Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
클라우드 엔지니어 면접을 위한 지식들 - 데이터베이스 1
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2023-03-22
2023-03-22
5821
 클라우드 엔지니어 면접을 위한 지식들로 "데이터베이스"를 다룬다. 양이 많아서 1,2부로 나눠서 정리하기로 했다. 여기의 정보들은 주요 키워드에 대한 표면적인 설명들이다. 각 키워드들에 대한 깊은 지식들은 실무 혹은 학습을 통해서 쌓아나가야 할 것이다. ## SQL SQL(Structured Query Language)는 관계형 데이터베이스를 관리하는데 사용하는 **프로그래밍 언어**다. 1979년에 Relation Software. Inc(지금의 Oracle)이 상업적으로 사용가능한 최초의 SQL을 구현했으니, 2023년 기준 45년 가까이 된 오래된 언어다. RDBMS라는 특수한 영역에서 사용하고 있지만 RDBMS가 워낙 널리 사용하고 있기 때문에, 지금도 인기 있는 언어다. 아래 그림은 2022년 Stackoverflows의 developer survey 자료인데, 가장 널리 사용하고 있는 언어 중 하나임을 알 수 있다.  SQL을 이용해서 사용자는 레코드 선택, 삽입, 업데이트, 삭제와 같은 데이터베이스에 저장된 데이터에 대한 광범위한 작업을 수행 할 수 있다. 또한 데이터베이스 스키마를 정의하고 인덱스(index)를 생성 관리하며 데이터 무결성 제약 조건등을 적용 할 수 있다. SQL은 Oracle, Microsoft, SQL Server, MySQL, PostgreSQL, SQLite 등 대부분의 주요 RDBMS 소프트웨어 시스템에서 지원하고 있다. SQL의 문법은 아래와 같다. 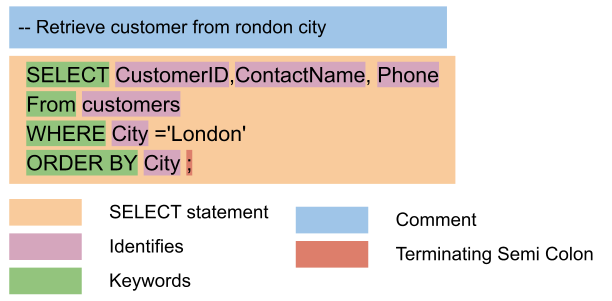 SQL에 대한 자세한 내용은 [SQL Study With MySQL](https://www.joinc.co.kr/w/sql_study_with_mysql_index) 글들을 참고하자. ## Transaction 트랜잭션은 데이터베이스에서 실행되는 논리적인 작업의 단위이다. 트랜잭션은 분할할 수 없는 단일 작업으로 수행되어야 하는데, 이는 모든 변경사항이 적용되거나 적용되지 않아야 함을 의미한다. 데이터베이스 관점에서 트랜잭션은 하나 이상의 테이블에 대한 데이터 삽입, 업데이트, 삭제와 같은 하나 이상의 데이터베이스 작업이 포함될 수 있다. 트랜잭션의 목적은 일련의 작업이 하나의 원자적(atomi) 작업으로 실행되어서 데이터베이스가 일관(consistency)적인 상태로 유지하도록 하는데 있다. 트랜잭션은 하드웨어 또는 소프트웨어 오류가 발생한 경우에도 데이터 무결성을 제공하기 때문에 데이터베이스 시스템에서 중요하게 다룬다. 트랜잭션은 Atomicity, Consistency, Isolation, Durability를 나타내는 ACID를 따라야 한다. ## ACID **ACID**는 Atomicity(원자성), Consistency(일관성) , Isolation(격리), Durability(내구성)의 약자다. 하드웨어 또는 소프트웨어 오류가 발생한 경우에도 데이터베이스 트랜잭션이 안정적이고 일관적으로 처리되도록 하는 속성의 집합이다.  **Atomicity** Atomicity는 전체 트랜잭션이 한번에 발생하거나 전혀 발생하지 않음을 의미한다. 트랜잭션은 부분적으로 성공하거나 실패해서는 안된다. **All or Noting** 즉 중간이 없다. 각 트랜잭션은 하나의 최소단위로 간주되며 완료될때까지 실행되거나 실행되지 않거나의 두 가지 상태 중 하나만 가질 수 있다. 트랜잭션은 아래의 두 가지중 하나의 작업상태를 가질 수 있다. - Abort : 트랜잭션이 중단되면 데이터베이스가 변경되지 않는다. 즉 트랜잭션 실행 이전의 상태가 된다. - Commit : 트랜잭션이 커밋되면 변경내용이 표시된다. Account - A 에서 Account - B로 100을 이체한다고 가정해보자.  이 트랜잭션은 T1과 T2 두개의 작업(쿼리)로 이루어진다. 만약 T1이 성공했는데 T2가 실패했다면, Account - A에서는 100이 차감되지만, Account - B에 추가되지 않게 된다. 결국 데이터베이스의 일관성이 깨질 것이다. 따라서 트랜잭션 전체를 실행하거나 실행하지 않아야 한다. **Consistency** Consistency는 트랜잭션 전후의 일관성이 유지되도록 무결성 제약조건이 유지되어야 함을 의미한다. 이는 데이터베이스의 정확성을 나타내는 요소이기도 하다. 위의 이체 예제를 보면 "**트랜잭션 전후의 총액이 일치**"해야 한다. 1. T가 발생하기 전 합계 : 700 2. T가 발생한 후 합계 : 700 으로 트랜잭션 전후의 총액이 일치하므로 이 데이터베이스는 일관성이 있다. 트랜잭션이 Atimic 하지 않아서, T1이 완료했지만 T2가 실패했다면 일관성이 깨질 것이다. **Isolation** 이 속성은 데이터베이스의 상태의 불일치 없이 여러 트랜잭션이 동시에 실행되도록 한다. 이를 위해서는 트랜잭션이 다른 트랜잭션의 간섭없이 독립적으로 발생해야 한다. 특정 트랜잭션에서 발생하는 변경사항은 해당 트랜잭션이 완료되기 전까지는 다른 트랜잭션에서 볼 수 없는데, 결과적으로 트랜잭션이 "직렬로(순차적으로)" 실행된 것과 같은 상태가 된다. **Durability** 이 속성은 트랜잭션 실행이 완료되면 시스템에 오류가 발생하더라도 변경이 없이 읽을 수 있어야 함을 의미한다. 이러한 업데이트는 영구적인 비휘발성 메모리(디스크)에 저장되어서 트랜잭션의 효과가 사라지지 않도록 한다. ## CAP 이론 **CAP 이론**은 분산저장소가 제공해야하는 세가지 기능에 대한 이론이다. * 일관성(Consistency): 다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증 * 가용성(Availability): 모든 클라이언트의 읽기와 쓰기 요청에 대해서 항상 응답이 가능해야 함을 보증 * 네트워크 파티션 허용(Partition tolerance): 분할된 네트워크 환경에서 동작하는 시스템에서 네트워크가 단절되거나 네트워크 데이터가 유실되더라도 각 지역내에서 시스템이 정상적으로 작동함 정상적인 환경에서 데이터 저장소는 위의 3가지 기능을 모두 제공해야 할 것이다. 하지만 CAP은 분산 환경에서 네트워크 오류가 발생할 경우 일관성 혹은 가용성을 모두 제공할 수 없다는 이론이다. 즉 네트워크 오류가 발생할 경우 무엇을 우선해서 제공해야 할지에 대한 Trade-off를 고민해서 설계해야 한다는 의미다. CAP 이론에서 네트워크 파티션 허용은 필수다. 따라서 네트워크 장애가 발생할 경우 C와 A사이에서 무엇을 희생할지를 결정해야 한다. * 높은 일관성은 가용성을 희생해야 한다. * 고가용성은 일관성을 희생해야 한다. 데이터베이스 시스템은 그 특성에 따라서, CAP의 어느 요소를 만족하는지가 대략적으로 결정된다.  대략 SQL(RDBMS)는 강력한 일관성과 고가용성을 제공한다. NoSQL의 경우 분산 시스템으로 구성하는 경우가 많기 때문에 일관성과 가용성 사이에서 Trade-off 하는 경우가 많다. ## RDBMS **관계형 데이터베이스 관리 시스템(Relational Database Management System)** 이라고 부르는 RDBMS는 관계형 데이터베이스를 관리하는 소프트웨어다. **관계형 데이터베이스**는 하나 이상의 테이블에 저장된 데이터들이 서로 연결된 정보구조를 의미한다. 여기에서 **연결** 이란 테이블 간의 상호작용을 기반으로 설정되는 테이블들 간의 논리적 연결이다. 온라인에서 제품을 판매하는 회사에서 사용하는 관계형 데이터베이스의 예를 살펴보자. 이 데이터베이스는 아래의 테이블을 포함할 것이다. * Customer table(고객 테이블): 이 테이블에는 이름, 주소, 이메일, 전화번호 같은 고객 정보가 들어간다. 각 고객에게는 **고유한 고객 ID**가 할당된다. * Order table(주문 테이블): 이 테이블에는 주문 ID, 주문 날짜, 주문한 **제품의 ID** 그리고 주문한 **고객의 ID** 정보가 들어간다. * Products table(제품 테이블): 이 테이블에는 **제품 ID**, 제품 이름, 단위 가격 재고 수량, 판매회사 정보가 들어간다. * Company table(판매회사 테이블): 이 테이블에는 **회사 ID**, 이메일, 주소와 같은 판매회사 정보가 들어간다. 이들 4개의 테이블은 "고객 ID", "제품 ID", "회사 ID"로 서로 연결(relation)된다. 이 구조는 아래와 같이 묘사할 수 있을 것이다.  이렇게 특정 **컬럼의 데이터(Primary Key와 foregin Key)** 를 이용해서 서로 관계를 만들어서 데이터를 입력하거나 조회할 수 있다. 예를 들어 어떤 주문을 어떤 고객이 요청했는지 확인하기 위해서는 orderID로 주문을 조회하고 customerID로 고객정보를 조회해서 확인할 수 있다. RDBMS에서는 **JOIN**을 이용해서 하나 이상의 테이블로 부터 데이터를 결합할 수 있다. RDBMS는 **SQL**을 이용해서 데이터베이스, 테이블을 관리 및 조회 한다. Oracle, MySQL, PostgreSQL, SQL Server, SQLite 등의 RDBMS 소프트웨어들이 있다. ## SQL vs NoSQL 2010년 정도까지 데이터베이스 관리시스템은 SQL기반의 RDBMS만을 사용하는 경우가 많았다. 혹은 캐시를 목적으로 **REDIS**를 함께 사용하는 정도였다. 하지만 2010년 이후 RDBMS와는 다른 특성을 지닌 데이터베이스가 등장했는데, 이들은 SQL을 사용하지 않는 데이터베이스 시스템이라고 하여 **NoSQL**로 부르고 있다. 설명을 편하게 위해서 RDBMS는 앞으로 **SQL** 이라고 부르도록 하겠다. **NoSQL**의 주요 특징들은 아래와 같다. * 확장성: 수직확장(Scale up)으로 처리 용량을 늘리는 SQL과 달리, NoSQL은 수평확장(Scale out)하도록 설계되었다. 즉 데이터와 트래픽이 증가하면, 노드(컴퓨터 시스템(의 사양을 높이는게 아니고 더 많은 노드를 추가하여 확장하는 방식이다. 수평 확장은 수직확장에 비해서 처리용량의 증/감에 더 쉽고 빠르게 대응 할 수 있다는 장점이 있다. * 성능: SQL 솔류션은 서로 다른 제품이라고 하더라도 컬럼과 행으로 이루어진 테이블이라는 스토리지 모델을 공통으로 사용한다. 하지만 NoSQL은 다양한 스토리지 모델을 사용하기 때문에 데이터의 크기와 속성에 따라서 최적화된 스토리지 메커니즘과 캐싱 기능등을 제공하는 NoSQL 솔류션을 사용해서 성능을 최적화 할 수 있다. 또한 NoSQL은 분산 아키텍처 모델을 기반으로 높은 성능을 달성할 수 있다. * 유연성: NoSQL은 **비정형, 반정형, 정형**에 대한 유연한 데이터 모델을 제공하고 있어서, 다양한 비즈니스에 적용 할 수 있다. * 가용성: NoSQL은 주로 수평확장 모델을 사용하는데, 여러대의 노드로 구성되기 때문에 더 높은 내구성, 장애대응 및 장애복구, 내결함성, 가용성을 제공한다. NoSQL은 인터넷 서비스가 성장하고 다양해짐에 따라서 기존의 SQL 솔류션으로는 해결하기가 어려운 문제점들을 쉽게 해결하기 위해서 등장했다. 이런 이유로 NoSQL은 소셜 미디어, IoT, 전자상거래와 같이 대량의 비정형 데이터를 처리하는 애플리케이션에서 널리 사용하고 있다. 오해하지 말아야 할 것이 있는데 NoSQL은 SQL을 대체하는 기술이 아니다. NoSQL의 채택이 늘어나는 것과는 별개로 SQL은 앞으로도 계속 핵심 데이터베이스 시스템으로 사용 될 것이다. #### SQL 데이터베이스를 사용하는 경우 SQL 데이터베이스는 구조화된 데이터를 저장하는데 적합하다. 관계형 데이터베이스는 트랜잭션 작업에 최적화되어 있다. 트랜잭션은 종종 여러 테이블에서 여러개의 레코드를 업데이트해야 하는데, **ACID**를 만족하면서 짧은시간에 빈번한 쓰기 작업에 최작회되어 있다. * Atomic(원자성): 여러 행을 업데이트하는 트랜잭션은 "단일 단위(single unit)"로 처리된다. 성공적인 트랜잭션은 모든 업데이트가 완료된 상태를 의미한다. 업데이트 작업 중 하나라도 실패한다면 트랜잭션은 업데이트를 수행하지 않는다. 즉 **데이터베이스를 변경되기 전 상태**로 유지한다. * Consistency(일관성): 일관성은 데이터베이스 상태가 일관되어야 하는 성질이다. 일관성은 트랜잭션이 발생한 이전과 이후의 상태가 이전과 같이 유효해야함을 의미한다. * Isolation(격리): 여러 트랜잭션을 동시에 실행하더라도 트랜잭션이 순차적으로 실행된 것처럼 데이터베이스가 동일한 상태로 유지된다. * Durability(내구성): 커밋된 트랜잭션은 영구적이며 시스템 충돌에서도 유지된다. #### NoSQL 데이터베이스를 사용하는 경우 NoSQL 데이터베이스는 Key-Value, 문서(Document), 그래프(graph), Column등 다양한 데이터 유형을 가지고 있으므로 각각에 대한 설명이 필요하다. **Key-Value 데이터베이스** Key-Value 데이터베이스는 사전 또는 해시 테이블 방식의 데이터베이스다. 각 레코드는 고유한 key를 이용해서 CRUD 작업을 수행하도록 설계되었다. * Create(key, value): 데이터 자장소에 키-값을 추가한다. * Read(Key): Key에 저장된 값을 읽는다. * Update(key, value): Key에 저장된 값을 업데이트 한다. * Delete(key): 데이터 저장소에서 (key, value) 레코드를 삭제한다. Key-Value 저장소의 경우 Key값을 이용해서 샤딩이 가능하기 때문에 수평확장이 쉽다. 가장 인기있는 Key-Value 저장소는 **Redis**다. **Document 데이터베이스** 문서 저장소는 중첩된 개체로 구성된 문서를 저장하고 검색하기 위해서 사용한다. XML, JSON 및 YAML과 같은 트리구조를 가진다. 문서 데이터베이스는 기본적으로 "문서의 이름-문서의 내용"이 저장되기 때문에 Key-Value 저장소와 비슷한 측면이 있다. 하지만 문서 데이터베이스는 문서에 대한 다양한 작업이 가능하게 하며, 문서의 트리 구조를 만들 수 있다는 차이가 있다. 가장 인기있는 문서 데이터베이스로 MongoDB가 있다. **Wide-column 데이터베이스** Wide column 데이터베이스는 column의 네임이나 포맷이 열(row)마다 다를 수 있는 데이터베이스다. Apache HBase는 최초의 오픈 소스 wite-column 데이터 저장소다. **Graph 데이터베이스** 문서 저장소와 비슷하지만 트리 구조 대신 그래프 구조를 만들 수 있도록 설계되었다. Graph 데이터베이스는 소셜 네트워크등 "관계"가 중요한 요소인 데이터를 저장하는데 적합하다. **Neo4j**는 유명한 그래프 데이터베이스이며, **Redis**도 그래프 데이터 저장을 지원한다.  **데이터베이스 종류** 아래 다양한 종류의 데이터베이스를 정리했다. 참고하자. | | AWS | Azure | Google | Cloud Agnostic | | ---------------- | -------------- | ------------------------- | ------------------------- | ----------------------------------------------- | | RDBMS | RDS, Aurora | Azure SQL Database | Cloud SQL, Cloud Spanner | SQL Server, Oracle, MySQL, PostgreSQL | | Columnar | RedShift | Azure Synapse | BigQuery | Snowflake, Druid, Pinot, ClickHouse, Databricks | | Key-Value | DynamoDB | Cosmos DB | BigTable | Redis, ScyllaDB, Ignite | | In-Memory | ElastiCache | Azure Cache for Redis | Memorystore | Redis, Memcached, Hazelcast, Ignite | | Wide Column | Keyspaces | Cosmos DB | BigTable | HBase, Cassandra, ScyllaDB | | Times Series | Timestream | Cosmos DB | BigTable, BigQuery | TimescaleDB, OpenTSDB, InfluxDB | | Immutable Ledger | Quantum Ledger | Azure SQL Database Ledger | | Hyperledger Fabrid | | Geospatial | Keyspaces | Cosmo DB | BigTable, BigQuery | Solr, PostGIS, MongoDB | | Graph | Neptune | Cosmos DB | JanusGraph + BigTable | OrientDB, Neo4J | | Document | DocumentDB | Cosmos DB | Firestore | MongoDB, Couchbase, Solr | | Text Search | OpenSearch | Cognitive Search | Search APIs on Datastores | ElasticSearch, Solr | | Blob | S3 | Blob Storage | CloudStorage | HDFS, MiniO | ## OLTP, OLAP 데이터 베이스 시스템은 다루고자 하는 데이터의 읽기/쓰기 틍성에 따라서 크게 **OLTP**와 **OLAP**로 나눈다. 우리의 실생활에서도 즉각 적으로 읽고, 쓰고, 수정하고, 지워야 하는 데이터가 있는 반면 분석을 위해서 가끔 읽기만 하는 종류의 데이터가 있는 것과 마찬가지다. 복잡하게 생각할 필요 없다. 즉각적으로 읽고, 쓰고, 수정해야 하는 데이터베이스 시스템은 **OLTP** 이고, 분석을 위해서 대량의 데이터를 읽기 위한 목적으로 사용하는 데이터베이스 시스템이 **OLAP**이다. #### OLTP **OLTP(Online Transaction Processing)** 는 대량의 온라인 트랜잭션을 실시간으로 처리할 수 있도록 설계된 데이터베이스 시스템이다. OLTP는 금융 거래, 전자 상거래, 재고 관리 등 즉각적인 처리가 필요한 곳에 적당하다. OLTP는 다양한 실시간 트랜잭션을 빠르게 처리해야 하기 때문에 일반적으로 복잡한 쿼리를 지원하고 높은 수준의 데이터 일관성을 제공하도록 설계되어서 데이터가 항상 최신상태로 정확하게 유지될 수 있도록 한다. OLTP의 특징은 아래와 같다. 1. 빈번한 쿼리 처리: OLTP 데이터베이스에서 빈번한 데이터 삽입, 업데이트, 삭제는 일상적인 작업이다. 2. 빠른 트랜잭션: 짧고 빈번한 거래를 빠르게 처리하여 최신 정보를 유지한다. 3. 데이터 무결성: 장애가 발생할 경우 롤백을 이용해서 데이터 무결성과 일관성을 유지한다. 최소한 3NF까지의 데이터베이스 정규화로 정보 흐름의 안정성을 유지한다. 아래 예제는 OLTP가 적합한 서비스 사례를 설명하고 있다. 1. 은행 및 금융 서비스: 고객이 실시간으로 온라인으로 자금을 이체하고 잔액을 확인하고 청구서를 지불할 수 있는 시스템 2. 전자 상거래: 상품의 주문, 재고 관리, 배송을 처리하는 온라인 소매 시스템 3. 의료 서비스: 환자 정보, 예약 및 청구를 관리하는 의료 서비스 시스템. 4. 물류 및 운송: 재고를 관리하고 배송을 추적하고 결제하는 시스템. 일반적으로 대량의 트랜잭션을 온라인으로 처리하고 실시간으로 접근해야 하는 비즈니스 혹은 조직에서는 OLTP를 검토한다. #### OLAP **OLAP(Online Analytical Processing)** 은 OLTP 시스템에서 수집한 데이터를 분석하는 목적으로 준비되는 시스템이다. OLAP의 특징은 다음과 같다. 1. 더 적은 수의 쿼리: 더 적은 수의 쿼리 작업을 수행한다. 반면 다차원적인 데이터 작업이 많다. 2. 복잡한 트랜잭션: 대량의 과거 데이터에 대한 분석 작업을 수행한다. 의사결정을 지원하기 위해서 복잡한 쿼리를 신속하게 실행하는데 중점을 둔다. 3. 쿼리 속도: 데이터베이스 쿼리 속도를 향상시키기 위해서 데이터 비정규화(Data denormalization) 작업을 수행한다. 정보검색이 빠른대신이 데이터 불일치가 존재할 수 있다. 아래는 OLAP의 사용사례다. 회사에서 지난 1년동안의 판매 데이터를 분석하려한다고 가정해보자. OLAP를 사용하여 제품별, 지역별, 기간별, 고객 세그먼트별 다양한 차원에서 판매 데이터를 분석하고 레포트를 작성할 수 있다. 또한 수익, 이익, 판매수량과 같은 다양한 척도를 사용하여 데이터를 분석할 수 있다. 전반적으로 OLAP는 복잡한 데이터 세트를 분석하고 이해하기 위해서 사용한다. #### OLTP와 OLAP의 통합 OLTP와 OLAP는 서로 다른 유즈 케이스를 가지는 데이터베이스이지만 빅데이터가 부상하면서, 서로 통합하면서 사용하고 있다. 이 두 시스템은 ETL(추출, 변환, 로드)의 과정으로 연결되때 효과적으로 작동한다.  아래 OLTP와 OLAP의 차이점을 정리했다. | | OLTP | OLAP | | --------------------- | ---------------------------- | ----------------------------- | | 기능 | 빈번한 데이터의 읽기 및 쓰기 | 데이터 쿼리, 거의 쓰이지 않음 | | 특징 | 짧은 대기 시간 | 높은 처리량 | | 쿼리 | INSERT, UPDATE, DELETE | SELECT | | 쿼리 복잡성 | 간단하고 표준화 | 복잡하고 전문화 | | 표준화 | 정규화 | 비정규화 | | 데이터베이스 아키텍처 | 전오적인 | 데이터웨어 하우스 | | 설계 | 산업 지향 | 주제 지향 | | 데이터 중복 | 낮음 | 높음 | | 가용성 | 고가용성 | 낮은 가용성 | | 스토리지 크기 | 보관되는 데이터는 작음 | 대형 데이터베이스 서버 | | 사용자 수 | 수만, 수십만 이상 | 수백 | | 성능지표 | 트랜잭션 처리량 | 쿼리 처리량 | | 응답 시간 | 밀리초 | 초에서 분 | | 사용 | 대량의 일반적인 비즈니스 | 의사결정, 분석, 계획 | ## ETL ETL은 Extract, Transform, Load의 약자로 서로 다른 소스에서 원시 데이터를 수집하고 이를 변환하여서 대상 데이터베이스 혹은 데이터 웨어하우스로 로드하는 프로세스를 나타낸다. 즉 "원하는 정보를 얻기 위해서 여러 데이터를 수집하고 변환,가공해서 새로운 데이터베이스에 로드하는 과정"이다. 아래는 ETL의 각 프로세스에 대한 간단한 설명이다. 1. Extract(추출): 데이터베이스, 파일, API, 웹 서비스등 다양한 소스에서 데이터를 추출한다. 소스가 다양한 만큼 데이터의 형식과 구조가 다를 수 있기 때문에 이들 데이터를 일관된 형식으로 추출해야 한다. 2. Transform(변환): 데이터를 정리, 검증하고 대상 시스템에 적합한 형식으로 변환해야 한다. 이 과정에서 데이터 정규화, 데이터 정리, 강화, 데이터 통합 등의 작업을 수행한다. 3. Load(로드): 변환된 데이터를 대상 데이터베이스 또는 데이터 웨어하우스에 로드하고 BI(Business intelligence) 및 의사결정 분석 목적으로 사용할 수 있다. ETL의 일반적인 프로세스는 아래와 같다.  조직이 가지고 있는 데이터의 형태와 솔류션을 이용해서 위의 프로세스를 따르는 ETL 시스템을 구축하면 된다. 아래는 AWS의 GLUE를 이용한 ETL의 과정을 보여주고 있다.  전자 상거래를 예로 들어서 위의 ETL을 설명해보기로 했다. **ETL Extract** 조직의 비즈니스를 분석하기 위해서는 다양한 데이터 소스로 부터의 다차원 분석이 필요할 수 있다. 전자상거래의 경우 초당 수백건의 주문이 들어온다. 또한 수백만의 사용자 정보, 배송정보, 주간 및 월간 매출보고서 등 많은 양의 서로 다른 형식의 데이터가 생산된다. ETL 인프라는 새로운 정보를 저장할 수 있는 스테이징 스토리지를 준비하고 있어야 한다. 위 아키텍처에서는 S3를 스테이징 스토리지로 사용하고 있다. 수신되는 데이터의 크기, ETL 프로세스를 실행해야 하는 배치 일정에 따라서 AWS Lambda, AWS Glue를 이용해서 배치 작업을 수행 할 수 있다. **ETL Transform** 입력되는 데이터의 변환작업은 배치로 실행되는 무거운 작업이다. 이러한 작업을 처리하기 위해서는 분산 빅데이터 솔류션이 필요한데, 위 아키텍처에서는 GLUE를 사용하고 있다. AWS Glue는 테라바이트급 RAM과 수백에서 수천까지의 worker로 확장할 수 있는 서버리스 클러스터를 기반으로 하는 분산 처리 시스템을 제공한다. **ETL Load** ETL Transform 과정을 거치는 이유는 비즈니스에서 사용 할 수 있는 "깨끗하고 정제된" 데이터를 얻기 위함이다. 이러한 데이터는 Amazon QuickSight, Tableau 와 같은 BI 툴을 이용해서 분석 및 시각화를 할 수 있다.
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
architecture
aws
cloud
database
devops
클라우드 엔니지어 면접을 위한 지식들
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags