력 문장에 있는 일부 단어를 선택해 \<MASK\>토큰으로 바꾼다. 1. 예: "고양이가 밥을 먹었다" -> "고양이가 \<MASK\>을 먹었다" 1. 예: "고양이가 생선을 먹었다" -> "고양이가 \<MASK\>을 먹었다" 2. 모델은 이 마스킹된 문장을 보고 MASK 자리에 어떤 단어가 들어갈지 학습하게 된다. 3. 모델이 학습을 하는 동안, 문맥을 바탕으로 가려진 단어를 예측하는 능력이 향상된다. 이렇게 학습시키면 아래와 같이 문장을 만들 수 있다. ``` The [MASK] The queen [MASK] The queen sat [MASK] The queen sat on [MASK] The queen sat on the [MASK] ``` 우리는 이것을 자기 회귀 모델(auto-regression model) 이라고 부른다. 회귀라는 단어가 어려울 수 있는데, 이전에 **자기가** 사용한 단어를 이용해서 예측한다는 의미다. 단어를 예측하고, 그 다음에 자기가 사용한 단어를 이용해서 예측하고, 그 단어를 이용해서 다음 단어를 예측하는 식으로 계속된다. ### Transformer 이제 어디에서든 GPT-3, GPT-4, ChatGPT라는 단어를 접할 수 있다. GPT는 OpenAI라는 회사에서 개발한 LLM의 브랜드명이다. GPT는 **Generative Pre-trained Transformer** 의 약자인데, 이들 단어에서 GPT의 특징을 확인 할 수 있다. * Generative(생성적): 모델은 입력에 대해서 연속된 단어를 생성하려고 한다. 즉 어떤 텍스트가 주어지면 모델은 다음에 어떤 단어가 올지 추측하려고 한다. * Pre-trained(사전 훈련): 이 모델은 매우 큰 일반 텍스트 코퍼스로 훈련되었으며, 한 번 훈련하면 다시 훈련할 필요 없이 다양한 용도로 사용 할 수 있다. 사전학습의 경우 예를 들어 GPT는 상상할 수 있는 많은 주제를 포괄하는 방대한 일반 텍스트 코퍼스에서 학습되었다. 이는 일부 문서 저장소에서 가져온 것이 아니라 "인터넷에스 스크랩한 문서"를 의미한다. 일반 텍스트에서 학습함으로써 광범위한 입력에 대응 할 수 있다. 일반 코퍼스에서 학습된 언어 모델은 이론적으로 인터넷 문서에 있는 모든 것에 대해서 합리적으로 응답할 수 있다. 모델은 많은 면에서 뛰어나서 직접 훈련 할 필요가 없는 경우도 있지만 "**미세 조정(Fine Tuning)**"이라고 불리는 작업을 해야 할 수도 있다. 왜냐하면, 인터넷에는 광범위한 다양한 문서들이 있지만 특정 도메인의 전문적인 정보는 부족할 수 있기 때문이다. 미세 조정은 사전 훈련된 모델을 가져와서 몇 가지 데이터를 업데이트 해서 특정 작업(예: 의료, 금융, 제조)에서 더 잘 작동하도록 만드는 것을 의미한다. 이제 트랜스포머에 대해서 알아보자 * Transformer: 자기 주의 메커니즘(Self-attention mechanism)을 기반으로 인코더와 디코더 구조를 통해 시퀀스 데이터를 처리하는 딥러닝 모델. 트랜스포머는 특정 방식의 인코딩을 이용하여 단어를 쉽게 추측하게 만든 딥러닝 모델의 일종이다. 2017년 Attention is All you Need라는 논문에 소개되었다. 트랜스포머의 핵심은 고전적인 인코더-디코더 네트워크다. 매우 표준적인 인코더를 사용하기 때문에 매우 평범하다. 하지만 여기에 Self-Attention이라는 것이 추가되었다. ### Self-Attention Self-Attention의 개념은 아래와 같다. 시퀀스의 특정 단어는 다른 단어와 관계가 있다. 예를 들어 "The alien landed on earth because it needed to hide on a planet"라는 문장이 있다고 가정해보자. 두 번째 단어인 "alien"을 마스크 처리하고 신경망에 단어를 추측하도록 요청하면 "landed" 과 "earth"와 같은 단어로 인하여 더 나은 결과를 얻을 수 있다. 마찬가지로 "it"을 마스크 처리하고 신경망에 단어를 추측하도록 하면 "alien"이라는 단어로 인하여 "he"나 "her" 보다 "it"을 선택할 가능성이 더 높아질 수 있다. 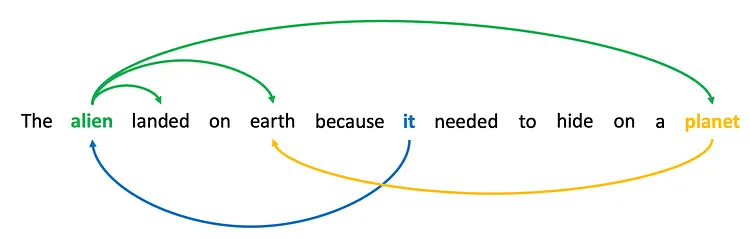 이렇듯 시퀀스의 단어가 다른 어떤 단어와 어떤 종류의 관계를 맺고 있는지를 포착하기 때문에 다른 단어에 주의(attention)을 기울인다고 말한다. 이 관계는 명사와 대명사, 주어와 동사의 관계가 될 수 있고 혹은 비슷한 범주(earth와 planet)의 단어가 될 수도 있다. 그게 무엇이든 단어사이에 어떤 종류의 관계가 있다는 것을 아는 것은 예측에 매우 유용하다. 주요 요점은 트랜스포머가 입력 시퀀스의 단어가 어떤 관련이 있는지 학습한 다음, 입력 시퀀스의 각 단어와 관련된 모든 단어에 대한 새로운 병합 인코딩을 생성한다는 것이다. 이것은 "alien" 과 "landed", "planet"를 합성하여 새로운 표현을 만드는 법을 배우는 것으로 생각 할 수 있다. # 📚 LLM이 강력한 이유 ChatGPT 등을 포함한 대규모 언어 모델은 정확히 한 가지 일을 한다. 즉, 많은 단어를 받은 다음에 그 다음에 어떤 단어가 나올지 추측하려고 한다. 추론 혹은 생각의 특수화된 형태 중 하나 일 뿐이다. 즉, 사람처럼 추론하고 생각하는 것은 아니다. 이 때문에 LLM을 단지 **통계적 패턴인식** 과 **확륙론적 추론** 에 바탕을 두고 있는 "통계에 기반한 추론 시스템"이라고 부르기도 한다. 하지만 특수한 형태라고 해서 쓸모가 없는 것이 아니다. 바퀴가 인간 다리의 특수한 형태라고 해도 엄청난 쓸모가 있는 것처럼 말이다. ChatGPT의 이러한 특수한 형태의 작업능력으로 많은 일들을 할 수 있기 때문이다. 시 쓰기, 과학 및 기술 관련 질문에 답하기, 문서 요약하기, 이메일 초안 작성하기, 심지어 코드 작성하기 등이다. 단지 통계에 기반한 추론 시스템일 뿐인데, 왜 이렇게 잘 작동하는 것처럼 보일가 ? 비법은 두 가지다. 첫 번째, 트랜스포머는 다음 단어를 추측하는데 매우 능숙한 방식으로 단어의 맥락을 혼합하는 배운다. 두 번째, 시스템을 훈련하는 방법에 있다. 대규모 언어 모델은 인터넷에서 스크랩한 방대한 양의 정보를 바탕으로 훈련한다. 여기에는 책, 블로그, 뉴스 사이트, 위키피디아 기사, Reddit 토론, 소셜 미디어 대화가 포함된다. 훈련을 하는 동안 이러한 소스 중 하나에서 텍스트 조각을 입력하고 다음 단어를 추측하도록 요청한다. 결과적으로 LLM은 인터넷에서 합리적으로 나타날 수 있을 법한 텍스트를 생성한다. 단지 많은 글을 읽은 것으로 충분한 추론이 가능할까 라고 생각 할 수 있다. 인터넷의 텍스트가 주제 측면에서 얼마나 다양한지 과소평가하지 않는 것이 중요하다. LLM은 모든 것을 보았다. 거의 모든 주제에 대한 수십억 개의 대화를 보았다. 따라서 LLM은 마치 여러분이 대화를 하는 것처럼 보이는 단어를 만들어낼 수 있다. 수십억의 문제, 수십억의 답변을 보았기 때문에 약간 다르더라도 숙제에 대해서 합리적으로 추측할 수 있다. 수십억의 코드, 수십억의 여행 계획, 수십만개의 논문, 고전, 현대문학 등등... 요점은 이렇다. ChatGPT나 다른 대규모 언어 모델에 "전문가처럼 답변해 주세요"라고 하면 이미 학습한 수십억의 전문가의 답변을 기반으로 전문가처럼 답변할 것이다. "할머니도 이해할 수 있도록 해주세요"라고 하면, 쉽게 풀어서 설명한 수십억의 답변을 기반으로 답을 만들어낼 것이다. 여러분이 어떤 독특한 질문을 하더라도, 그러한 독특한 수많은 질문들로 답을 만들어낼 것이다. LLM과 상호작용 할 때, 우리는 LLM이 정말로 똑똑하고 창의적이다 사람의 감정을 이해한다고 생각 할 수 있을 것이다. "이전에 보았던 대화의 조각을 이어 붙인 것"이라고 생각하고 대화를 할 때 더 좋은 답을 얻을 수 있을 것이다. 하지만 지금의 LLM을 생각해보면 "정말 정교한 추론이 아니더라도" 여전히 매우 유용할 수 있다는 것을 의미할 수 있다. 그리고 LLM은 학습방법 때문에 다소 중간적인 응답을 제공하는 경향이 있다. 시를 짓든지 글을 쓰던지 다른 사람들도 생각했던 적이 있는 응답을 한다는 것을 이해해야 한다. 대부분의 사람은 평균적으로 생각하기 때문이다. # 📚 조심해야 할 것들 트랜스포머가 족동하는 방식과 훈련하는 방식에서 발생하는 미묘한 사항들이 있다. 1. 대규모 언어 모델은 인터넷에서 학습한다. 즉, 인간의 모든 어두운 면에 대해서도 학습을 한다. LLM은 인종 차별적 폭언, 성 차별적 발언, 모든 종류의 모욕, 고정관념, 음모론, 편견 등을 학습했다. 즉 LLM은 어두운 답을 할 수 있다. 2. 대규모 언어 모델은 "신념"이 없다. 이들은 단어 추측자이다. 이들은 어떤 문장이 나타나면 다음 단어가 무엇일지 예측하려고 한다. 따라서 LLM에 무언가를 찬성하거나 반대하는 문장을 쓰라고 요청하면 이들은 답을 한다. 여기에는 신념, 믿음 혹은 무엇이 더 옳은지에 대한 어떤 것을 나타내는 것이 아니다. 훈련 데이터에 더 자주 나타나는 것을 더 일관되게 응답하는 경향이 있다. 왜냐면 인터넷에 자주 나타나기 때문이다. 모델은 가장 일반적인 응답을 모방하려고 한다. 3. 대규모 언어 모델은 옳고 그름에 대한 감각이 없다. 우리의 대부분은 지구는 둥글다고 알고 있기 때문에 LLM도 그렇게 말하는 경향이 있다. 하지만 인터넷에는 지구가 평평하다는 텍스트도 있기 때문에 "상황이 허락한다면" 평평하다는 말을 할 수 있다. LLM이 진실을 제공할 것이라는 보장은 없다. LLM은 알고 있는 것에 대한 주장을 하는 것이지 옳고 그름을 이야기하는 것이 아니다. 4. 대규모 언어 모델은 실수를 할 수 있다. 훈련 데이터에는 일관성이 없는 자료가 많을 수 있다. 셀프 어텐션은 질문을 할 때 원하는 모든 것에 주의를 기울이지 않을 수 있다. 때때로 훈련 데이터에는 특정한 단어가 너무 많아서 입력에 의미가 없더라도 그 단어를 선호할 수 있다. 이는 **환각(hallucination)** 이라는 현상으로 이어진다. 큰 숫자보다는 작은 숫자가 더 일반적이기 때문에 LLM은 작은 숫자를 추측하는 경향이 있다. 따라서 LLM은 수학에 능숙하지 않다. LLM은 단지 42라는 숫자가 인터넷에 많이 등장하기 때문에 42를 선호 할 수 있다. 5. 대규모 언어 모델은 자기 회귀적이다. LLM은 문장을 생성할 때 이전에 생성된 단어들을 기반으로 다음 단어를 예측한다. 그러므로 오류가 누적된다. 오류가 하나만 발생하더라도 그 이후에 나오는 모든 것이 그 오류와 연관될 수 있다. 트랜스포머는 "마음을 바꾸거나" 다시 시도하거나 스스로 수정할 방법이 없다. 그들은 흐름을 따라갈 뿐이다. CoT(Chain of Thought)와 같은 프롬프트 엔지니어링 기법을 이용하여 이러한 문제를 해결할 수 있다. 6. 대규모 언어 모델의 출력을 검증해야 한다. 스스로 검증 할 수 없는 작업을 수행한 경우, 해당 실수에 대해서 조치를 취해야 할지 검토해야 한다. 블로그나 단편 소설을 쓰는 작업의 경우 검증이 필요 없을 수 있다. 하지만 주식 투자에 대한 정보를 얻어야 하는 고위험 작업의 경우에는 검증이 반드시 필요하다 7. Self-Attention은 프롬프트에 더 많은 정보를 제공할 수록 응답이 더 전문화 되는 경향이 있다. 응답의 질은 입력 프롬프트의 질에 정비례한다. 다양한 프롬프트를 시도하라. 모델이 당신 하려는 것을 "이해" 하고 최선을 다할 것이라고 가정하지 말라. 8. 대규모 언어 모델은 실제로 대화를 나누는 것이 아니다. 대화를 하려면 기억을 해야 하는데, 대규모 언어 모델은 "기억"하지 않는다. 때때로 모델이 대화를 나누는 것처럼 보이는데, 이는 기존 대화를 로그로 남겨서 모델에 전송하기 때문이다. 일종의 트릭인 것이다. 이 트릭을 이용하면 주제를 유지할 가능성이 있지만 응답과 모순이 되지 않을 것이라는 보장은 없다. 또한 이전 대화를 로그로 보내다보면 토큰이 커질 수 있다. 토큰이 커질 수록 비용도 커지며 모델이 처리가능한 토큰의 제한이 있기 때문에 로그가 너무 커지면 이전 내용은 "잊어버린다". 9. 대규모 언어 모델은 문제 해결이나 계획을 수행하지 않는다. 하지만 계획을 세워서 문제를 해결하도록 요청할 수는 있다. 대규모 언어 모델은 목표가 없다. 입력 시퀀스가 주어졌을 때 학습 데이터에 가장 많이 나타날 단어를 선택하는 것이 목표다. 계획을 수립하는 것은 **미래에 발생할 결과를 시뮬레이션** 하겠다는 것을 의미한다. Self-Attention은 이미 나타난 입력 단어에만 적용 할 수 있을 뿐이다. 마치 계획을 세워서 푸는 것처럼 보이는 이유는 "이미 많은 훈련 데이터에서 계획을 보았기 때문에, 계획처럼 보이는 출력을 생성"하는 것이다. 계획을 세우기 위해서는 Cot, RL(Reinforcement Learning) 와 같은 프롬프트 엔지니어링을 해야 한다. # 📚 ChatGPT를 특별하게 만드는 것은 무엇인가 ? **RLHF(Feinforcement Learning from Human Feeback)** 을 이용해서 ChatGPT 성능을 개선할 수 있다고 들었습니다 ? 사실인가요 ? ### 명령어 튜닝 대규모 언어 모델에는 한 가지 특별한 문제가 있다. 그것은 단어의 입력 시퀀스를 받아서 다음에 나올 것을 만들어 내고 싶어한다는 것이다. 대부분의 경우에는 그것으로 충분하지만 항상 그런 것은 아니다. 아래 예제를 보자 > 알렉산더 해밀턴에 대한 에세이를 쓰세요. 이에 대한 응답으로 "알렉산더 해밀턴은 1755년 네비스에서 태어났으며 정치가, 변호사, 직업 군인 .."과 같은 답변이어야 한다고 생각 할 것이다. 하지만 아래와 같은 답변을 받을 수 있다. > 논문은 최소 5페이지, 2줄 간격, 최소 2개의 인용문이 포함되어야 합니다. 미리 말하자면 "항상 이런식으로 대답" 한다는 것은 아니다. 제대로 응답하는 것도 많다. 그러한 경향이 나타날 수 있다는 의미다. 이런일이 발생할 수 있는 이유는 LLM이 훈련한 많은 데이터 중에 "여러분 에세이를 쓰셔야 합니다. 에세이는 4페이지 이상이어야 하고, 검증을 위한 인용문도 2개 이상 포함되어야 합니다" 류의 문장이 있기 때문이다. 이를 수정하기 위해서 **명령어 튜닝** 이라는 것을 할 수 있다. 아이디어는 매우 간단하다. 잘못된 응답을 받으면 올바른 응답이 무엇인지 적고 원래 입력과 새로운 수정된 출력을 신경망을 통해 학습 데이터로 보내는 것이다. ### 인간 피드백을 통한 학습 강화 강화학습은 로봇 연구와 가상 게임 플레이 에이전트(체스, 바둑 또는 스타크래프트의 AI 시스템)에서 전통적으로 사용되는 AI 기술이다. 강화학습은 **보상** 이라는 것을 받았을 때 무엇을 해야 하는지 알려주는데 특히 유용하다. 보상은 어떤 일을 잘하고 있는 지를 나타내는 숫자다. 강화학습 시스템은 미래에 얼마나 많은 보상을 받을지 예측한 다음, 더 많은 보상을 받을 가능성이 가장 높은 행동을 선택하려 한다. 이는 사람이 개 간식을 이용해서 개에게 행동을 가르치는 방식과 크게 다르지 않다. 아래의 질문을 생각해보자. > 마크는 어떤 분야의 전문가인가요 ? 모델이 아래와 같이 출력했다고 가정해보자. > 마크는 인공지능, 그래픽, 인간-컴퓨터 상호작용 분야에서 많은 논문을 발표했습니다. 실제 마크는 "그래픽"과 관련된 분야에서 일을 한 적이 없으므로 부분적으로 맞았다고 가정한다. 그렇다면 엄지손가락을 내려서 "-1" 점을 줄 수 있을 것이다. 하지만 그래픽이라는 단어가 문제이지, 문장 전체가 틀린건 아니다. 그래서 이렇게 단순하게 피드백하는 것으로는 개선이 어렵다. 여기에 강화 학습이 등장한다. 강화 학습은 다양한 대안을 시도해서 가장 많은 보상을 받는지를 확인하는 방식으로 작동한다. 원래 프롬프트에 대해서 서로 다른 응답을 생성하도록 요청했다고 가정해보자. > 마크는 인공지능, 그래픽, 인간-컴퓨터 상호작용 분야에서 많은 논문을 발표했습니다. > 마크는 인공지능, 안전한 NLP 시스템, 인간-컴퓨터 상호작용 분야에서 일했습니다. > 마크는 인공지능, 게임 AI, 그래픽 분야를 연구했습니다. 첫 번째 응답에는 -1, 두 번째는 +1, 세 번째는 -1을 줄 수 있다. 우리는 여기에서 -1이 되는 유일한 공통점이 "그래픽"이라는 단어를 알아낼 수 있다. 이제 시스템은 그 단어에 초점을 맞춰서 신경망을 조정하여 특정입력이 해당 단어를 사용하지 않도록 할 수 있다. # 참고 * [A Very Gentle Introduction to Large Language Models without the Hype](https://mark-riedl.medium.com/a-very-gentle-introduction-to-large-language-models-without-the-hype-5f67941fa59e)
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
AI
LLM
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags