Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
AWS 솔류션 아키텍트 어소시에이트 등급 문제 풀이
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2022-08-13
2021-02-24
6761
### Question #1 한 회사는 온 디맨드 EC2 인스턴스 및 MongoDB 데이터베이스의 Auto Scaling 그룹에 배포될 데이터 분석 애플리케이션을 AWS에 구축 할 계획이다. 데이터베이스는 소규모의 임의 I/O 작업을 수행하는 높은 처리량의 워크로드가 필요할 것으로 예상된다. 솔류션 아키텍트는 최적의 시스템을 구성해야 한다. 1. Provisioned IOPS SSD (io1) 2. General Purpose SSD (gp2) 3. Throughput Optimized HDD (st1) 4. Cold HDD(sc1) #### 설명 핵심 키워드는 1. 소규모의 임의 I/O 작업을 수행하는 2. 높은 처리량 이다. "높은 처리량"에서 높음은 상대적이다. io1은 1,000 MiB/s이고 처리량에 비해서 최적화된 HDD는 5,00 MiB/s이지만 Cold HDD의 250MiB/s 보다는 높다. * io1 : 1,000MiB/s * HDD : 500MiB/s 적당한 솔류션을 선택하기 위해서는 "소규모의 임의 I/O 작업을 수행하는" 조건을 검토해야 한다. * io1 : 밀리초 미만의 지연시간, 지속적인 IOPS * HDD : 데이터웨어 하우스, 빅데이터와 같이 I/O 작업이 크고 순차적인 경우.  프로비저닝된 IOPS SSD(io1) 볼륨은 스토리지 성능과 일관성이 필요한 I/O 집약적 워크로드에 적당하다. 특히 데이터베이스 워크로드에 적합하도록 설계되었다. 성능 개선을 위해 버킷 및 크레딧 모델을 사용하는 gp2와는 달리 일관된 IOPS 속도를 지정 할 수 있으며 IOPS 10% 내외에서 일관성을 제공한다. 답 : 1 ### Question #2 한 미디어 회사에서는 뉴스 웹 사이트를 호스팅하기 위해 Fargate 유형을 사용하는 Amazon ECS 클러스터를 유지하고 있다. 엄격한 보안 준수를 충족하기 위해서 환경 변수를 사용하여 데이터베이스 자격 증명을 제공해야 한다. 솔류션 아키텍트는 자격 증명이 안잔한지, 일반 테스트로 노출되지 않는 지 등을 확인해야 한다. 최소의 노력으로 구현 할 수 있는 솔류션은 무엇인가 ? * Use the AWS Secrets Manager to store the database credentials and then encrypt them using AWS KMS. Create resource-based policy for your Amazon ECS task execution role taskRoleArn and reference it with your task definition which allows access to both KMS and aWS Secrets Manager. Within your container definition, specify secrets with the name of the environment variable to set in the container and the full ARN of the secrets manager secret which contains the sensitive data, to present to the container. * Use the AWS Systems Manager Parameter Store to keep the database credentials and then encrypt then using AWS KMS. Create an IAM Role for your Amazon ECS task execution role(taskRoleArn) and reference it with your task definition, which allows access to both KMS and the Parameter Store. Within your container definition, specify secrets with the name of the environment variable to set in the container and the full ARN of the Systems Manager Parameter Store parameter containing the sensitive data to present to the container. * Store the database credentials in the ECS task definition file of the ECS Cluster and encrypt it with KMS. Store the task definition JSON file in a private S3 bucket and ensure that HTTPS is enabled on the bucket to encrypt the data in-flight. Create an IAM role th the ECS task definition script that allows access to the specific S3 bucket and then pass the --cli-input-json parameter when calling the ECS register-task-definition. Reference the task definition JSON file in the S3 bucket which contains the database credentials. * In the ECS task definition file of the ECS Cluster, store the database credentials using Docker Secrets to centrally manager these sensitive data ans securely transmit it to only those containers that need access to it. Secrets are encrypted during transit and at rest. A given secret is only while those service tasks are running. #### 설명 AWS Secrets Manager는 애플리케이션 서비스, IT 리소스에 액세스 할 때 필요한 보안 정보를 보호하기 위해서 사용한다. 데이터베이스 자격증명, API 키 및 다른 보안 정보를 손쉽게 교체, 관리 및 검색 할 수 있다. 사용자 애플리케이션에서 Secret Manager API를 호출하여 보안 정보를 검색 할 수 있으므로, 민감한 정보를 평문으로 하드코딩 할 필요가 없다. AWS 시스템 관리자 Parameter Store는 구성 데이터 관리 암호 과리를 위한 계층적 스토리지를 도입한다. 암호, 데이터베이스 문자열, AMI IDs 및 라이선스 코드와 같은 데이터를 파라미터 값으로 저장 할 수 있다. 값은 일반 텍스트 혹은 암호화된 데이터로 저장 할 수 있다. 아래는 시스템 관리자 Parameter Store를 이용한 구성을 묘사하고 있다.  옵션 : 데이터베이스 자격 증명을 ECS 작업 정의 파일에 저장하고 KSM로 암호화한다. 작업 정의 JSON 파일을 Private S3 버킷에 저장하고 HTTPS로 통신하게하는 방법이 있다. 이 S3 버킷에 대해서 ECS task script가 접근 할 수 있도록 IAM 역할을 설정하고 ECS register-task-definition을 호출 할 때 --cli-input-json 파라미터를 전달 한다. 솔류션이 작동하기는 하지만 S3에는 민감한 자격 증명을 전달하지 않는 것이 좋기 때문에, 이 방법은 그다지 좋은 방법이 아니다. 동일한 일을 Secrets Manager, Parameter Store를 사용해서 단순화 할 수 있기 때문에 이 방법을 선택할 필요는 없다. 옵션 : Secret Manager는 기능적으로 Parameter Store과 매우 비슷해서 선택에 고민을 했을 것이다. Secrets Manager를 사용해서 데이터베이스 자격증명을 저장하고 KMS로 암호화 할 수 있다. ECS에 taskRoleArn에 대한 리소스 기반 정책을 생성하고 KMS 및 AWS Secret Manager에 대한 액세스를 허용하도록 정의 한다. 컨테이너 정의내에 컨테이너에 설정할 환경 변수의 이름과 민감한 데이터를 포함하는 Secrets Manager의 전체 ARN이 노출 되기 때문에 좋은 방법이 아니다. 이 경우에는 리소스 기반 정책 보다는 역할 기반 정책이 보다 적합하다. 답 : 2 ### Question #3 여행 사진 공유 웹 사이트는 Amazon S3를 사용하여 웹 사용자에게 고품질 사진을 제공하고 있다. 며칠 후, 관리자는 사이트의 사진을 사용하는 다른 여행 웹 사이트가 있다는 사실을 발견했다. 이로 인해 비즈니스에 재정적 손실이 발생했다. 이 문제를 완화하는 가장 효과적인 방법은 무엇인가. 1. S3 버킷을 public에서 읽을 수 없게 하고 만료시간을 가지는 pre-signed URL을 만든다. 2. NACL을 이용해서 특정 IP를 블럭한다. 3. CloudFront로 사진을 배포한다. 4. Amazon WorkDocs에 고품질 사진을 저장하고 비공개로 한다. #### 설명 기본적으로 S3 버킷은 비공개이며, 명시적으로 액세스 권한이 부여된 사용자만 액세스 할 수 있다. 고품질 사진은 이 조직의 중요 자산이므로 비공개로 해야 한다. 비공개 버킷에 있는 객체를 공유하는 경우에는 사전 서명된 URL(Pre-signed URL)을 만들어서 객체에 대한 한시적 액세스 권한을 부여 할 수 있다. * IP 주소는 계속 바뀌기 때문에 NACL도 효율적인 방법이 아니다. * CloudFront는 고객에게 컨텐츠를 빠르게 전달하는 것을 목표로 한다. 이 경우에는 올바르지 않다. CloudFront에 사전 서명된 URL을 적용했다면, 이 역시 답이 될 수 있을 것이다. * WorkDocs는 문서 협업 서비스다. 사전 서명된 URL의 작동 방식은 아래와 같다.  1. 사용자가 파일을 요청한다. 2. Application 서버는 S3 API를 호출한다. 3. S3는 TTL을 가진 pre-signed 된 URL을 리턴한다. 4. Pre-signed URL은 사용자에게 전송된다. 5. 사용자는 Pre-signed URL로 S3 객체에 접근한다. 컨텐츠에 대한 인증/권한은 "S3 사전 서명된 URL", "CloudFront 사전 서명된 URL", "OAI(Origin Access Identity)"가 있다. **S3 사전 서명된 URL** * 기본적으로 S3 버킷과 객체는 비공개다. 사전 서명된 URL은 객체 소유자의 보안 자격증명을 사용하여 다른 사람에게 객체를 다운로드하거나 업로드 할 수 있는 제한 시간을 가지는 권한을 부여한다. * 사전 서명된 URL을 만들기 위해서 객체 소유자는 아래의 정보를 제공해야 한다. * 보안 자격 증명 * S3 버킷 이름 * 객체 키 * HTTP 메소드 * URL의 만료 날짜 및 시간 **CloudFront 서명된 URL** * CloudFront 엣지 캐시의 파일에 대한 액세스와 Amazon S3 버킷의 파일에 대한 액세스를 제어 할 수 있다. * 사용자가 서명된 URL 혹은 서명된 쿠키를 사용하여 파일에 액세스 하도록 CloudFront를 구성할 수 있다. 서명된 URL 혹은 쿠키를 인증된 사용자에게 배포하도록 응용 프로그램을 개발한다. * 오리진이 Amazon S3 버킷인지 HTTP 서버인지에 관계없이 모든 CloudFront 배포에 서명된 URL 또는 서명된 쿠키를 사용 할 수 있다. **OAI** * S3 버킷을 CloudFront의 오리진으로 구성 할 수 있다. OAI를 이용하면 S3 URL을 사용해서 S3 파일을 볼 수 없도록 할 수 있다. 사용자는 CloudFront URL을 통해서 접근해야 한다. 답 : 1 ### Question #4 <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">솔류션 아키텍트는 EC2 인스턴스가 SSH 연결을 통해서 110.238.98.71 에서만 액세스 할 수 있도록 해야 한다. 어떻게 구성해야 하는가.</span> 1. Security Group Inbound Rule : UDP, 22, 110.238.98.71/0 2. Seucrity group Inbound Rule : UDP, 22, 110.238.98.71/32 3. Security Group Inbound Rule : TCP, 22, 110.238.98.71/32 4. Security Group Inbound Rule : TCP, 22, 110.238.98.71/0 답 : 3 ### Question #5 <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">조직은 온-프레미스 네트워크에서 AWS로 데이터를 마이그레이션 하기 위해서 영구 블록 스토리지 볼륨을 가진 EC2 인스턴스를 프로비저닝해야 한다. 스토리지 볼륨에 필요한 최대 성능은 64,000 IOPS다. 이 시나리오의 요구를 충족하는 솔류션을 선택하라.</span> 1. Store volume을 사용하는 EC2 인스턴스를 사용하여 최대 IOPS 성능을 얻는다. 2. Nitro-based EC2 인스턴스를 실행하고 64,000 IOPS 성능을 가지는 Provisioned IOPS SSD EBS(io1)을 연결한다. 3. 타입에 상관없이 EC2 인스턴스를 실행하고 64,000 IOPS 성능을 가지는 Provisioned IOPS SSD EBS를 연결한다. 4. Amazon EFS 파일 시스템과 Nitro Amazon EC2 인스턴스를 실행한다. #### 설명 Store volume은 EC2 인스턴스에 물리적으로 연결되며, 빠른 성능을 보여준다. 하지만 영구 블록 스토리지를 제공하지 않으므로 틀린 답이다. Provisioned IOPS SSD는 64,000 IOPS의 성능을 제공한다. AWS Nitro System은 최신 세대의 EC2 인스턴스를 위한 기본 플랫폼으로 더 낮은 비용으로 더 빠른 속도를 사용 할 수 있다. 이러한 성능 향상은 EBS 최적화 인스턴스에도 영향을 준다. 스토리지 집약적 워크로드의 경우 더 작은 인스턴스 크기로 더 나은 성능을 달성 할 수 있다. Nitro 기반 EC2가 아닌 경우에는 32,000 IOPS 이상을 보장 할 수 없기 때문에 2가 답이다. Amazon EFS와 Nitro 기반 EC2 를 조합할 경우 64,000 IOPS 이상을 제공 할 수 있으나 블록스토리지가 아니기 때문에 오답이다.  답 : 2 ### Question #6 <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">한 회사가 프러덕션 환경에서 사용되는 모든 AWS 리소스에 대한 IT 감사를 실시했다. 감사 활동 중에 애플리케이션에 표준 및 예약된 EC2 인스턴스 조합을 사용하고 있다는 사실이 확인되었다. 그들은 더 저렴한 스팟 EC2 인스턴스를 사용해야 한다고 주장하고 있다.</span> <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">표준 및 예약 EC2 인스턴스를 사용해야 하는 근거를 설명하라.(2개)</span> 1. 일, 주, 월 단위로 반복적으로 수행하는 작업에 대해서 예측 되는 용량 만큼을 실행할 수 있다. 2. 예약 인스턴스는 수요를 충족하기 위한 사용하지 않는 EC2 인스턴스가 충분하지 않을 때도 (Spot 인스턴스와 달리) 중단되지 않는다. 3. 일정 기간 동안 여러 가용 영역 및 여러 AWS 리전에서 Amazon EC2 인스턴스의 용량을 예약 할 수 있다. 4. 고객 전용의 하드웨어 VPC에서 실행된다. 5. 표준 예약 인스턴스는 나중에 다른 전환 형 예약 인스턴스로 전환할 수 있다. #### 설명 <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">예약된 인스턴스를 사용하면 온-디멘드 요금에 비해서 상당한 할인(최대 75%)를 제공한다. RI는 3가지 유형을 제공한다.</span> * 표준 RI(Standard RIs) : 가장 큰 할인 혜택(온디맨드 대비 최대 72%)를 제공한다. 꾸준한 사용량을 예상 할 수 있을 때 적합하다. * 컨버터블 RI(Convertible RIs) : 온디맨드 대비 최대 54%의 할인을 제공한다. RI의 속성을 변경 할 수 있다. 표준 RI와 마찬가지로 컨버터블 RI도 사용량이 꾸준한 경우에 적합하다. * 예정된 RI(Scheduled RIs) : 예약한 시간 범위 내에서 인스턴스를 시작 할 수 있다. 이 옵션을 사용하면 하루, 한주 또는 월단위로 반복적인 용량 예측이 가능할 때 사용 할 수 있다. <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">온-디멘드에 비해서 예약 인스턴스가 저렴하기는 하지만 단순 비용 만으로는 Spot 인스턴스를 따라 갈 수 없다. Spot 인스턴스로 달성 할 수 없는 고유한 특징을 확인하는게 중요하다. Spot 인스턴스 대비 예약 인스턴스의 장점은 "중단되지 않고 안정적으로 사용" 할 수 있다는 점이다. 솔류션 아키텍트는 "우리의 서비스는 중단되어서는 안되며 그래서 Spot 인스턴스를 사용 할 수 없었음을" 어필 할 수 있을 것이다.</span> <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">또한 예약 인스턴스는 "예정된 RI"를 이용해서 특정 시간 동안의 용량을 예약 할 수 있다. 예를 들어 CRM은 월\~금요일 업무시간에 사용량이 크고, 주말과 업무 종료 시간에는 사용량이 적을 것이다. 예정된 RI를 이용하면, 예약된 시간내의 인스턴스에 대해서 할인된 시간당 요금을 지불한다. 이런 작업은 중단되어서는 안되므로 Spot 인스턴스를 사용 할 수 없다.</span> <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">결과적으로 솔류션 아키텍트는 Spot 인스턴스를 사용 할 수 없는 업무 특성을 가진 영역에서 예약 인스턴스를 활용 함으로써 비용 효율적인 시스템을 구축했음을 감사팀에 보고 할 수 있다.</span> <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">표준 예약 인스턴스는 다른 타입의 예약 인스턴스로 전환 할 수 없다. 단지 컨버터블 RI만 다른 타입의 인스턴스로 변환 할 수 있다. 컨버터블 RI는 할인율 보다 유연성을 더 중요하게 생각하는 고객을 위한 옵션이다.</span> <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">고객 전용의 하드웨어 VPC에서 실행되는 옵션은 Dedicated instance에 대한 설명이므로 여기에는 맞지 않다.</span> <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">인스턴스 구입 옵션을 정리했다.</span> * 온디맨드 인스턴스 - 시작하는 인스턴스에 대한 비용을 초 단위로 지불한다. * Savings Plans - 1년 또는 3년 기간 동안 시간당 USD로 일관된 사용량을 약정하여 EC2 비용을 절감한다. * Compute Saving Plans 가장 유연한 요금모델로 최대 66%까지 비용을 절감 할 수 있다. 인스턴스 패밀리, 크기, AZ, 리전, OS 태넌시와 관계없이 EC2 인스턴스의 사용량 단위로 적용되며 Fargate 와 Lambda 사용량에도 적용된다. * EC2 Instance Savings Plans : 리전의 개별 인스턴스 패밀리에 대한 사용량을 조건으로 최대 72%의 할인 혜택을 제공하는 가장 저렴한 요금 모델이다. * 예약 인스턴스 - 1년 또는 기간 동안 인스턴스 유형 또는 지역을 포함해 일관된 인스턴스 구성을 약정하여 Amazon EC2 비용을 절감한다. * 스팟 인스턴스 - 미사용 EC2 인스턴스를 요청하여 Amazon EC2 비용을 대폭 줄인다. * 전용 호스트 - 인스턴스 실행을 전담하는 실제(물리적) 호스트에 대한 비용을 지불한다. 기존의 소켓, 코어 또는 VM 소프트웨어 라이선스를 가져와서 비용을 절감한다. * 전용 인스턴스 - 단일 테넌트 하드웨어에서 실행되는 인스턴스 비용을 시간 단위로 지불한다. * 용량 예약 - 원하는 기간 동안 특정 가용 영역의 EC2 인스턴스에 대해 용량을 예약한다. <span style="color: rgb(5, 25, 34); font-family: 'Open Sans', sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: 0.1px; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">참고</span> * [EC2 예약 인스턴스 업데이트 - RI 변환 기능 및 리전 단위 적용](https://aws.amazon.com/ko/blogs/korea/ec2-reserved-instance-update-convertible-ris-and-regional-benefit/) 답 : 1, 2 ### Question #7 한 통신 회사가 개발자에게 AWS 콘솔 액세스 권한을 제공하려 한다. 회사 정책에 따라 ID federation 및 역할 기반 액세스 제어를 사용해야 한다. 현재 역할은 회사 Active Directory 그룹을 사용하여 이미 할당되어 있다. 이 시나리오에서 개발자에게 AWS 콘솔에 대한 액세스를 제공 할 수 있는 서비스의 조합은 무엇인가. (2개 선택) 1. IAM Roles 2. AWS Directory Service Simple AD 3. IAM Groups 4. Lambda 5. AWS Directory Service AD Connector * [설명](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#)Microsoft Active Directory용 AWS Directory Service, 즉 AWS Managed Microsoft Active Directory를 사용하여서 디렉토리 기반의 워크로드와 AWS 리소스에 AD(Active Directory)를 활용 할 수 있다. AWS Managed Microsoft AD는 실제 Microsoft AD에 구축되므로 기존 Active Directory의 데이터를 클라우드로 동기화 하거나 복제할 필요가 없다. 관리자는 표준 AD 관리 도구를 사용하여 Group Policy 및 SSO 등 AD의 기본 기능을 활용 할 수 있다. AWS Directory Service AD Connector를 이용해서 기존 디렉토리에 연결 할 수 있다. AWS Directory Service AD Connector를 통해서 VPC와 통합되면 Active Directory의 사용자 또는 그룹에 IAM 역할을 할당 할 수 있다. Lambda는 서비리스 컴퓨팅 서비스로 관계 없다. IAM Groups는 IAM User의 집합이다. 관계 없다. * [답](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#)1, 5 ### Question #8 EC2에서 호스팅되는 애플리케이션은 SQS 대기열의 메시지를 사용하며, SNS와 통합되어 프로세스가 완료되면 이메일을 보낸다. 운영팀은 5건의 주문을 받았는데, 몇 시간 후 받은 편지함에 20개의 이메일 알림을 확인했다. 이 문제의 원인이 될 수 있는 것은 무엇인가 ? 1. 웹 애플리케이션은 SQS queue로 부터 메시지를 사용할 권한이 없다. 2. 웹 애플리케이션은 short polling으로 메시지를 읽고 있으며, 이 때문에 메시지를 가져오지 못했다. 3. 웹 애플리케이션은 메시지를 처리하고 나서 SQS Queue로 부터 메시지를 지우지 않았다. 4. 웹 애플리케이션은 long polling으로 메시지를 처리하면서 메시지를 두 번 보내고 있다. #### 설명 SQS 대기열의 메시지는 애플리케이션이 처리 한 후에도<span> </span>**삭제하기 전까지 계속 존재**한다. SQS는 메시지를 처리하는 동안 다른 애플리케이션이 중복해서 처리하지 않도록 하는<span> </span>**가시성 제한 시간 초과**<span> </span>설정을 할 수 있다. 제한 시간은 30초로 이 시간동안에는 메시지가 보이지 않는다. 처리가 완료된 메시지가 다시 처리된다면 메시지를 삭제하는지를 확인해야 한다.  1. 메시지를 요청한다. 메시지 가시성이 확보된 상태이므로 메시지를 리턴한다. 2. Visibility Timeout 시간 동안에는 메시지를 리턴 받을 수 없다. 3. Visibility Timeout 시간이 지나면 메시지를 리턴한다. 메시지를 요청해서 처리한 애플리케이션이 메시지를 삭제하지 않는다면, visibility Timeout 후에 다른 애플리케이션들이 다시 읽어서 처리하게 된다. Long polling: Long polling는 빈 응답 수를 제거해서(ReceiveMessage를 호출했는데 메시지가 없는 경우) SQS의 사용 비용을 낮추는데 도움이 된다. Long polling을 사용한다고 해서 메시지가 중복 전송될 가능성은 거의 없다. 웹 애플리케이션이 SQS queue로부터 메시지를 사용할 권한이 없다면, 메일이 전송이 안되었을 것이다. 메일이 전송되었으므로 틀린 답이다. Amazon SQS의 주요 특징을 정리한다. * 분산된 소프트웨어 시스템에서 구성요소를 통합 & 분리하기 위한 호스팅 된 대기열이다. * SQS는 표준 및 FIFO 대기열을 지원한다. * SQS는 폴링 기반이다. * 사용자는 VPC 엔드 포인트를 사용하여 VPC에서 Amazon SQS에 액세스 할 수 있다. * 주요 기능 * 서버측 암호화 지원 * 내구성을 위해서 여러 서버에 메시지를 저장한다. * SQS는 버퍼링 된 각 요청을 처리하며 부하의 증가에 독립적으로 처리하도록 확장 할 수 있다. * Standard Queue * Unlimited Throughput * At-Least-Once Delivery - 메시지는 최소<span> </span>**한번 이상**<span> </span>전달된다. 두 개이상의 복사본이 전달될 수 있다. * 때때로 메시지는 전송된 순서와 다른 순서로 전달될 수 있다. * FIFO Queue * High Throughput. FIFI 큐는 배치작업의 경우 3,000message/sec를 지원한다. 배치작업이 아닌 경우 300 message/sec를 지원한다. * Exactly-Once Processing. 메시지는 정확히 한번 전달 된다. * First-in-First-Out. 정확한 메시지 순서를 보장한다. * SQS는 dead-letter queues를 제공한다. Dead-letter 큐는 성공적으로 소비되지 않은 메시지의 처리에 사용 할 수 있다. 이 큐는 문제가 있는 메시지를 구분하여 처리가 실패한 이유를 확인 할 수 있으므로 메시징 시스템을 디버깅하는데 유용하게 사용 할 수 있다. 답 : 3 ### Question #9 프러덕션 환경에서 S3 버킷에 저장된 사용자 데이터를 주니어 DevOps 엔지니어 중 한명이 실수로 삭제하는 사고가 발생했다. 문제는 관리자에게 에스컬레이션되었으며, 며칠 후 리소스의 보안 및 보호를 개선하라는 지시를 받았다. 솔류션 아키텍트는 실수로 인한 삭제 및 덮어 쓰기로 부터 버킷의 S3 객체를 보호하기 위한 솔류션을 제안해야 한다. (2개) 1. Enable Amazon S3 Intelligent-Tiering 2. Enable Multi-Factor Authentication Delete 3. Provide access to S3 data strictly through pre-signed URL only 4. Disallow S3 delete using an IAM bucket policy 5. Enable Versioning #### 설명 버전관리 기능과 MFA 삭제를 활성화하면, S3 객체를 실수로 삭제하거나 덮어쓰는 것으로 부터 보호하고 복구 할 수 있다. 버전관리를 이용하면 동일한 버킷에 객체의 여러 버전을 유지 할 수 있다. 버전관리가 활성화된 버킷을 사용하면 삭제하거나 덮어쓰더라도 이전 버전의 객체를 이용해서 객체를 복구 할 수 있다. MFA는 선택적인 보안 계층이다. 버킷 소유자는 승인된 디바이스로 부터 생성된 6자리의 코드를 요청에 포함해야 하기 때문에 실수에 의한 삭제를 줄일 수 있다. Amazon S3 Intelligent-Tiering는 데이터 액세스 패턴의 변경에 따라서 스토리지를 변경함으로써 비용을 최적화하는 스토리지 클래스다. 문제와 관계없는 기능이다. Disallow S3 delete는 사용자는 여전히 버킷에서 객체를 삭제 할 수 있어야 하기 때문에 우발적인 삭제를 방지하기 위한 올바른 솔류션이 아니다. 답 : 1, 5 ### Question #10 한 회사가 Amazon ElastiCache Redis를 세션관리 시스템의 구성요소로 사용할 계획을 수립했다. 다른 부서의 엔지니어가 ElastiCache 클러스터에 액세스 할 수 있으므로 Redis 명령을 실행하기전에 암호를 입력하도록 해서 세션 데이터를 보호하려 한다. 솔류션 아키텍트는 위의 요구사항을 충족하기 위한 솔류션을 제안해야 한다. 1. --transit-encryption-enable과 auth-token 을 활성화한 상태에서 Redis Cluster를 생성하여 Redis AUTH로 사용자를 인증한다. 2. Redis 리플리케이션 그룹에 in-transit encryption을 활성화 한다. 3. Redis 리플리케이션 그룹에 AtRestEncryptionEnabled 파라메터를 활성화 한다. 4. 클라우드 엔지니어가 ElastiCache 클러스터에 액세스하기 전에 IAM 자격 증명과 토큰을 입력하는 IAM 정책 및 MFA를 설정한다. #### 설명 Amazon ElatiCache Redis는 인증 시스템으로 오픈소스 Redis의<span> </span>**Redis AUTH**를 그대로 사용한다. ElastiCache는 IAM을 지원하지 않는다. --transit-encryption-enable과 auth-token 은 HIPAA 자격획득에 필요하다. Redis AUTH에 사용하는 토큰은 중요한 정보이기 때문에 --transit-encryption-enable 은 반드시 활성화해야 한다. in-transit는 복제 그룹간의 전송 데이터를 암호화하기 위해서 사용한다. 전송중 암호화는 데이터 보호의 중요한 요소이기는 하지만 AUTH 옵션이 누락되어 있다. AtRestEncryptionEnabled 파라미터는 메모리에 있는 데이터 저장소의 데이터를 암호화한다. 인증과는 상관없는 기능이다.  1. 전송중 데이터 암호화를 위해서는 Encryption In-Transit 을 사용한다. 2. 클러스터 인증에는 Redis AUTH를 사용한다. 3. 메모리에 저장된 데이터는 --transit-encryption-enable 을 사용한다. 참고 * [Amazon ElastiCache의 데이터 보안](https://docs.aws.amazon.com/ko_kr/AmazonElastiCache/latest/red-ug/encryption.html) 답 : 1 ### Question #11 한 회사가 EC2 인스턴스의 Auto Scaling 그룹에서 웹 애플리케이션을 호스팅하고 있다. IT 관리자는 더 높은 운영 비용을 유발 할 수 있는 리소스의 과잉 프로비저닝에 대해서 우려하고 있다. 솔류션 아키텍트는 애플리케이션 성능에 영향을 주지 않고 비용 효율적인 솔류션을 만들도록 지시 받았다. 이 요구 사항을 충족하려면 어떤 동적 스케일링 정책을 사용해야 하는가 ? 1. Use Simple Scaling 2. Use Scheduled scaling 3. Use suspend and resume scaling. 4. Use target tracking scaling #### 설명 동정 스케일링을 설졍할 때, 엔지니어는 수요에 대응하여 Auto Scaling 그룹의 용량을 어떻게 조정할지를 정의해야 한다. 동적 스케일링은 다양한 워크로드에 적용 할 수 있도록 세분화 되어 있다. * 대상 추적 조정 정책(Target tracking scaling)은 대상을 상태를 추적하는 CloudWatch의 경보를 생성 및 관리하여 지표의 목표값을 기반으로 스케일링 조정을 계산한다. 애플리케이션의 요구사항에 따라서 CPU, Application Load balancer의 대상 그룹의 요청수, 수신 바이트 수 등의 다양한 지표를 대상으로 할 수 있다> * Simple scaling 정책은 CloudWatch 지표를 선택하여 확장 할 단일 임계값을 지정한다. 스케일링 정책은 CloudWatch 경보를 기반으로 한다. * Step scaling 정책은 단계를 지정 할 수 있다는 것을 제외하고는 Simple scaling 정책과 동일하다. 스케일링 정책은 CloudWatch 경보를 기반으로 한다. * 임계값 A : CPU 사용율이 40\~50%인 경우 인스턴스 1개 추가 * 임계값 B : CPU 사용율이 50\~70%인 경우 인스턴스 2개 추가 * 임계값 C : CPU 사용율이 70\~90%인 경우 인스턴스 3개 추가  Simple scaling의 주요 문제점은 scaling 활동이 시작된 후 조정 활동 또는 상태 확인 대체가 완료되고 나서 휴지기간(cooldown period)이 만료될 때까지 기다렸다가 추가 경보에 응답해야 한다는 것이다. Target tracking 스케일링 정책을 사용하면 특정 지표의 대상 값을 기반으로 그룹의 현재 용량을 늘리거나 줄일 수 있다. 이 정책은 리소스의 과잉 프로비저닝을 해결하는데 도움이 된다. 스케일링 정책은 지표를 지정된 목표 값에 가깝게 유지하기 위해서 필요에 따라 용량을 추가하거나 제거한다. 따라서 정답은 Target tracking 스케일링을 사용하는 것이다. Suspend and resume 스케일링은 트리거된 스케일링 활동을 일시 중지하거나 재개하는데 사용하는 것이기 때문에, 문제와는 상관 없는 답변이다. 참고로 Simple Scaling에서의 suspend 시나리오를 살펴보자. AWS에 실행 중인 웹 애플리케이션이 있다. 이 웹 애플리케이션은 웹, 애플리케이션, 데이터베이스의 3 티어로 구성된다. 웹 애플리케이션의 트래픽 요구사항을 충족하도록 리소스를 유지하기 위해서 웹 티어용과 애플리케이션 티어용으로 Auto scaling 그룹을 두 개 생성했다. DevOps 엔지니어는 CloudWatch의 CPU 값이 지정된 시간 동안 연속해서 임계값을 초과할 경우 인스턴스를 확장하는 단순 조정 정책을 생성했다. Auto scaling에 사용되는 인스턴스는 구성 스크립트를 사용해서 소프트웨어를 설치하고 실행 할 것이다. 결과적으로 인스턴스가 시작되어서 완전한 서비스 상태가 될 때까지 2-3분 가량의 시간이 소요된다. 이제 트래픽이 급증해서 CloudWatch 경보가 울릴 것이다. 경보가 울리면 Auto scaling 그룹에서 인스턴스를 시작하여 수요 증가에 대응하기 시작 할 것이다. 하지만 문제가 있는데, 인스턴스가 시작하는데 몇 분의 시간이 소요될 수 있다는 것이다. 이 시간 동안 CloudWatch 경보가 연속해서 울릴 수 있으며, 그 때마다 Auto scaling 그룹에서 또 다른 인스턴스를 시작하게 된다. 휴지기간을 적용하게 되면 인스턴스를 시작한 다음 지정한 시간동안 scaling 정책에 의한 scaling 활동을 중단한다. 기본 값은 300 초다. 답 : 4 참고 * [AWS auto scaling](https://tutorialsdojo.com/aws-auto-scaling/?src=udemy) * [EC2 Auto scaling cooldown](https://docs.aws.amazon.com/ko_kr/autoscaling/ec2/userguide/Cooldown.html) * [Target tracking scaling policies for Amazon EC2 Auto Scaling](https://docs.aws.amazon.com/ko_kr/autoscaling/ec2/userguide/as-scaling-target-tracking.html) * [Step and simple scaling for Amazon EC2 Auto Scaling](https://docs.aws.amazon.com/ko_kr/autoscaling/ec2/userguide/as-scaling-simple-step.html) ### <span> </span>Question #12 회사는 내부 회사 웹 포털을 위해 프라이빗 서브넷에 Amazon EC2 인스턴스를 전개할 계획이다. 보안을 위해 EC2 인스턴스는 퍼블릭 네트워크를 통과하지 않는 프라이빗 엔드포인트를 통해 Amazon DynamoDB 및 Amazon S3에 데이터를 전송해야 한다. 다음 중 위의 요구사항을 충족할 수 있는 솔류션은 무엇인가 ? 1. AWS Transit Gateway를 사용하여 프라이빗 엔드포인트를 통해 S3 및 dynamoDB에 대한 모든 액세스를 라우팅한다. 2. VPC 엔드포인트를 사용하여 프라이빗 엔트포인트를 통해서 S3 및 dynamoDB에 대한 모든 액세스를 라우팅한다. 3. AWS Direct Connect를 사용하여 프라이빗 엔드포인트를 통해서 S3 및 dynamoDB에 대한 모든 액세스를 라우팅한다. 4. AWS VPN CloudHub를 이용하여 프라이빗 엔드포인트를 통해서 S3 및 dynamoDB에 대한 모든 액세스를 라우팅한다. #### 설명 VPC 엔드포인트를 사용하면 인터넷 게이트웨이, NAT, VPN 연결 또는 Direct Connect 연결 없이도 AWS PrivateLink에서 지원하는 AWS 및 VPC 엔드 포인트 서비스에 VPC를 비공개로 연결 할 수 있다. VPC의 인스턴스는 서비스 리소스와 통신하는데 퍼블릭 IP 주소가 필요하지 않다. 이 트래픽은 Amazon 네트워크를 벗어나지 않는다. 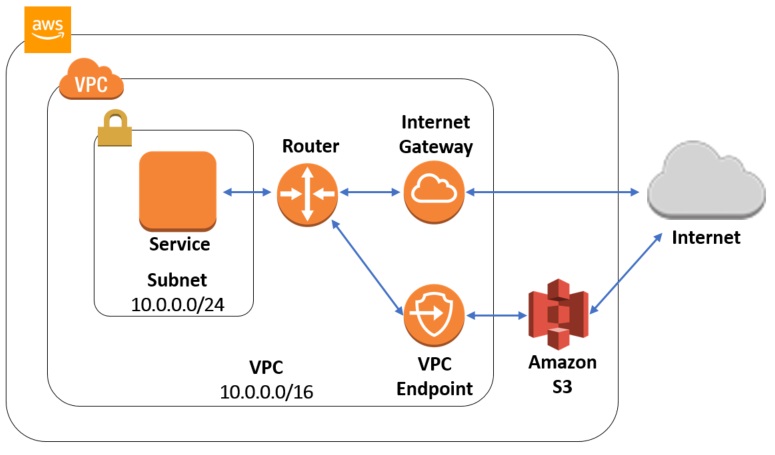 VPC에서 AWS 서비스에 연결하는 두 가지 방법이 있다. 하나는 인터넷 게이트웨이를 경유해서 접근하는 방법이다. 가능은 하지만 좋은 방법은 아니다. 그래서 AWS 네트워크를 벗어나지 않고 VPC에서 Amazon S3, DynamoDB에 직접 연결 할 수 있는 VPC 엔드 포인트가 도입되었다. VPC 엔드포인트는 PrivateLink와도 통합될 수 있는데, 이를 이용해서 AWS 인프라 사용자는 SaaS 형태로 안전하게 서비스를 제공 할 수 있게 됐다. Transit Gateway는 중앙 허브를 통해서 VPC와 온프레미스 네트워크를 연결하는 서비스로 Transit Gateway를 사용하여 S3 및 DynamoDB에 라우팅하는 옵션은 올바르지 않다. Transit Gateway를 네트워크를 통합하는 일을 한다. AWS Direct Connect는 주로 회사 IDC와 AWS를 전용선으로 연결하는데 사용한다. 회사가 하이브리드 클라우드 아키텍처를 가지고 있다면 이러한 구성도 생각 해 볼 수 있겠으나 위 시나리오에는 이러한 환경임을 언급하지 않았다. VPC CloudHub는 사이트간 보안 통신을 통합 관리하기 위한 서비스다. 다수의 Site-to-Site VPN 연결을 사용하는 경우 AWS VPN CloudHub로 사이트간 보안 통신을 제공 할 수 있다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [VPC 엔드포인트](https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/vpc-endpoints.html) * [How to Configure a Private Network Environment for Amazon DynamoDB](https://aws.amazon.com/ko/blogs/database/how-to-configure-a-private-network-environment-for-amazon-dynamodb-using-vpc-endpoints/) * [VPN CloudHub](https://docs.aws.amazon.com/ko_kr/vpn/latest/s2svpn/VPN_CloudHub.html) * [Amazon VPC Cheat sheet](https://tutorialsdojo.com/amazon-vpc/?src=udemy) 답 : 2 <br> ### Question #13 솔류션 아키텍트는 다양한 AWS 리전에 여러 VPC를 보유한 회사에서 일하고 있다. 아키텍츠는 IAM, CloudFront, AWS WAF 및 Route 53으로 이루어진 구성을 포함하여 모든 리전에서 AWS 리소스에 대한 변경사항을 추적하는 로깅 시스템을 설정하라는 지시를 받았다. 규정 준수 사항을 통과하려면 솔류션은 로그 데이터의 보안, 무결성 및 내구성을 보장해야 한다. 또한 AWS Management Console 및 AWS CLI에서 이루어진 모든 API 호출 이벤트 기록을 제공해야 한다. 다음 중 이 시나리오에 가장 적합한 솔루션은 무엇인가. 1. Set up a new CloudWatch trail in a new S3 bucket using the AWS CLI and also pass both the --is-multi-region-trail and --include-global-service-events parameters then encrypt log files using KMS encryption. Apply Multi Factor Authentication Delete on the S3 bucket and ensure that only authorized users can access the logs by configuring the bucket policies. 2. Set up a new CloudTrail trail in a new S3 bucket using the AWS CLI and also pass both the --is-multi-region-trail and --no-include-global-service-events parameters then encrypt log files using KMS encryption. Apply Multi Factor Authentication Delete on the S3 bucket and ensure that only authorized users can access the logs by configuring the bucket policies. 3. Set up a new CloudTrail trail in a new S3 bucket using the AWS CLI and also pass both the --is-multi-region-trail and --include-global-service-events parameters then encrypt log files using KMS encryption. Apply Multi Factor Authentication Delete on the S3 bucket and ensure that only authorized users can access the logs by configuring the bucket policies. 4. Set up a new CloudWatch trail in a new S3 bucket using the AWS CLI and also pass both the --is-multi-region-trail parameters then encrypt log files using KMS encryption. Apply Multi Factor Authentication Delete on the S3 bucket and ensure that only authorized users can access the logs by configuring the bucket policies. #### #### 설명 CloudTrail는 AWS 계정 활동을 기록한다. CloudTrail은 AWS management console 작업과 API 호출을 기록함으로써 사용자 및 리소스 활동에 대한 가시성을 높인다. AWS를 호출한 사용자, 계정, 호출이 이루어진 소스 IP, 호출이 발생한 시간을 확인 할 수 있다. CloudTrail은 관리 이벤트를 추적하지만 데이터 이벤트는 추적하지 않는다. 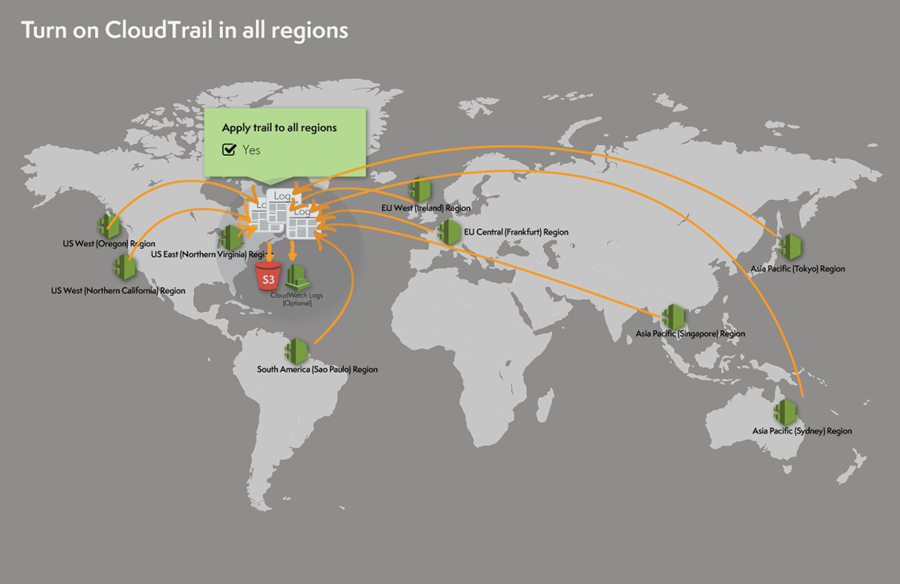 CloudTrail은 단일 리전 및 모든 리전에 대한 CloudTrail를 활성화 할 수 있다. 이 옵션은 기본이다. 대부분의 서비스에서 이벤트는 작업이 발생한 지역에 기록이 된다. AWS IAM, CloudFront, Route 53과 같은 글로벌 서비스의 경우 글로벌 서비스를 포함하는 모든 이벤트가 전달되며 미국 동부(버지니아 북부) 리전에서 발생하는 것으로 기록된다. 이 시나리오에서 CloudTrail은 모든 AWS 리소스의 모든 활동을 추적을 요구사항으로 하고 있다. CloudTrain은 다중 지역 추적이 활성화된 경우 사용 할 수 있지만 이 경우 IAM, CloudFront, WAF와 같은 글로벌 서비스가 아닌 지역서비스(EC2, S3, RDS)의 활동만 다룬다. 이 요구사항을 충족하려면 --include-global-service-events 파라미터를 추가해야 한다. * --include-global-service-events : CloudTrail 추적이 IAM과 같은 글로벌 서비스의 이벤트를 로그 파일에 게시할지 여부를 결정한다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [Turn on in All Regions & Use Multiple Trails](https://aws.amazon.com/ko/blogs/aws/aws-cloudtrail-update-turn-on-in-all-regions-use-multiple-trails/) * [CloudTrail에 대한 버킷 정책](https://docs.aws.amazon.com/ko_kr/awscloudtrail/latest/userguide/create-s3-bucket-policy-for-cloudtrail.html) 답 : 3. ### Question #14 솔루션 아키텍트는 AWS Lambda가 미국 동부에 있는 exampleSrv라는 Amazon DynamoDB 테이블에 액세스 할 수 있는 서버리스 아키텍처를 설계했다. Lambda 함수에 연결된 IAM 정책을 사용하여 테이블에 항목을 넣고 삭제 할 수 있다. 이 Lambda 함수는 exampleSrv 테이블에 대해서 두 개의 작업만 허용하고 다른 DynamoDB 테이블에는 접근하지 못하도록 정책을 업데이트해야 한다. 다음 중 이 요구사항을 충족하며 최소 권한 부여 원칙을 따르는 IAM 정책은 무엇인가. 1. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrvPolicy1", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" }, { "Sid": "exampleSrvPolicy2", "Effect": "Allow", "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" } ] } ``` 2. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrvPolicy1", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/*" } ] } ``` 3. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrvPolicy1", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" } ] } ``` 4. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrvPolicy1", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" }, { "Sid": "exampleSrvPolicy2", "Effect": "Deny", "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/*" } ] } ``` <br> #### 설명 모든 AWS 리소스는 AWS 계정이 소유하며 리소스를 생성하거나 액세스 할 수 있는 권한은 권한 정책에 의해서 관리된다. 계정 관리자는 IAM 자격증명(사용자, 그룹, 역할)에 대한 권한정책을 연결 할 수 있다. DynamoDB에서 기본 리소스는 테이블이다. 그리고 추가 리소스 유형인 인덱스, 스트림도 지원한다. 이들 인덱스와 스트림은 DynamodB 컨텍스트 내에서만 유지되기 때문에 하위 리소스라고 한다. 이들 리소스 및 하위 리소스는 고유한 이름인 ARN(아마존 리소스 이름)에 연결되어 있다. 예를 들어 AWS 계정(123456789012)가 미국 동부(us-east-1) 리전에 Books라는 DynamoDB 테이블이 있다면, 이 테이블의 ARN은 아래와 같다. arn : aws : dynamodb : us-east-1 : 123456789012 : table / Books 정책(policy)는 리소스에 연결될 때 행사 할 수 있는 권한을 정의하는 엔터티이다. 이 시나리오에서는 Lambda 함수를 사용해서 DynamoDB의 exampleSrv 테이블을 수정해야 한다. 하나의 테이블에만 액세스하면 되므로 IAM 정책의 Resource에 테이블의 ARN을 설정해야 한다. 따라서 이 시나리오의 정답은 아래와 같다. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrv", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:120618981206:table/exampleSrv" } ] } ``` 시나리오에서는 exampleSrv 테이블의 권한만 허용한다고 했으므로 와일드 카드 정책을(:table/\*) 사용하는 정책은 올바르지 않다. 이렇게 할 경우 계정이 소유한 모든 테이블을 수정 할 수 있게 된다. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrv", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:120618981206:table/*" } ] } ``` 아래의 IAM 정책에서 첫 번째 문은 exampleSrv에 대한 PUT, Delete 작업을 올바르게 허용하고 있다. 그러나 두 번째 문에서 exampleSrv의 테이블의 모든 작업을 허용하고 있으므로 첫 번째 문과 충돌한다. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrvPolicy1", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" }, { "Sid": "exampleSrvPolicy2", "Effect": "Allow", "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" } ] } ``` 아래의 IAM 정책에서 첫 번째 문은 올바르게 작성되었으나, 두번째 문은 모든 DynamoDB 작업을 거부하기 때문에 첫 번째 문과 충돌한다. 이 정책은 AWS 계정의 모든 DynamoDB 테이블에 대한 작업을 허용하지 않는다. ```json5 { "Version": "2012-10-17", "Statement": [ { "Sid": "exampleSrvPolicy1", "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/exampleSrv" }, { "Sid": "exampleSrvPolicy2", "Effect": "Deny", "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:us-east-1:1206189812061898:table/*" }, ] } ``` * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [DynamoDB에서의 자격 증명 기반 정책 사용](https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/using-identity-based-policies.html) * [IAM cheat sheet](https://tutorialsdojo.com/aws-identity-and-access-management-iam/?src=udemy) 답 : 3 ### Question #15 온라인 쇼핑몰 플랫폼은 스팟 EC2 인스턴스의 Auto Scaling 그룹에서 호스팅되며 Amazon Aurora PostgreSQL을 데이터베이스로 사용하고 있다. 프로덕션 트래픽의 쓰기 작업을 고용량 인스턴스로 지정하고 내부 직원이 작성할 레포트를 위한 데이터베이스 작업을 저용량 인스턴스로 지정해야 하는 요구사항이 있다. 이 요구 사항을 충족하기 위한 Aurora 데이터베이스 클러스터 구성은 무엇인가. 1. 애플리케이션에서 Aurora 데이터베이스의 인스턴스 엔드포인트를 이용해서 서비스 트래픽을 처리하고 클러스터 엔드포인트를 이용해서 리포팅 쿼리를 수행한다. 2. Aurora는 자동으로 서비스 트래픽을 고용량 인스턴스로 보내고, 리포팅 쿼리를 저용량 인스턴스로 보내기 때문에 별도의 작업을 할 필요가 없다. 3. 프로덕션 트래픽과 레포팅 트래픽이 모두 reader 엔드포인트를 사용하도록 구성하면 Aurora 데이터베이스는 자동으로 쿼리를 로드밸런싱 한다. 4. 프로덕션 요구사항을 충족하는 지정 엔드포인트를 만들고 레포팅 요구사항을 충족하는 지정 엔드포인트를 만든다. ##### 설명 Amazon Aurora는 일반적으로 단일 인스턴스 대신 DB 인스턴스 클러스터를 생성한다. 각 연결은 특정 DB 인스턴스에서 처리된다. 애플리케이션은 endpoint 매커니즘을 사용해서 이러한 연결을 추상화 한다. 엔드포인트를 사용하면 각 사용 사례에 따라서 적절한 인스턴스 혹은 인스턴스 그룹을 매팅 할 수 있다. 예를 들어 DDL 문을 수행하기 위해서는 기본 인스턴스를 사용 할 수 있다. 쿼리를 수행하면 Aurora가 모든 Aurora 복제본간에 밸런싱을 자동으 수행하여 리더 앤드포인트로 연결한다. 엔드포인트는 사용자가 지정 할 수 있는데, 예를 들어 워크로드에 맞는 AWS 인스턴스 클래스와 DB 파라미터 그룹을 사용하는 인스턴스에 연결된 엔드포인트를 만들 수 있다. 보고서 생성이나 임시 쿼리를 위한 내부 사용자용 저용량 인스턴스를 만들어서 대용량 프러덕션 트래픽과 분리해서 사용 할 수 있다. Amazon Aurora는 아래와 같은 엔드포인트를 지원한다. **클러스터 엔드포인트**<span> </span>: 각 Aurora 클러스터가 기본제공하는 단일 클러스터 엔드포인트다. 이 엔드포인트는 Aurora에서 관리하기 때문에 수정하거나 삭제할 수 없다. 클러스터 엔드포인트는 클러스터의 기본 인스턴스에 연결된다. 기본 인스턴스는 테이블과 인덱스를 만들고 INSERT 문과 DDL, DML 작업을 수행하는 유일한 DB 인스턴스다. * DDL : 테이블과 같은 데이터 구조를 정의하는데 사용하는 명령어 * DML : 데이터를 조회하거나 검색하기 위한 명령어. **리더 엔드포인트**<span> </span>: **사용자 지정 엔드포인트**<span> </span>: 딥 : 4 ### Question #16 매일 수십만 명의 클라이언트가 액세스하는 온라인 웹 포탈의 웹 서비스에 API gateway와 Lambda 조합을 사용하고 있다. 그들은 새로운 혁신적인 서비스를 발표할 것이며 웹 포털은 전 세계적으로 엄청난 수의 방문자를 받을 것으로 예상된다. 트래픽 급증으로부터 백엔드 시스템과 애플리케이션을 어떻게 보호할 수 있을까 1. API Gateway는 자동으로 확장된다. 대량의 트래픽을 처리하기 위해서 어떠한 작업도 필요없다. 2. API Gateway를 Read Replica로 Multi-AZ에 전개한다. 3. API Gateway에 throttling 제한을 설정한다. 4. API Gateway에서 사용 중인 EC2 인스턴스를 수동으로 확장한다. #### 설명 Amazon API Gateway는 전역 및 서비스 호출에 대하여 여라 단계에서 throttling 조절 기능을 제공한다. 예를 들어 API 소유자는 REST API의 특정 메서드에 대해서 초당 1,000 개의 요청 속도 제한을 설정 할 수 있으며, 몇 초 동안 초당 2,000 요청 버스트를 처리하도록 API Gateway를 구성 할 수 있다. API Gateway는 초당 요청수를 추적한다. 초당 요청수를 초과한 모든 요청은 429 HTTP 응답을 받는다. Amazon API Gateway에서 생성한 클라이언트 SDK는 이 응답을 받으면 자동으로 재 호출을 시도한다. 따라서 정답은 API Gateway에 대한 제한을 사용하는 것이다. API Gateway는 대규모의 트래픽 증가에 대해서 자동으로 확장해서 처리 한다. 또한 AWS Edeg Location을 사용 하여 확장 할 수 있지만 API 버스트를 추가로 관리하려면 Throttling 설정을 해야 한다. API Gateway는 완전 관리형 서비스로 기본 리소스에 액세스 할 수 없기 때문에 API-Gateway를 구성하는 EC2 인스턴스를 수동으로 업그레이드 할 수 있는 방법이 없다. API Gateway는 다중 가용영역에 읽기전용 복제본을 배포하는 기능이 없다. Amazon API Gateway는 API를 보호하기 위한 몇 가지 기능을 제공한다. * REST API에 대한 상호 TLS 인증 구성 : 상호 TLS 인증에는 클라이언트와 서버 간의 양방향 인증이 필요하다. 상호 TLS를 사용하는 경우 클라이언트가 API에 접근하려면 X.509 인증서를 제공해야 한다. 상호 TLS는 사물 인터넷 및 B2B 애플리케이션에 일반적으로 요구된다. * 백엔드 인증을 위한 SSL 인증서 생성 및 구성 : API Gateway에서 SSL 인증서를 생성 한 다음, 백엔드에서 퍼블릭키를 사용하여 백엔드 시스템에 대한 HTTP 요청의 출처가 API Gateway인지 확인 할 수 있다. 이렇게 해서 백엔드는 API Gateway에서 시작된 요청만을 처리하도록 할 수 있다. * AWS WAF를 사용하여 API 보호 : SQL 명령어 주입, 교차 사이트 스크립팅(XSS) 공격과 같은 일반적인 웹 익스플로잇으로 부터 API Gateway를 보호할 수 있다. * 처리량 향상을 위해 API 요청 조절 * Amazon API Gateway에 프라이빗 API 생성 XSS 공격이란 사이트에 악성 코드(주로 자바스크립트로 작성된)를 넣어서 다른 클라이언트의 쿠키, 세션, 민감 정보를 탈취하는 공격이다. 자바스크립트를 포함한 HTML 문서를 올릴 수 있는 서비스에서 주로 발생한다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [API 보호](https://docs.aws.amazon.com/ko_kr/apigateway/latest/developerguide/rest-api-protect.html) * [처리량 향상을 위한 API 요청 조절](https://docs.aws.amazon.com/ko_kr/apigateway/latest/developerguide/api-gateway-request-throttling.html) * [XSS 공격이란](https://4rgos.tistory.com/1) ### Question #17 스타트업은 Amazon RDS를 사용하여 웹 애플리케이션의 데이터를 저장한다. 대부분의 경우 이 애플리케이션은 사용자 활동이 많지 않지만, 신제품 발표가 있을 때마다 몇 초 내에 트래픽이 급증한다. 솔류션 아키텍트는 전 세계 사용자가 API를 사용하여 데이터를 액세스 할 수 있는 솔류션을 만들어야 한다. 솔류션 아키텍트는 위의 요구사항을 어떻게 충족해야 하는가 1. API Gateway와 AWS Lambda를 이용해서 API를 제공하고 트래픽 버스트를 관리한다. 2. API Gateway를 이용해서 API를 제공하고 Auto scaling 그룹으로 Amazon EC2 instance를 묶어서 수초 이내에 버스트 할 수 있도록 한다. 3. API Gateway를 이용해서 API를 제공하고 Auto scaling 그룹으로 ECS를 제공하여서 수초 이내에 버스트 할 수 있도록 한다. 4. API Gateway를 이용해서 API를 제공하고 Auto scaling 그룹으로 Elastic Beanstalk를 묶어서 수초 이내에 버스트 할 수 있도록 한다. #### 설명 갑작스러운 트래픽 증가에 대응하려면 API-Gateway, 컴퓨팅, 데이터베이스 모두에 대한 고려가 필요하지만 위 문제에서는 데이터베이스는 고려하지 않고 있다. 따라스 API-Gateway와 컴퓨팅 부분만 집중해서 살펴봐야 한다. 함수를 처음 호출하면 AWS Lambda는 함수를 실행할 인스턴스를 생성하고 핸들러 메서드를 실행하여 이벤트를 처리한다. 함수가 응답을 반환하면 활성 상태를 유지하고 추가적인 이벤트를 처리 할 때까지 기다린다. 첫 번째 이벤트가 처리되는 동안 두 번재 이벤트가 도착하면 Lambda는 다른 인스턴스를 초기화하고 함수는 두 이벤트를 동시에 처리하게 된다. 더 많은 이벤트가 수신되면 Lambda는 사용 가능한 인스턴스로 라우팅하고 필요에 따라 새 인스턴스를 생성한다. 요청수가 감소하면 Lambda는 사용하지 않는 인스턴스를 중지한다. 아래 그림은 동시성 제한에 따른 함수의 확장을 보여주고 있다.  함수는 함수가 실행되는 리전의 계정의 동시성 한도에 도달할 때까지 계속 확장된다. 이 함수는 수요를 따라잡고 요청이 감소하면 잠시 유휴 상태가 된 이후 함수의 미사용 인스턴스가 중지된다. 이렇게 중지된 인스턴스에는 요금이 부과되지 않는다. 리전별 동시성 제한은 1,000에서 시작한다. 사용자는 지원 센터 콘솔에 요청을 제출하여 제한을 늘릴 수 있다. 솔류션 아키텍트는 두 가지 문제에 대한 솔류션을 제안해야 한다. 1. 사용자가 API를 이용해서 데이터에 엑세스 할 수 있게 해야 한다. 2. 트래픽 버스트를 몇 초 이내에 처리해야 한다. 1번 문제는 API Gateway를 이용해서 해결 할 수 있다. Lambda는 대략 15\~30 분 동안 합리적인 수준에서 트래픽 증가를 흡수 할 수 있으므로 Lambda를 사용해야 한다. EC2, Elastic Beanstalk, ECS 들도 Auto Scaling를 이용해서 쉽게 확장 할 수 있지만, 이들 솔류션은 Lambda에 비해서 흡수하는데 더 많은 시간이 걸린다. Lambda에 비해서 좀 더 무겁고, 전개하는데 시간이 걸리기 때문이다. Lambda의 경우에는 AWS에서 이미 수천대의 사용 가능한 EC2 인스턴스를 실행하고 있는 상태이기 때문에, 빠르게 코드를 실행 할 수 있다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [AWS Lambda 함수 규모 조정](https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/invocation-scaling.html) 답 : 1 ### Question #18 애플리케이션은 Amazon S3 버킷에 객체가 로드 될 때마다 배치작업을 수행하는 AWS Fargate 클러스터에서 호스팅된다. 최소 ECS 작업수는 비용 절감을 위해서 초기에 1로 설정되어 있으며 S3 버킷에 업로드된 새 객체를 기준으로 작업 수만 증가시킨다. 처리가 완료되면 버킷이 비워지고 ECS 작업 수는 다시 1이 되어야 한다. 최소한의 노력으로 구현하기에 가정 적합한 옵션은 무엇인가. ? 1. S3 객체 PUT을 감지하도록 cloudwatch 이벤트 규칙을 설정하고, ECS Task를 요청하기 위한 lambda 함수를 개발한다. S3 DELETE 작업을 감지하는 다른 규칙을 만들어서 Lambda 함수를 실행하여 ECS Task 수를 줄인다. 2. S3 객체에 대한 작업은 CloudTrail에 기록되므로 CloudWatch에서 경보를 설정하여 Cloudtrail을 모니터링한다. ECS 작업을 늘리고 줄이는 두 개의 람다 함수를 만들어서 S3 이벤트에 따라서 Lambda를 실행한다. 3. S3 객체 PUT을 감지하도록 cloudwatch 이벤트 규칙을 설정하고 ESC 클러스터에 Task를 증가시킨다. S3 DELETE 작업을 감지하는 다른 규칙을 생성해서 ECS 클러스터의 Task를 1 감소 시킨다. #### 설명 Amazon Elastic Container Service는 ECS 서비스 작업 이벤트를 Amazon CloudWatch Events에 게시 할 수 있다. Amazon S3 PUT으로 S3 버킷에 파일이 업로드 될 때마다 ECS 작업을 실행하는 CloudWatch Event 규칙을 설정할 수 있다. DELETE 작업에 대해서도 마찬가지로 ECS 작업을 감소하도록 선언 할 수 있다. 따라서 정답은 다음과 같다. CloudWatch 이벤트 규칙을 설정하여 PUT 작업이 감지될 경우 ECS 작업을 증가시킬 ECS 클러스터를 대상으로 설정한다. DELETE에 대해서도 ECS 작업을 감소시킬 ECS 클러스터를 대상으로 설정한다. 몇 가지 다른 방법을 선택 할 수도 있다. S3 PUT 작업을 감지하도록 CloudWatch 이벤트 규칙을 설정하고 ECS 작업을 늘리는 ECS API를 호출하는 Lambda 함수를 설정 할 수 있다. 이렇게 구현 할 수도 있으나 CloudWatch에서 직접 ECS 작업을 제어하는 것이 훨씬 간단하므로 답이 아니다. S3 객체 작업은 CloudTrail에 기록되므로 CloudTrail에 대해서 CloudWatch 경보를 설정하여서 ECS 작업수를 늘리거나 줄이는 Lambda를 설정 할 수 있다. 하지만 역시 지나치게 복잡한 작업이므로 답이 아니다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [이제 Amazon ECS 서비스 이벤트를 CloudWatch Events로 사용 가능](https://aws.amazon.com/ko/about-aws/whats-new/2019/11/amazon-ecs-service-events-now-available-as-cloudwatch-events/) * [Amazon ECS 이벤트](https://docs.aws.amazon.com/ko_kr/AmazonECS/latest/developerguide/ecs_cwe_events.html) 답 : 3 ### Question #20 회사에서 애플리케이션을 AWS로 마이그레이션하는 중이다. 그들의 시스템 중 하나는 전 세계적으로 확장 할 수 있고, 빈번한 스키마 변경을 처리 할 수 있는 데이터베이스를 필요로 한다. 데이터베이스의 스키마 변경이 될 때마다 애플리케이션 다운 타임이나 성능 문제가 없어야 한다. 또한 트래픽이 늘어나더라도 짧은 응답 대기 시간을 제공해야 한다. 이 요구사항을 충복하는 가장 적합한 데이터베이스 솔류션은 무엇인가 ? 1. Multi-AZ 전개 설정을 한 RDS 인스턴스 2. Redshift 3. 읽기 복제본을 가진 Amazon Aurora 데이터베이스 4. Amazon DynamoDB #### 설명 이 문제의 핵심키워드는 "빈번한 스키마 변경"이다. 데이터베이스에서 스키마는 데이터의 구조 또는 모델을 의미한다. 전통적인 RDBMS는 엄격한 데이터 구조를 설계한다. 시나리오에서는 빈번하게 스키마를 변경해야 하기 때문에 스키마에 엄격한 RDBMS 보다는, NoSQL을 선택해야 한다.  관계형 데이터베이스는 어떤 데이터를 삽입할 지에 대한 제약과 제한을 가진 엄격한 스키마를 가진다. 주로 여러 테이블에서 데이터를 가져오는 복잡한 쿼리를 지원해야 하는 시나리오에서 사용한다. 복잡한 테이블 관계가 있는 시나리오에는 적합하지만 유연한 스키마가 필요한 경우에는 적합한 데이터베이스가 아니다. NoSQL의 경우 테이블/컬랙션 항목에 행이나 요소를 쉽게 추가하거나 제거 할 수 있으며, 관계형 데이터베이스 만큼 엄격하지 않다. 또한 단일 레코드에 복잡한 계층적 데이터를 저장 할 수 있기 때문에 유연하게 스키마를 확장 할 수 있다. 따라서 여기에서는 DynamoDB가 답이다. 관계형 데이터베이스는 아래의 이유로 확장하기가 쉽지 않다. * 데이터를 정규화해야 하기 때문에, 여러 테이블이 필요하게 된다. * ACID 호환 트랜잭션 시스템은 성능 비용을 지불한다. * 값 비싼 join을 사용해야 한다. Dynamodb는 아래의 이유로 확장이 쉽다. * 스키마가 유연해서 단일 항목에 복잡한 계층적 데이터를 저장 할 수 있다. * 복합 키 디자인으로 동일한 테이블에 가까운 관련 항목을 보관 할 수 있다. Redshift는 일반적으로 OLAP를 목적으로 사용하기 때문에 적당한 솔류션이 아니다. Amazon RDS의 Multi-AZ 전개 설정과 Aurora database 는 스키마에 엄격한 관계형 데이터베이스이므로 답이 아니다. 답 : 4 ### Question #21 AWS에서 호스팅되는 온라인 의료 시스템이 있다. 이 시스템은 Amazon S3 버킷에 사용자의 민감한 개인 식별정보 (PII)를 저장한다. 회사의 엄격한 규정 준수 및 규제 요구사항을 준수하기 위해 마스터 키와 암호화되지 않은 데이터가 AWS에 노출되면 안된다. 아키텍트는 어떤 S3 암호화 기술을 사용해야 하는가 ? 1. S3 Server-side encryption with a KMS managed key. 2. Use S3 client-side encryption with a client-side master key. 3. Use S3 server-side encryption with customer provided key. 4. Use S3 client-side encryption with a KMS-managed customer master key. #### 설명 서버측 암호화(Server-side encryption)은 데이터를 받는 애플리케이션 또는 서비스가 해당 대상에서 데이터를 암호화 하는 방법이다. S3에 데이터를 쓰면 객체 수준에서 암호화를 하고 데이터를 읽으면 자동으로 암호를 해독한다. 따라서 요청에 대한 인증만 하면 액세스 권한을 가지게된다. 클라이언트 측 암호화는 S3로 보내기 전에 암호화하는 방식이다. 클라이언트 측 암호화를 사용하려면 키를 관리해야 하는데, 두 가지 옵션이 있다. 1. AWS KMS 관리 형 고객 마스터 키(CMK)를 사용한다. 2. 클라이언트 측 마스터 키를 사용한다. AWS KMS 관리형 고객 마스터 키를 사용하여 데이터를 암호화하는 경우 AWS KMS CMK ID를 AWS에 제출한다. 반면 클라이언트 측 데이터 암호화는 클라이언트 측 마스터 키와 암호화되지 않은 데이터를 AWS로 전송하지 않는다. 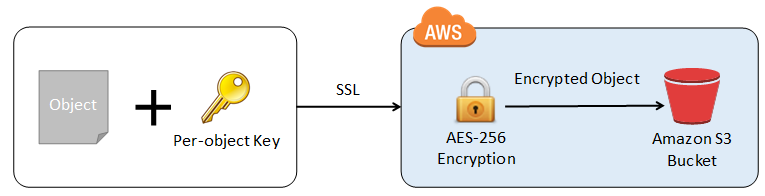 고객 마스터 키를 사용용한 고객 측 암호화가 작동하는 방식은 아래와 같다. 객체를 업로드 할 때 Amazon S3는 일회용(One-time-use) 대칭키를 제공한다. 클라이언트는 무작위로 생성하는 데이터 암호화 키를 암호화 하는 목적으로만 마스터키를 사용한다. 따라서 마스터키는 바깥으로 노출되지 않는다. 1. S3 암호화 클라이언트는 일회용 대칭키(데이터 암호화 키, 혹은 데이터 키라고 부르는)를 로컬에 생성한다. 데이터 키를 사용하여 단일 S3 객체의 데이터를 암호화 한다. 클라이언트는 각 개체에 대해서 별도의 데이터키를 생성한다. 2. 클라이언트는 사용자가 제공한 마스터키를 사용해서 데이터 암호화키를 암호화 한다. 클라이언트는 암호화된 데이터 키와 이것에 대한 설명을 메타 데이터의 일부로 업로드한다. 클라이언트는 메타 데이터의 내용을 토대로 암호화 해독에 사용 할 클라이언트 측 마스터키를 결정한다. 3. 클라이언트는 암호화 된 데이터를 Amazon S3에 업로드하고, 암호화된 데이터키는 x-amz-meta-x-amz-key로 저장한다. 객체를 다운로드 할 때, 클라이언트는 S3에서 암호화된 객체를 다운로드 한다. 클라이언트는 객체 메타데이터를 이용해서 데이터 키를 해독하는데 사용할 마스터 키를 결정한다. 이후 마스터키를 사용해서 데이터 키를 복호화하고, 이 데이터 키를 이용해서 객체를 복호화 한다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [클라이언트 측 암호화를 사용하여 데이터 보호](https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/dev/UsingClientSideEncryption.html) * [S3의 서버측 암호화와 고유 한 암호화 키 사용](https://aws.amazon.com/ko/blogs/aws/s3-encryption-with-your-keys/) 서버측 암호화는 암호화되지 않은 데이터를 S3에 전송하고, S3에서 암호화하는 방식이기 때문에 올바른 방법이 아니다. 답 : 2 ### Question #22 온라인 암호 화폐 교환 플랫폼은 다중 AZ 적용된 ECS 클러스터 및 RDS로 구성된 AWS에서 호스팅되고 있다. 애플리케이션은 복잡한 읽기 및 쓰기 데이터베이스 작업을 처리하기 위해 RDS 인스턴스를 사용하고 있다. 시스템의 안정성, 가용성 및 성능을 유지하려면 각 프로세스에서 사용하는 CPU 대역폭의 비율과 총 메모리를 포함하여 DB 인스턴스의 여러 프로세스 또는 쓰레드가 CPU를 사용하는 방식을 면밀히 검토해야 한다. 다음 중 데이터베이스를 모니터링하는 데 가장 적합한 솔류션은 무엇인가 ? 1. CloudWatch에 CPU 사용율을 게시하는 스크립트를 만들어서 배포하고 CloudWatch 대시보드로 모니터링 한다. 2. 데이터베이스의 CPU 사용율을 CloudWatch로 모니터링 한다. 3. Enhanced Monitoring 옵션을 선택한다. 4. CPU%와 MEM% 메트릭을 수집 하도록 RDS 콘솔에서 체크한다. #### 설명 RDS는 CloudWatch 지표와 Enhanced Monitor 지표를 제공한다. 두 개의 차이점은 아래와 같다. * CloudWatch는 DB 인스턴스의 하이퍼바이저에서 CPU 사용율에 대한 측정치를 수집한다. * Enhanced Monitor는 DB 인스턴스에 설치된 에이전트를 통해서 측정치를 수집한다. Enhanced Monitor는 CloudWatch 메트릭이 아닌 CloudWatch Log로 저장되기 때문에, 추가적인 비용이 들어간다. Enhanced Monitoring은 DB 인스턴스의 여러 프로세스 또는 스레드에 대해서 CPU의 사용을 모니터링 하는데 유용하다. Enhanced Monitor로 수집한 CloudWatch Log는 30일 동안 저장된다. CloudWatch 콘솔에서 보존 기간을 변경 할 수 있다. CloudWatch를 이용해서 데이터베이스의 CPU 사용율을 모니터링하는 것은 올바르지 않다. CloudWatch는 하이퍼바이저 레벨에서 작동하기 때문에 인스턴스의 CPU 사용율을 모니터링 할 수는 있지만 RDS의 각 데이터베이스 프로세스 단위의 CPU 대역폭 비율과 메모리 사용율은 모니터링 할 수 없기 때문이다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [확장 모니터](https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/USER_Monitoring.OS.html) 답 : 3 ### Question #23 매 분 날씨 데이터를 기록하는 애플리케이션은 스팟 EC2 인스턴스 플릿(fleet)에서 배포되며, MySQL RDS 데이터베이스 인스턴스를 사용한다. 현재 하나의 가용 영역에 실행되는 RDS 인스턴스는 하나다. 다른 RDS 인스턴스로 동기식 데이터 복제를 통해 고 가용성을 보장하기 위한 데이터베이스를 설계해야 한다. 다음 중 RDS에서 동기식 데이터 복제를 수행하는 것은 무엇인가 ? 1. DynamoDB Read Replica 2. RDS Read Replica 3. RDS DB instance running as a Multi-AZ deployment 4. CloudFront running as a Multi-AZ deployment #### 설명 Multi-AZ 으로 실행되도록 DB 인스턴스를 생성하거나 수정하면 RDS는 자동으로 다른 가용영역에<span> </span>**동기식 예비 복제본**을 프로비저닝하고 유지한다. Mult-AZ 배포는 가용성과 내구성을 제공하는 서비스다. 기본 인스턴스의 스토리지 볼륨이 Multi-AZ 배포에서 장애를 일으키면, RDS가 최신 예비 인스턴스로 자동 장애 조치를 수행한다. MUlti-AZ 배포와 Read Replica를 혼동할 수 있어서 따로 정리했다. | Multi-AZ Deployments | Read Replica | | -------------------- | ------------ | | 동기식 복제 - 내구성 | 비동기식 복제 - 확장성 | | Primary 데이터베이스 엔진만 active 상태 | 모든 read replica는 읽기 전용으로 액세스 할 수 있다. | | standby로 자동 백업 | 기본 설정은 백업되지 않는다. | | 단일 region의 두 개의 가용영역에 전개 | 동일-AZ, cross-az, cross-region | | 문제가 생기면 자동으로 standby가 페일오버 | 동립형 데이터베이스 인스턴스로 승격한다. | 답 : 3 ### Question #24 웹 애플리케이션은 CloudFront를 사용하여 S3 버킷에 저장된 이미지, 비디오 및 기타 정적 콘텐츠를 전 세계 사용자에게 배포한다. 이 회사는 최근 일부 고품질 미디어 파일에 대한 새로운 회원 전용 액세스를 도입했다. 현재 URL을 변경하지 않고 유료 구독자에게만 여러 개인 미디어 파일에 대한 액세스를 제공해야 한다. 다음 중 이 요구사항을 충족하기 위한 가장 적합한 솔류션은 무엇인가. ? 1. CloudFront의 필드레벨 암호화를 이용해서 개인 데이터를 보호하고 멤버들에 대한 액세스만 허가한다. 2. 서명된 쿠키를 사용해서 파일에 대한 액세스를 제어한다. 멈베들에게는<span> </span>**Set-Cookie**헤더를 전송해서, 쿠키를 전송하고 멤버들은 HTTP 요청시 이 값을 함께 전송한다. 3. 서명된 URL을 이용해서 개인 파일에 접근 할 수 있는 권한을 제어한다. 4. Configure your CloudFront distribution to use Match Viewer as its Origin Protocol Policy which will automatically match the user request. This will allow acess to the private content it the request is a paying member and deny it if it is not a member. #### 설명 CroudFront는 서명된 URL과 서명된 쿠키를 제공한다. 이 둘은 기본적으로 같은 기능을 제공한다. 이 둘을 이용해서 컨텐츠에 액세스 할 수 있는 사용자를 제어 할 수 있다. 서명된 URL과 서명된 쿠키 중 어느 것을 사용할지를 결정하려면 아래를 고려해야 한다. 아래와 같은 경우 서명된 URL을 사용한다. 1. RTMP 배포를 사용해야 한다. RTMP 배포는 서명된 쿠키를 지원하지 않는다. 2. 개별 파일에 대한 액세스를 제어하는 경우(예 : 애플리케이션의 설치 다운로드) 3. 클라이언트가 쿠키를 지원하지 않는 클라이언트를 사용하는 경우 아래와 같은 경우 서명된 쿠키를 사용한다. 1. HLS 형식의 동영상에 대한 모든 파일 또는 웹 사이트의 구독자 영역에 있는 모든 파일과 여러 개의 제한된 파일에 대한 액세스를 제공 2. URL을 변경하고 싶지 않다. 따라서 이 시나리오에 대한 정답은 아래와 같은 옵션이다. 사용자가 콘텐츠에 액세스해야하는지 여부를 결정하기 위해서 애플리케이션을 수정하여 CloudFront에서 배포한 서명된 쿠키를 저장하여 사용도록 한다. 필드 수준암호화는 사용자가 제출한 민감한 정보를 안전하게 업로드 할 수 있도록 하는 기능이기 때문에 올바르지 않다. 여러 개인 파일을 다운로드 할 수 있는 액세스 기능은 제공하지 않는다. 답 : 2 ### [24.](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#toc)<span> </span>Question #25 근무중인 정부기관에서 기밀 세금문서를 AWS 클라우드에 저장하기로 했다. 그러나 보안 관점에서 AWS에 대이터를 저장하는 것이 안전한지에 대한 우려가 있다. 기밀 문서의 데이터 보안을 보장 할 수 있는 AWS의 기능은 무엇인가 ?(2개 선택) 1. Public Data Set Volume Encryption 2. S3 Server Side Encryption 3. S3 Client-Side Encryption 4. EBS on-Premises Data Encryption 5. S3 On-Premises Data Encryption #### 설명 당신은 전송중인 데이터와 저장 데이터에 대한 암호화를 통해서 개인 정보를 보호할 수 있다. 데이터가 EBS 볼륨에 저장되는 경우 EBS 암호화를 활성화 할 수 있으며 Amazon S3에 저장된 경우 클라이언트 측 및 서버측 암호화를 활성화 할 수 있다. 퍼블릭 데이터 세트는 공개적으로 액세스 할 수 있도록 설계되었으므로 퍼블릭 데이터 세트 볼륨 암호화는 올바른 방법이 아니다. 클라이언트 측 암호화는 S3로 보내기 전에 데이터를 암호화하는 것을 가리킨다. 두 가지 옵션이 있다. 1. SSE-KMS에 저장된 CMK를 사용한다. 2. 애플리케이션 내에 저장한 마스터 키를 사용한다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [클라이언트 측 암호화를 사용하여 데이터 보호](https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/dev/UsingClientSideEncryption.html) 답 : 2, 3 ### Question #26 조직은 미션 크리티컬 워크로드에 사용 할 영구 블록 스토리지 볼륨이 필요하다. 백업 데이터는 오브젝트 스토리지 서비스에 저장되며 30일 후에는 데이터 아카이브 스토리지 서비스에 저장된다. 위의 요구 사항을 충족하려면 어떻게 해야 하는가 ? 1. EC2 인스턴스의 스토어 볼륨을 이용한다. 백업 데이터를 S3에 저장하고, 저장된 객체를 Amazon S3 One Zone-IA로 이동 하도록 라이프사이클 정책을 수립한다. 2. EC2 인스턴스에 EBS 볼륨을 붙인다. 백업 데이터를 S3에 저장하고 S3 One Zone-IA로 이동하도록 라이프사이클 정책을 수립한다. 3. EC2 인스턴스에 EBS 볼륨을 붙인다. 백업 데이터를 S3에 저장하고 S3 Glacier로 이동하도록 라이프사이클 정책을 수립한다. 4. EC2 인스턴스에 store volume을 붙인다. 백업 데이터를 S3에 저장하고 S3 Glacier로 이동하도록 라이프사이클 정책을 수립한다. #### 설명 Amazon Elastic Block Store(EBS)는 모든 규모의 처리량과 트랜잭션 집약적인 워크로드를 위해서 EC2와 함께 사용하도록 설계된 고성능<span> </span>**블록 스토리지 서비스**다. 관계형 및 비 관계형 데이터 베이스, 엔터프라이즈 애플리케잇4ㅕㄴ, 컨테이너 방식의 애플리케이션, 빅 데이터 분석 엔진, 파일 시스템, 미디어 워크로드등 광범위한 워크로드에 사용한다. 최적의 성능과 균형을 맞추기 위해서 6개의 서로 다른 볼륨 유형을 제공한다. SAP HANA와 같은 고성능 데이터 워크로드에서 대규모 순차워크로드(Hadoop)와 같은 각 목적에 맞는 볼륨 유형을 사용 할 수 있다. 또한 애플리케이션을 중단하지 않고 볼륨의 유형을 변경, 볼륨 크기 확장, 성능 조정이 가능하다. Amazon Simple Storage Service (Amazon S3)는 확장성, 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스다. 웹 사이트, 모바일 애플리케이션, 백업 및 복원, 아카이브, 엔터프라이즈 애플리케이션, IoT 장치 및 빅 데이터 분석과 같은 다양한 사용 사례에 사용 할 수 있다. S3는 객체의 성격에 따라서 한 스토리지 클래스에서 다른 스토리지 클래스로 전환하는 규칙을 가지는 라이프사이클을 정의 할 수 있다. 이 시나리오는 3가지를 요구한다. 1. 미션 크리티컬 2. 블록 스토리지 3. 전환 가능한 오브젝트 스토리지 EBS와 S3 Standard, S3 Glacier이 조건을 만족한다. Store volume은 인스턴스가 중지되거나 종료하면 데이터가 손실될 수 있으므로 미션 크리티컬한 작업에는 사용 할 수 없다. S3 One Zone-IA도 데이터가 손실 될 수 있으므로 미션 크리티컬한 작업에 적합하지 않다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [Amazon Elastic Block Store](https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/AmazonEBS.html) 답 : 3 ### Question #27 한 회사에서 Amazon S3에 자주 액세스하는 데이터를 저장하고 있다. 객체가 생성되거나 삭제되면 S3 버킷은 Amazon SQS 대기열에 이벤트 알림을 보낸다. 솔류션 아키텍트는 객체가 생성/삭제될 때 개발 및 운영팀에 알람을 하는 솔루션을 만들어야 한다. 다음 중 이 요구사항을 충족하는 것은 무엇인가 ? 1. 다른 팀들을 위한 SNS FIFO 토픽을 생성한다. S3에 SNS 토픽에 알림을 보낼 수 있는 권한을 허용한다. 2. 다른 팀들을 위한 SQS 큐를 만든다. S3에 SQS 큐로 알림을 보낼 수 있는 권한을 허용한다. 3. SNS 토픽을 설정하고 SNS 토픽을 폴링하도록 2개의 SQS 큐를 만든다. S3에 SNS에 알림을 보낼 수 있는 권한을 부여하고 SNS 토픽을 사용 할 수 있도록 버킷 설정을 변경한다. 4. SNS 토픽을 생성하고 구독을 위한 두 개의 SQS 대기열을 구성한다. S3에 SNS에 알림을 보낼 수 있는 권한을 부여하고 새로운 SNS 토픽을 사용 할 수 있도록 버킷을 업데이트 한다. #### 설명 Amazon S3 알림 기능을 사용하면 버킷에 특정 이벤트가 발생 할 때 알림을 받을 수 있다. 알림을 활성화하려면 먼저 S3에서 게시할 이벤트와 S3에서 알람을 보낼 대상을 식별하는 알림 구성을 추가해야 한다. 이 구성을 버킷과 연결된 알림 하위 리소스에 저장한다. S3는 아래의 리소스에 이벤트를 게시 할 수 있다. 1. Amazon Simple Notification Service (SNS) 토픽 2. Amazon Simple Queue Service (SQS) 대기열 3. AWS Lambda Amazon SNS의 팬 아웃 시나리오는 SNS 토픽에 게시된 메시지가 Amazon SQS 대기열, HTTP(S) 앤드 포인트 및 Lambda 함수와 같은 여러 앤드 포인트로 푸시되는 것이다. 이 방식은 병렬 비동기 처리를 허용한다.  주문을 처리하는 애플리케이션을 개발한다고 가정해 보자. 우리는 SNS 토픽에 주문 메시지를 게시하는 애플리케이션을 개발 할 수 있다. SNS 토픽을 구독하는 SQS 대기열은 새 주문에 대한 알람을 받게 될 것이다. SQS 대기열 중 하나에 연결된 Amazon Elastic Compute Cloud 서버 인스턴스는 주문을 처리 할 수 있다. 수신된 주문을 분석하기 위해 다른 Amazon EC2 서버 인스턴스를 데이터웨어 하우스에 연결 할 수 있다. Amazon S3 이벤트 알림은 하나의 대상에 한 번 이상의 메시지가 전달되도록 설계되어 있다. S3 이벤트 알람 하나에 둘 이상의 SNS 토픽, SQS 대기열에 연결 할 수 없다. 따라서 이벤트 알림을 Amazon SNS로 보내야 한다. SNS를 기준으로 하는 Fanout 아키텍처를 사용하면 될 것이다. 이 문제의 경우 SNS 주제츨 구독하는 두 개의 Amazon SQS 대기열을 구성하는 것이다. Amazon S3에 S3에 Amazon SNS를 보낼 수 있는 권한을 부여하고 새로운 SNS 토픽을 사용하도록 버킷을 업데이트 한다.  다른 팀을 위해서 새로운 SNS FIFO 토픽을 생성하고, 두 번째 SNS 토픽으로 알림을 보내는 S3 권한 부여는 올바르지 않다. S3 이벤트 알림은 한번에 한개의 SNS 혹은 SQS만 추가 할 수 있기 때문이다. 답 : 4 ### Question #28 솔류션 아키텍트는 VPC를 모니터링하는 동안 일련의 DDoS 공격을 식별했다. 아키텍트는 클라이언트 데이터를 보호하기 위해 현재 클라우드 인프라를 강화해야 한다. 이런 종류의 공격을 완화하는데 가장 적합한 솔류션은 무엇인가. 1. AWS shield Advanced를 사용하여 DDoS 공격을 탐지하고 완화한다. 2. AWS WAF를 활성화하여 HTTP 트래픽을 필터, 모니터링, 블럭한다. 3. Security group와 Network Access Control을 이용해서 허가된 트래픽된 VPC에 흐르도록 한다. 4. AWS Firewall Manager를 사용하여 SYN 플러드를 방지하는 보안 계층을 설정한다. UDP 반사 공격 및 기타 DDoS 공격도 방어 할 수 있다. #### 설명 AWS Shield는 AWS에서 실행되는 애플리케이션을 DDoS로 부터 보호하는 서비스다. AWS Shield는 애플리케이션 가동 중지 및 지연 시간을 최소화하는 상시 탐지 및 자동 인라인 통합을 제공하므로 DDoS 보호를 위해서 AWS Support를 이용할 필요가 없다. AWS Shield는 Standard와 Advanced 두 가지 옵션이 있다. AWS Shield Advanced 서비스를 이용하면, EC2, ELB, CloudFront, Global Accelerator, Route 53의 리소스에서 실행되는 애플리케이션을 목표로 하는 공격에 대해 더 높은 수준의 보호를 제공한다. Shield Standard가 제공하는 네트워크 및 전송 계층의 보호 외에 정교한 대규모 DDoS 공격에 대한 추가보호 및 완화 실시간 공격에 대한 가시성, WAF의 통합을 제공한다.  따라서 정답은 AWS Shield Advanced를 이용한 DDoS 공격 탐지와 완화다. AWS Firewall Manager는 AWS WAF의 통합 관리 작업을 단순화한느데 사용되는 솔류션이다. 독립적인 보안 계층을 제공하는게 아니므로 올바르지 않다. WAF는 HTTP 트래픽, 모니터링, 필터링, SQL 주입 공격, 교차 사이트 스크립팅과 같은 일반적인 공격 패턴을 차단할 수 있지만 DDoS 공격을 견디기에는 충분하지 않다. 이 시나리오에서는 AWS Shield를 사용하는 것이 좋다. Security Group와 NACL의 조합을 사용하여 VPC 보안을 제공 할 수 있지만 DDoS를 막기에는 충분하지 않다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [AWS DDoS Attack Mitigation](https://d0.awsstatic.com/aws-answers/AWS_DDoS_Attack_Mitigation.pdf) * [DDoS whipe Paper](https://d1.awsstatic.com/whitepapers/Security/DDoS_White_Paper.pdf) 답 : 1 ### Question #29 회사에 Windows Server용 인터넷 정보 서비스(IIS)를 사용하는 웹 응용 프로그램이 있다. 파일 공유는 애플리케이션 데이터를 회사 온 프레미스 데이터센터에 저장하기 위해서 사용한다. 고 가용성 시스템을 달성하기 위해서 애플리케이션 및 파일 공유 시스템을 AWS로 마이그레이션 할 계획이다. 다음 중 이 요구 사항을 만족하는 솔루션은 무엇인가 ? 1. 파일을 Amazon EFS로 마이그레이션 한다. 2. 파일을 EBS로 마이그레이션 한다. 3. 파일을 AWS Storage Gateway로 마이그레이션 한다. 4. 파일을 Windows File Server를 위한 Amazon FSx 로 마이그레이션 한다. #### 설명 **Amazon FSx for Windows File Server**은 Windows Server에 구축되는 완전관리형 파일 스토리지다. FSx는 업계 표준 SMB(서버 메시지 블록) 프로토콜을 통해 액세스 가능한 고도로 안정적이고 확장 가능한 파일 스토리지 서비스를 제공한다. 이 서비스는 Windows Server에 구축되며 사용자 할당량, 최종 사용자 파일 복원 및 AD 통합과 같은 광범위한 관리 기능을 제공한다.  이 시나리오의 목표는 기존 파일 공유 구성을 클라우드로 마이그레이션 하는 것이다. 가장 적당한 옵션은 Amazon FSx 이다. 온 프레미스 공유 파일 구성을 클라우드로 마이그레이션 하기 위해서는 먼저 파일을 Amazon FSx로 마이그레이션 해야 한다. AWS Storage Gateway는 온-프레미스를 AWS에 통합하기 위해서 사용하며, 애플리케이션 마이그레이션에는 사용하지 않기 때문에 올바른 구성이 아니다. Storage Gateway를 사용하겠다는 것은 온-프레미스에 있는 파일 시스템을 그대로 유지하겠다는 의미다. EFS로의 마이그레이션은 회사가 Windows 서버에서 실행되는 파일 공유를 사용하고 있다고 시나리오에 명시되어 있기 때문에 올바르지 않다. EFS는 리눅스 워크로드만 지원한다. EBS는 파일 공유 시스템이 아닌 EC2 블록 스토리지 목적으로 사용하기 때문에 올바른 방법이 아니다. 1. [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [Amazon FSx for Windows File Server](https://aws.amazon.com/ko/fsx/windows/) * [Amazon FSx for Windows File Server FAQ](https://aws.amazon.com/ko/fsx/windows/faqs/) 2. [답](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#)4 ### Question #30 회사는 VPC에 여러 애플리케이션을 호스팅하고 있다. 시스템을 모니터링하는 동안 VPC 내부의 여러 AWS 리소스에 연결을 시도하는 특정 IP 주소 블록의 포트 스캔을 발견했다. 내부 보안 팀은 보안상의 이유로 다음 24 시간 동안 문제가 되는 IP 주소를 거부하도록 요청했다. 다음 중 지정된 IP 주소의 액세스를 빠르게 일시적으로 거부하는 가장 좋은 방법은 무엇인가 ? 1. VPC 퍼블릭 서브넷에 연결된 모든 IP 주소 블록의 액세스를 거부하도록 NACL 규칙을 수정한다. 2. IP 주소의 접근을 거부하도록 EC2 Security group의 룰을 수정한다. 3. IP 주소의 접근을 거부하도록 EC2 방화벽 설정을 수정한다. 4. IP 주소의 접근을 거부하는 IAM 룰을 생성한다. #### 설명 NACL을 사용해서 VPC 네트워크에서 들어오고 나가는 트래픽을 제어할 수 있다. 하나 이상의 서브넷으로 부터의 트래픽을 제어하기 위해서 NACL을 유용하게 사용 할 수 있다. 몇 분안에 규칙을 추가하고 제거 할 수 있으므로 가장 나은 솔류션이다. IAM 정책은 VPC 인바운드 및 아웃바운드 트래픽을 제어하지 않기 때문에 올바른 방법이 아니다. Security Group은 방화벽 역할을 하지만 전체 VPC가 아닌 인스턴스 단위에서 이루어지기 때문에 올바른 방법이 아니다. 다른 인스턴스들은 여전히 공격 받을 수 있다. Security Group을 정교하게 작성하는 방법도 있기는 하지만, 느리고 비효율적이므로 답이 아니다. 답 : 1 ### [30.](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#toc)<span> </span>Question #31 회사는 여러 국가에서 온도, 기압, 습도와 같은 대기 데이터를 수집한다. 각 사이트 위치에는 다양한 기상 기기와 고속 인터넷 연결이 장착되어 있다. 각 위치에서 수집된 데이터는 평균 500GB이며 북부 버지니아에서 호스팅 되는 일기 예보 애플리케이션에 의해 분석된다. 솔류션 아키텍트는 모든 데이터를 가장 빠른 방법으로 집계해야 한다. 다음 중 주어진 요구사항을 충족할 수 있는 옵션은 무엇인가. ? 1. 가장 가까운 S3 버킷에 데이터를 업로드 한다. 교차 리전 복제를 설정하고 객체를 대상 버킷에 복사한다. 2. AWS Snowball Edge를 이용해서 대량의 데이터를 업로드 한다. 3. 목적지 버킷에 대한 Transfer Acceleration을 활성화하고 멀티 파트 업로드를 이용해사 수집한 데이터를 업로드 한다. 4. Site-To-Site VPN을 활성화 한다. #### 설명 S3 Transfer Acceleration을 사용하면 클라이언트와 S3 버킷 간에 파일을 빠르고 쉽게 전송 할 수 있다. Transfer Acceleration는 전 세계에 분산된 Amazon CloudFront의 엣지 로케이션을 활용한다. 엣지 로케이션에 도착한 데이터는 최적화된 네트워크 경로를 통해 Amazon S3로 라우팅 된다.  S3 Transfer Acceleration을 사용하면 컨텐츠의 전송속도를 50\~500% 까지 높일 수 있다. 멀티 파트 업로드를 사용하면 단일 객체를 여러 파트로 나눠서 업로드 할 수 있다. 교차 리전 복제(CRR)은 S3 버킷 전체에 걸쳐 객체를 비동기적으로 자동 복사하는 기능이다. S3 Replication Time Control(S3 RTC)을 사용하면 대새로 저장된 객체를 15분 이내로 복제 할 수 있다. 쓸 수 있는 방법이기는 하지만 대상 버킷에 복제하는데 15분이 걸리기 때문에 적당한 방법은 아니다. 시나리오는 "가장 빠른 방법"을 요구하고 있다. 속도 보다 비용 효율이 우선이라면 이 방법을 고려 할 수 있을 것이다. Snowball Edge는 최대 80TB의 데이터를 전송하는데 1주일 정도의 시간이 걸린다. 대량의 데이터를 전송하는 올바른 방법이 아니다. Snowball Edge는 컴퓨팅 파워를 내장하고 있으므로 데이터를 로컬에서 처리해야 하는 워크로드에 적당하다. * 참고 : S3의 성능 디자인 패턴 4개를 요약했다. * 자주 액세스하는 컨텐츠에 캐싱 사용 : CloudFront, ElasticCache, Elemental MediaStore를 사용한다. * 지연시간에 민감한 애플리케이션의 제한 시간 및 재 시도 : 애플리케이션의 요청속도가 높으면(적은 수의 객체에 대해 초당 5,000 이상의 연속적인요청)<span> </span>**HTTP 503 slowdown**이 수신될 수 있다. 애플리케이션이 이러한 오류를 수신하면 지수 백오프를 사용하여 자동 재시작 로직을 구현한다. * 높은 처리량을 위한 수평 확장 및 요청 병렬화 * Transfer Accleration을 사용하여 지리적으로 다른 데이터의 전송 가속화 링크 * [Amazon S3의 성능 디자인 패턴](https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/userguide/optimizing-performance-design-patterns.html) * [AWS Snowball 사용 사례 - 사막에서 전장으로](https://aws.amazon.com/ko/blogs/publicsector/from-deserts-to-the-battlefield-aws-snowball-edge-brings-technology-to-the-tactical-edge/) 답 : 3 ### Question #32 대규모 금융회사에서 일하고 있는 IT 컨설턴트가 있다. 컨설턴트의 역할은 개발 팀이 상태 비 저장 웹 서버를 사용하여 고 가용성 웹 애플리케이션을 구축하도록 돕는 것이다. 이 시나리오에서 세션 상태 데이터를 저장하는 데 적합한 AWS 서비스는 무엇인가 ? (2개 선택) 1. ElastiCache 2. Glacier 3. DynamoDB 4. RDS 5. Redshift Spectrum #### 설명 대표적인 상태 비 저장 서비스는 "로그인 서비스"다. 상태 비 저장 서비스의 가장 큰 장점은 매우 간단하게 수평 확장 할 수 있다는 것이다. 상태를 저장 할 필요가 없기 때문에 클라이언트 요청은 어떤 서버든지 처리가 가능하다. 하지만 서버가 상태를 비 저장하기 위해서는 상태를 대신 저장하는 시스템이 필요하다. 이런 시스템은 키(key)로 값(value)으로 조회하면 되기 때문에 간단하고 빠른 Key/Value 스토리지를 사용한다.  **DynamoDB**와<span> </span>**ElastiCache**가 적당한 서비스다. 이들 서비스는 고성능의 Key/Value 저장소를 제공한다. **Redshift Spectrum**은 데이터웨어 하우스에 데이터를 직접 쿼리 할 수 있는 데이터웨어 하우징 솔류션이므로 적당하지 않다. Redshift는 OLAP 프로세스에 더 적합하다. RDS는 AWS의 관계형 데이터베이스 솔류션이다. 상태 저장을 위해서 사용 할 수 있지만, 동일한 비용 대비 DynamoDB나 ElastiCache에 비해 비효율적이다. S3 Glacier는 데이터의 장기 보관을 위한 저렴한 클라우드 스토리지다. Glacier은 검색속도가 느리기 때문에 상태 저장 목적으로 사용 할 수 있다. 답 : 1, 3 <br> ### Question #33 새로 고용된 솔류션 아키텍트는 CloudFormation을 이용해서 회사의 클라우드 아키텍처를 관리해야 한다. 아키텍트는 템플릿에 액세스하여 S3 버킷에 대한 IAM 정책을 분석중이다. ```json5 { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Get*", "s3:List*" ], "Resource": "*" }, { "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::tutorialsdojo/*" } ] } ``` 위의 IAM 정책이 허용하는 것을 선택하라.(3개) 1. IAM 유저가 tutorialsdojo S3 버킷에 있는 객체의 읽기와 삭제를 허용한다. 2. IAM 유저는 tutorialsdojo S3 버킷에 있는 객체를 읽을 수 있지만 목록을 읽을 수는 없다. 3. IAM 유저는 계정이 소유하고 있는 모든 S3 버킷의 객체를 읽을 수 있다. 4. IAM 유저는 tutorialsdojo S3 버킷의 객체를 읽을 수 있다. 5. IAM 유저는 tutorialsdojo S3 버킷에 객체를 쓸 수 있다. 6. IAM 유저는 tutorialsdojo S3 버킷의 객체의 접근 권한을 변경할 수 있다. #### 설명 인프라 관리자는 IAM 자격증명(사용자, 그룹, 역할)을 이용해서 AWS 자원에 대한 액세스를 관리 할 수 있다. 정책(policy)는 자격 증명 또는 리소스와 연결할 때의 권한을 정의하는 AWS 객체다. AWS는 IAM의 보안 주체가 리소스에 대한 작업을 요청할 때, 이 정책을 평가한다. 정책은 요청의 허용 여부를 결정한다. 대부분의 정책들은 AWS에 JSON 형태로 저장된다. AWS는 6가지 타입의 정책을 제공한다. * 자격 증명 기반 정책 : IAM 사용자, 그룹 또는 역할에 연결된다. 이러한 정책으로 자격 증명이 수행 할 수 있는 작업(권한)을 지정 할 수 있다. 예를 들어 John이라는 사용자에게 Amazon EC2 RunInstances 작업을 수행하도록 허용하는 정책을 연결할 수 있다. * 리소스 기반 정책 : 리소스에 연결된다. 예를 들어 Amazon S3 버킷, Amazon SQS 대기열, AWS Key Management Service 암호화 키에 리소스 기반 정책을 연결 할 수 있다. * 권한 경계 : AWS는 IAM 엔터티(사용자 또는 역할)에 대한 권한 경계를 지원한다. 권한 경계는 권한의 경계만 정의하지 실제 권한을 부여하지는 않는다. 권한 경계는 관리형 정책을 사용하여 자격 증명 기반 정책을 통해 IAM 엔터티에 부여 할 수 있는 최대권한을 설정하는 고급 기능이다. 엔터티의 권한 경계는 자격 증명 기반 정책 및 관련 권한 경계 모두에서 허용되는 작업만 수행하도록 허용한다. 권한 경계를 이용하면 실수로 더 많은 권한을 허용하는 것을 막을 수 있다. 예를 들어 yundream 이라는 IAM 사용자에게 S3, CloudWatch, EC2의 모든 작업을 수행하도록 권한 경계를 허용 할 경우, "iam:CreateUser"과 같은 정책을 yundream에게 연결한다고 해도, 권한 경계를 벗어나기 때문에 yundream이 유저를 생성하려고 해도 작업이 실패한다. * AWS Organizations SCP : AWS Organizations 서비스 제어 정책(SCP)을 사용하여 조직 또는 조직 단위(OU)의 계정 멤버에 대한 최대 권한을 정의합니다. SCP는 자격 증명 기반 정책이나 리소스 기반 정책을 통해 계정 내 엔터티(사용자나 역할)에 부여하는 권한을 제한하지만, 권한을 부여하지는 않습니다. * ACL : ACL을 사용하여 ACL이 연결된 리소스에 액세스할 수 있는 다른 계정의 보안 주체를 제어합니다. ACL는 리소스 기반 정책과 비슷합니다. 다만 JSON 정책 문서 구조를 사용하지 않은 유일한 정책 유형입니다. ACL은 지정된 보안 주체에 권한을 부여하는 교차 계정 권한 정책입니다. ACL은 동일 계정 내 엔터티에 권한을 부여할 수 없습니다. * 세션 정책 : AWS CLI 또는 AWS API를 사용하여 역할이나 연합된 사용자를 수임할 때 고급 세션 정책을 전달합니다. 세션 정책은 역할이나 사용자의 자격 증명 기반 정책을 통해 세션에 부여하는 권한을 제한합니다. 세션 정책은 생성된 세션에 대한 권한을 제한하지 않지만, 권한을 부여하지도 않습니다. 자세한 정보는 세션 정책을 참조하십시오 제공된 IAM 정책을 분석해보자. 이 IAM 정책은 2개의 statement를 가지고 있다. 1. 모든 버킷에 대한 S3 GET과 S3 List를 허용한다. 2. tutorialsdojo 버킷에 대한 PutObject를 허용한다. 따라서 답은 3, 4, 5 이다. 답 : 3,4,5 ### Question #34 한 회사는 온 프레미스 워크로드를 AWS로 마이그레이션 할 계획이다. 현재 아키텍처는 Windows 공유 파일 저장소를 사용하는 Microsoft SharePoint 서버로 구성된다. 솔류션 아키텍트는 고가용성의 액세스 제어 및 인증을 서비스를 위해 Active Directory와 통합 할 수 있는 클라우드 스토리지 솔류션을 사용해야 한다. 다음 중 주어진 요구 사항을 충족 할 수 있는 옵션은 무엇인가. 1. AWS Storage Gateway를 이용해서 NFS(Network File System)을 구성한다. 2. 윈도우즈 파일 서버용 Amazon FSx를 이용해서 파일 시스템을 구성하고 AWS Active Directroy에 연결한다. 3. Amazon EFS로 파일 시스템을 구성하고 Active Directory domain에 연결한다. 4. EC2 Windows 서버를 실행하고 S3 버킷을 파일 볼륨으로 마운트한다. #### 설명 Windows 파일 서버용 Amazon FSx는 업계 표준 SMB 프로토콜을 통해서 액세스 할 수 있는 파일 스토리지를 제공한다. FSx는 윈도우즈 서버에 구축되며 사용자 할당량, 최종 사용자 파일 복원 및 AD 통합과 같은 광범위한 관리 기능을 제공한다. Amazon FSx 는 윈도우즈, 리눅스, MacOS 컴퓨팅 인스턴스에서 액세스 할 수 있다. Amazon FSx는 Microsoft Active Directory와 함께 작동하여 기존 Microsfot Windows 환경과 통합된다. 파일 시스템에 대한 사용자 인증 및 액세스 제어를 제공하는 두 가지 옵션은 AWS Managed Microsoft Active Directory와 자체 관리하는 Microsoft Active Directory다. 따라서 정답은 Amazon FSx를 이용하여 파일 서버를 생성하고 AWS의 Active Directory 도메인에 조인하는 것이다. Amazon EFS를 사용하여 AD 도메인에 조인하는 옵션은 EFS가 윈도우즈 시스템을 지원하지 않기 때문에 올바르지 않다. Amazon EC2 윈도우즈 서버를 시작하고 S3 버킷을 파일 볼륨을 마운트하는 옵션은 S3를 AD와 통합할 수 없기 때문에 올바르지 않다. 답 : 2 ### Question #35 회사는 AWS와 온-프레미스 데이터 센터를 연결하는 하이브리드 클라우드 아키텍처를 보유하고 있다. 온-프레미스에 저장된 회사 문서에 대한 내구성 있는 스토리지 백업과 최근 액세스 한 데이터에 대한 짧은 대기 시간 액세스를 제공하여 데이터 송신 요금을 줄이는 로컬 캐시가 필요하다. 문서들은 SMB 프로토콜을 통해 AWS에 저장되고 AWS에서 검색해야 한다. 이러한 파일은 6개월 동안 몇 분 내에 즉시 액세스 할 수 있어야 하며, 데이터 규정 준수를 충족하기 위해 10년 동안 보관해야 한다. 다음 중 이 시나리오를 구현 할 수 있는 가장 효과적이고 비용 효율적인 방법은 무엇인가 ? 1. VPC와 온-프레미스 네트워크를 Direct Connect로 연결한다. 문서들은 Amazon EBS 볼륨에 올리고 S3에 저장되는 EBS 의 스냅샷의 라이프사이클을 설정하여 S3 Glacier로 저장되게 한다. 2. AWS Storage Gateway를 이용해서 온-프레미스 데이터 센터와 연결되는 파일 게이트웨이를 실행한다. 파일 게이트웨이에 업로드되는 문서들은 Glacier로 이동하도록 라이프사이클 정책을 설정한다. 3. 온-프레미스 네트워크의 파일들을 AWS Snowmobile로 마이그레이션 한다. S3 버킷에 문서들을 업로드하고 Glacier로 이동하도록 라이프사이클 정책을 설정한다. 4. AWS Storage Gateway를 이용해서 온-프레미스 데이터 센터와 연결되는 테이브 게이트웨이를 실행한다. 테이프 게이트웨이를 통해서 업로드된 문서는 Glacier로 이동하도록 라이프사이클 정책을 설정한다. #### 설명 AWS 스토리지 게이트웨이는 온-프레미스 IT 환경과 클라우드 기반 스토리지를 연결하는 온-프레미스 소프트웨어 어플라이언스다. 이 서비스를 이용해서 데이터를 AWS 클라우드 스토리지로 저장 할 수 있으며, 확장 가능하고 비용 효율적인 스토리지 환경을 구축 할 수 있다. 온-프레미스는 다양한 워크로드의 파일이 있으며, 스토리지 게이트웨이는 이러한 워크로드들을 지원할 수 있는 타입을 지원한다. * 파일 게이트웨이 : 파일 게이트웨이는 S3에 대한 파일 인터페이스를 지원한다. 이 조합을 이용하면 NFS, SMB와 같은 업계 표준 파일 프로토콜을 사용하여 Amazon S3에 파일을 저장하고 검색 할 수 있다. * 볼륨 게이트웨이 : 온-프레미스 애플리케이션 서버에스 iSCSI 로 클라우드 기반 스토리지 볼륨을 사용 할 수 있다. * 테이프 게이트웨이 : 클라우드 기반 가상 테이프 스토리지를 제공한다. Glacier 혹은 Deep Archive에 데이터를 보관 할 수 있다.  파일 게이트웨이를 이용해서 S3 객체를 온-프레미스에 제공 할 수 있다. 파일 게이트를 이용해서 할 수 있는 일은 아래와 같다. 1. NFS 버전 3, 4.1 프로토콜을 사용하여 파일을 저장하고 검색 할 수 있다. 2. SMB 버전 2, 3을 이용해서 파일을 저장하고 검색 할 수 있다. 3. AWS 클라우드 애플리케이션 혹은 웹 콘솔에서 Amazon S3의 데이터에 직접 액세스 할 수 있다. 4. S3의 수명주기 정책, 교차리전 복제 및 버전관리를 사용하여 S3 데이터를 관리 할 수 있다. 파일 게이트웨이는 일종의 S3 의 파일 시스템 마운트로 생각 할 수도 있다. AWS S3는 객체에 대한 스토리지 클래스를 선택 할 수 있으며, 수명주기 정책을 이용해서 Amazon Glacier등의 다른 클래스로 전환 할 수 있다. 따라서 정답은 2번이다. AWS Storage Gateway의 테이프 게이트웨이의 경우 Amazon Glacier를 이용 비용 효율적인 아카이브 백업 저장소를 제공하지만 즉시 검색 해야 하는 기준을 충족하지 못하기 때문에 답이 아니다. AWS Snowmobile는 초대용량 데이터를 AWS로 이전하는데 사용하는 엑사바이트 규모의 데이터 전송 서비스다. 마이그레이션 서비스이므로 올바르지 않다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) 1. [AWS Snowmobile](https://aws.amazon.com/ko/snowmobile/) 2. [AWS Storage Gateway 작업 방법](https://docs.aws.amazon.com/ko_kr/storagegateway/latest/userguide/StorageGatewayConcepts.html) 답 : 2 <br> ### Question #36 Forex 거래 플랫폼은 데이터 센터를 가지고 있으며, 오라클 데이터베이스를 이용해서 글로벌 금융 데이터를 처리하고 있다. 최근 데이터 센터의 냉각 문제가 발생하면서 애플리케이션의 성능을 개선하기 위해 지금의 인프라를 AWS로 긴급하게 마이그레이션 하기로 했다. 솔류션 아키텍트는 데이터베이스가 올바르게 마이그레이션 되었는지 확인 하고, 향후 데이터베이스 서버 오류가 발생하는 경우에도 계속 사용 할 수 있도록 해야 한다. 다음 중 요구 사항을 충족하는데 가장 적합한 솔류션은 무엇인가. 1. AWS Schema Conversion 툴과 AWS Database Migration 서비스를 이용해서 데이터스키마를 변경한다. 오라클 데이터베이스를 아마존 오로라 싱글인스턴스(non-cluster)로 마이그레이션한다. 2. RDS 위에 Oracle Real Application Clusters(RAD)를 실행한다. 3. 오라클 데이터베이스 RDS를 Multi-AZ로 실행한다. 4. 오라클 데이터베이스 RDS를 RMAN(Recovery Manager)와 함께 실행한다. #### 설명 Amazon RDS의 다중 AZ 배포는 데이터베이스 인스턴스에 가용성과 내구성을 제공하므로 프러덕션 워크로드에 자연스럽게 적용 할 수 있다. 다중 AZ 인스턴스를 프로비저닝하면 Amazon RDS가 자동으로 DB 인스턴스를 생성하고 다른 가용용역에 있는 대기 인스턴스를 동기식으로 복제한다. 각 AZ는 물리적으로 분리되는 독립적인 자체 인프라를 가지기 때문에 매우 안정적으로 운영 할 수 있다.  인프라 장애가 발생하면 대기 중인 Amazon RDS로 자동으로 장애조치를 수행하므로 장애조치가 완료되는 즉시 데이터베이스 작업을 재개 할 수 있다. DB 인스턴스의 엔드 포인트는 그대로 유지되기 때문에 장애조치 후에도 애플리케이션을 수동 관리 할 필요가 없다. 이 시나리오에 사용하기 가장 좋은 RDS 구성은 기본 데이터베이스 인스턴스가 다운 되더라도 고 가용성을 보장해주는 다중 AZ 배포를 하는 오라클 RDS 데이터베이스다. RDS는 Oracle RMAN 및 RAC를 지원하지 않기 때문에 올바르지 않다. RMAN은 백업과 복구를 위한 전용 서비스다. 관리자가 RMAN에게 명령하면 RMAN이 자동으로 백업/복구를 수행한다. RAC를 이용하면 오라클 데이터베이스 인스턴스의 클러스터를 구성 할 수 있다. 두 개 이상의 독립된 서버들과 Disk를 하나로 연결하는 기법으로 사용자가 클러스터로 구성된 서버들 중 어느 서버에도 동일한 Disk를 액세스하게 되므로 가용성과 내구성을 확보 할 수 있다. AWS Schema Conversion 툴과 AWS Database Migration Service는 데이터 스키마의 변환에 사용한다. 오라클 데이터베이스를 단일 인스턴스가 있는 비 클러스터 Amazon Auroroa로 마이그레이션 할 수는 있지만 Oracle 데이터베이스를 Aurora로 마이그레이션하는데 많은 시간이 걸리므로 적합한 방법은 아니다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [AWS Schema Conversion Tool](https://docs.aws.amazon.com/ko_kr/SchemaConversionTool/latest/userguide/CHAP_Welcome.html) * [Oracle RAC](https://myalpaca.tistory.com/17) 답 : 3 ### Question #37 AI 기술을 이용하는 Forex 애플리케이션은 기계 학습 모델을 훈련하기 위해 수천개의 데이터 세트를 사용한다. 애플리케이션의 워크로드에는 교육 데이터 세트를 동시에 처리하기 위한 고성능 병렬 핫 스토리지가 필요하다. 또한 수익이 낮은 데이터 세트를 보관하기 위한 비용 효율적인 콜드 스토리지가 필요하다. 위의 워크로드를 지원하는 적절한 Amazon 스토리지 서비스는 무엇인가. 1. Amazon EFS와 핫/콜드 스토리지를 위한 S3 2. Lustre용 Amazon FSx 와 핫/콜드 스토리지를 위한 S3 3. 윈도우즈 파일 서버를 위한 Amazon FSx와 핫/콜드 스토리지를 위한 S3 4. Lustre용 Amazon FSx와 핫/콜드 스토리지를 위한 IOPS 프로비저닝 EBS(io1) #### 설명 **핫 스토리지**는 즉시 액세스해야 하는 데이터다. 저장된 정보가 업무상 필요 할 때, 기다리지 않고 바로 액세스 해야 할 때 핫 스토리지를 사용한다. 이러한 종류의 데이터는 일반적으로 하이브리드 또는 계층형 스토리지 환경에 저장한다. 서비스가 hot 할 수록 최신 드라이브, 빠른 프로토콜을 사용하는 계층에 위치 할 가능성이 높아진다. 대화 형 비디오 편집, 웹 콘텐츠, 온라인 거래 등이 여기에 해당한다. **콜드 스토리지**는 덜 자주 액세스되는 데이터이며, 핫 스토리지 처럼 빠르게 엑세스 할 필요가 없다. 여기에는 더 이상 사용하지 않는 수 개월에서 수 년 이상 저장해야 할 데이터가 포함된다. 오래된 프로젝트 데이터, 재무, 법률, HR, 비즈니스 정보 등이 포함된다. Amazon FSx For Luster 는 고성능의 확장 가능한 스토리지를 제공하는 관리형 서비스다. 기계 학습, 고성능 컴퓨팅(HPC), 동영상 렌더링, 금융 시뮬레이션과 같은 워크로드에 적합하다. Lustre 파일 시스템은 병렬 분산 파일 시스템으로 Linux + Cluster의 혼성어다. 질문의 요구 사항은 두 가지다. 1. 학슴 모델 데이터 세트를 동시에 처리하기 위한 고성능 병렬 핫 스토리지 2. 자주 액세스하지 않는 아카이브 된 데이터 세티를 유지하기 위한 비용 효율적인 콜드 스토리지 1의 경우 Amazon FSx For Luster를 사용 할 수 있다. 두 번째 요구사항은 Amazon S3를 사용하여 해결 할 수 있다. Amazon S3 Clacier 혹은 Glacier Deep Archive를 통해서 콜드 스토리지를 구축 할 수 있다. 따라서 답은 Amazon FSx for Luster과 Amazon S3의 사용이다. 프로비저닝된 IOPS SSD는 I/O 집약적 워크로드 요구사항을 충족하기 위해서 사용한다. EBS는 Cold HDD라는 옵션이 있기는 하지만 콜드 데이터를 저장하는데는 사용하지 않는다. 또한 Cold HDD를 사용하는 것 보다는 S3 Glacier 혹은 Glacier Deep Archive를 사용하는게 훨씬 비용 효율적이다. EFS는 데이터에 대한 동시 액세스를 지원하지만 기계 확습 워크로드를 위한 고성능을 지원하지는 않기 때문에 올바르지 않다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [Amazon FSx for Lustre](https://aws.amazon.com/ko/fsx/lustre/) 답 : 2 ### Question #38 귀하가 근무하는 기술회사는 총소유비용(TCO)관점에서 S3를 도입했다. 그 결과 1200 명의 모든 직원이 개인 문서 저장을 위해서 S3를 사용 할 수 있는 권한이 부여 되었다. 회사 AD 또는 LDAP 디렉토리의 싱글 사인온 기능을 통합하고 각 개별 사용자의 접근권한을 S3 버킷 별로 지정된 사용자 폴더로 제한하는 설정을 하려 한다. 다음 중 고려해야 할 사항을 선택하라. (2개 선택) 1. 버킷에 대한 IAM 롤과 IAM 정책 설정 2. Amazon workdocs를 사용하여 각 개별 사용자를 지정된 S3 폴더에 맵핑하여 문서에 액세스한다. 3. S3 버킷에 접속해야 하는 1200 명 사용자의 회사 디렉토리를 S3 버킷의 폴더에 매칭시킨다. 4. Federation 프럭시 혹은 identity provider를 설정하고 AWS Security Token Service를 이용하여 임시 토큰을 생성한다. 5. Atlassian Crowd와 같은 Single Sign-On 솔류션을 이용한다. #### 설명 이 질문은 AWS 임시 자격증명에 대한 일반적인 시나리오의 예제 중 하나다. 임시 자격 증명은 자격 증명 연둥, 위임, 교차 계정 액세스 및 IAM 역할과 관련된 시나리오에서 유용하다. 이 예제에서는 싱글 사인온 기능도 설정해야 한다는 점을 고려하여 엔터프라이즈 ID Federation 구성이라고 할 수 있다. 정답은 아래와 같다. * 페더레이션 프록시 또는 ID 공급자 설정 * 임시 토큰을 생성하기 위한 AWS Security Token Service 설정 * 버킷에 액세스하기 위한 IAM 역할 및 IAM 정책 구성 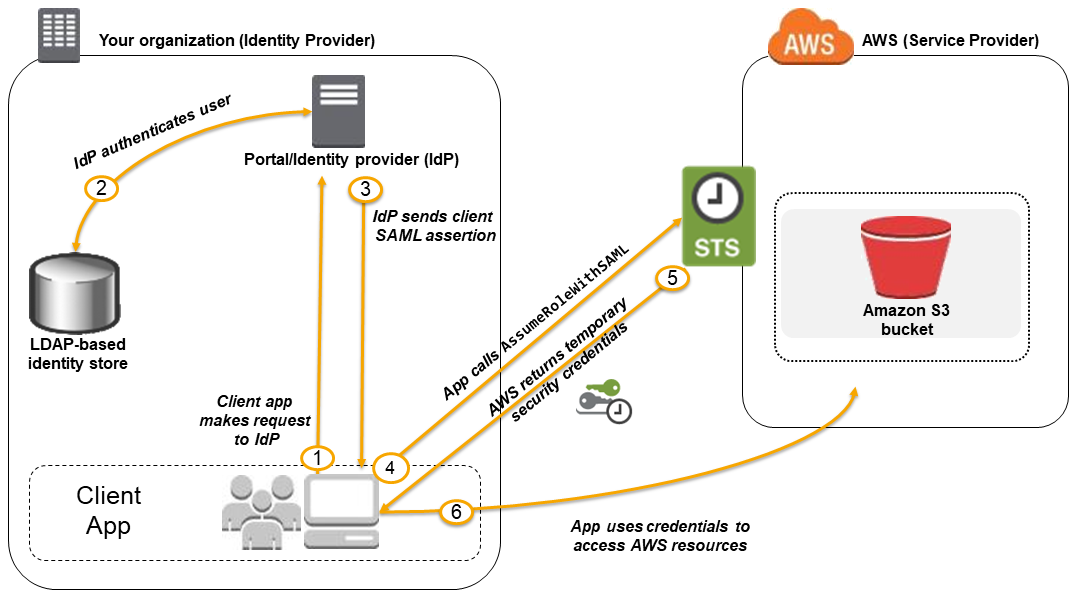 <br> #### 참고 기업 환경에 엔터프라이즈 자격 증명 시스템을 가지고 있을 경우, AWS에 분리된 자격증명 시스템을 만들어서 이들을 연결하는 방법을 사용한다. 이렇게 해서 AWS 자원에 대한 별도의 인증 절차없이 액세스 권한을 부여 할 수 있다. 이렇게 단일한 인증을 거쳐서 액세스 할 수 있도록 하는 방식을 SSO 라고 한다. AWS STS는 SAML(Security Assertion Markup Language) 2.0과 같은 개방형 표준을 지원하며, 이를 통해 Microsoft AD FS를 사용 Microsoft Active Directory를 통합할 수 있다. Atlassian Crowd, OKTA, OneLogin 과 같은 타사 Single Sign-On 솔류션을 사용하는 방법도 있으나, AWS는 이 상황에서 사용 할 수 있는 필요한 도구를 이미 제공하고 있기 때문에 좋은 방법이 아니다. Amazon WorkDocs는 S3를 WorkDocs와 통합하는 방법이 없기 때문에 올바른 방법이 아니다. Amazon WorkDocs는 완전관리형의 콘텐츠 생성, 저장 및 협업 서비스다. 시나리오의 관리자는 수많은 IAM 사용자를 생성하고 싶지 않을 것이다. 또한 계정이 AD 또는 LDAP와 통합하기를 원하기 때문에 IAM 사용자는 이러한 기준에 맞지 않는다. 답 : 4 ### Question #39 한 정부기관이 도시의 인구 및 주택 조사를 실시하고 있다. 온라인 포털에 업로드된 각 가구의 정보는 Amazon S3에 암호화된 파일 형태로 저장된다. 정부는 솔류션 아키텍트에게 민감한 데이터를 보호하는 규정 준수 정책을 설정하도록 했다. 또한 개인 식별 정보(PII), 건강정보(PHI), 지적재산(IP)가 손상될 경우 경고를 발생시켜야 한다. 다음 중 설계자가 이 요구 사항을 충족하기 위해서 구현해야 하는 것은 무엇인가. ? 1. Amazon S3 데이터의 변화를 감지하도록 Amazon Macie 모니터를 설정한다. 2. Amazon S3 데이터의 변화를 감지하도록 Amazon Rekognition을 설정한다. 3. Amazon S3 데이터의 변화를 감지하도록 Amazon Inspector를 설정한다. 4. Amazon S3 데이터의 변화를 감지하도록 Amazon GuardDuty를 설정한다. #### 설명 Amazon Macie는 완전관리형 데이터 보안 및 데이터 프라이버시 서비스로, 기계 학습 및 패턴 일치를 활용하여 AWS에서 민감한 데이터를 검색하고 보호한다. Macie는 암호화되지 않은 버킷, 공개적으로 액세스 가능한 버킷, AWS Organization에 정의되지 않는 AWS 계정과 공유된 버킷의 목록을 모니터링한다. Macie는 선택한 버킷에 기계 학습 및 패턴 매칭 기법을 적용하여 개인 식별 정보(PII)와 같은 민감한 데이터를 식별하고 사용자에게 알린다. Rekognition은 객체, 사람, 텍스트의 활동을 식별하고 부적절한 것을 감지 할 수 있는 서비스이기 때문에 올바른 솔류션이 아니다. GuardDuty는 악성 활동과 무단 동작을 지속적으로 모니터링 하여 AWS 계정과 워크로드를 보호하는<span> </span>**위협탐지시스템**이다. GuardDuty는 AWS CloudTrail 이벤트로그, VPC Flow Log, DNS 로그 등과 같은 이벤트를 분석한다. Amazon Inspector은 AWS에 배포된 애플리케이션의 보안 및 규정준수를 개선하는데 사용 할 수 있는 자동 보안 평가 서비스다. Inspector는 모범 사례를 이용해서 애플리케이션의 노출, 취약성 및 편차를 자동으로 평가한다. Amazon Inspector 보안 평가는 Amazon EC2 인스턴스의 의도하지 않은 네트워크 접근과 EC2 인스턴스의 취약성을 확인하는데 도움을 준다. 답 : 1 ### Question #40 리눅스와 윈도우즈 EC2 인스턴스로 구성된 클라우드 아키텍처를 보유한 회사가 있다. 이 회사는 하루 24시간 대량의 재무 데이터를 처리한다. 시스템의 고 가용성을 보장하기 위해 솔류션 아키텍트는 모든 인스턴스의 메모리, 디스크 사용율을 모니터링 할 수 있는 솔류션을 만들어야 한다. 가장 적합한 솔류션을 선택하라. 1. 기본 CloudWatch 설정을 이용해서 EC2 인스턴스의 메모리와 디스크 사용율을 모니터링 한다. 모든 EC2 인스턴스에 AWS System Manager(SSM)를 설치한다. 2. 모든 EC2 인스턴스에 Amazon Inspector를 설치한다. 3. 모든 EC2 인스턴스에 CloudWatch 에이전트를 설치하여 메모리와 디스크 사용율 메트릭을 수집한다. 수집한 메트릭은 CloudWatch 콘솔에서 확인한다. 4. EC2의 Enhanced Monitoring 옵션을 설정하고, 모든 EC2 인스턴스에 CloudWatch 에이전트를 설치하고 CloudWatch 대시보드에서 메모리와 디스크 사용율을 확인한다. #### 설명 Amazon CloudWatch는 CPU 사용률, 네트워크 사용률, 디스크 성능 및 디스크 읽기/쓰기 모니터링을 위한 EC2 지표를 수집할 수 있다. 아래 항목의 경우에는 메트릭을 사용할 준비가 되어 있지 않으므로 Perl, 쉘 스크립트를 사용해서 사용자 지정 메트릭을 준비해야 한다. * 메모리 사용율 * 디스크 스왑 사용율 * 디스크 사용율 * Page file 사용율 * 로그 수집 AWS는 리눅스와 윈도우즈 기반 인스턴스에 설치 할 수 있는 CloudWatch 에이전트를 제공한다. 단일 에이전트를 사용해서 Amazon EC2 인스턴스와 온프레미스 서버의 시스템 지표와 로그 파일을 모두 수집 할 수 있다. 따라서 정답은 메모리 및 디스크 사용 데이터를 수집하는 CloudWatch 에이전트를 EC2 인스턴스에 설치하는 것이다. CloudWatch의 기본 설정은 메모리와 디스크 사용율 지표를 제공하지 않는다. 이 상태에서 SSM 에이전트를 설치하는 것은 올바르지 않다. AWS System Manager는 AWS 인프라에 대한 가시성과 제어를 제공한다. System Manager를 사용해서 Amazon EC2 인스턴스, Amazon EKS 클러스터, Amazon S3, Amazon RDS 인스턴스와 같은 리소스를 애플리케이션별로 그룹화하고 모니터링과 문제 해결을 위한 운영 데이터를 보고, 사전 승인된 변경 워크로드의 구현, 리소스 그룹에 대한 운영 변경을 감사 할 수 있다. Enhanced Monitoring은 EC2 인스턴스가 아닌 RDS 인스턴스에 대한 것이다. 따라서 올바른 옵션이 아니다. 이 문제에서 핵심은 CloudWatch의 메트릭 수집 범위다. CloudWatch는 VM 레벨에서 메트릭을 수집하기 때문에, 운영체제 레벨의 메트릭인 메모리 사용율, 디스크 사용율, 프로세스의 메트릭은 수집 할 수 없다. 따라서 운영체제 레벨에서 실행되는 CloudWatch 에이전트가 필요하다. RDS의 경우에도 CloudWatch 에이전트를 설치해야 겠으나, 메니지드 서비스 이기 때문에 Enhanced CloudWatch가 이 일을 대신한다. Amazon Inspector는 인스턴스의 네트워크와 애플리케이션 보안 상태를 테스트하는 보안 평가 서비스다. 답 : 3 ### Question #41 Amazon ECS Cluster로 구성된 도커 애플리케이션이 있다. 이 애플리케이션은 로드밸런서로 관리되며, DynamoDB를 주로 사용한다. 솔류션 아키텍트는 워크로드를 균등하게 분배하고 프로비저닝된 처리량을 효율적으로 사용 할 수 있도록 데이터베이스 성능을 개선하라는 미션을 받았다. 다음 중 DynamoDB 테이블 구현에 고려해야 할 사항은 무엇인가 ? 1. 파티션 키와 정렬키로 구성된 복합 프라이머리 키를 사용하지 않는다. 2. 각 항목에 대해서 서로 다른 값이 낮은 카디널리티 속성이 있는 파티션키를 사용한다. 3. DynamoDB 테이블의 파티션 키 수를 줄인다. 4. 각 항목에 대해 많은 고유 값이 있는 높은 카디널리티 속성의 파티션 키를 사용한다. #### 설명 DynamoDB는 내부 해시 함수에 대한 입력으로 파티션 키 값을 사용한다. 이 파티션키를 이용해서 아이템을 저장할 파티션(DynamoDB 내부의 물리적 스토리지)가 결정된다. 따라서 I/O 요청을 균등하게 분배하지 않는 파티션 키 디자인은 프로비저닝된 I/O 용량을 비효율적으로 사용하는 "hot"파티션을 생성 할 수 있다. 테이블의 프로비저닝된 처리량의 최적 사용량은 개별 항목의 워크로드 패턴뿐 아니라 파티션 키 설계에 따라 달라진다. 해시 함수의 효율성은 얼마나 각 파티션 공간에 잘 분산되는지에 따라 결정된다. 좋은 방법은 각 항목에 많은 수의 고유 값을 가지는 높은 커디널리티 속성이 있는 파티션키를 사용하는 것이다. 카디널리티는 중복도에 대한 것으로 중복도가 낮으면 높은 카디널리티, 중복도가 높으면 낮은 카디널리티를 가진다고 한다. 답 : 4 ### Question #42 한 회사가 Application Load Balancer 뒤에 EC2 인스턴스를 오토 스케일링 그룹으로 묶어서 전자 상거래 서비스를 호스팅 하고 있다. 솔류션 아키텍트는 웹 사이트가 IP 주소가 지속적으로 변경되는 여러 시스템으로 부터 많은 수의 불법 외부 요청을 받고 있음을 발견했다. 성능 문제를 해결하기 위해서 솔류션 아키텍트는 합법적인 트래픽에 미치는 영향을 최소화 하면서 불법 요청을 차단하는 솔류션을 구현해야 한다. 다음 중 이 요구사항을 충족하는 옵션은 무엇인가 ? 1. Custom Network ACL을 만든 다음 Application Load Balancer의 서브넷과 연결해서 문제가되는 요청을 차단한다. 2. 문제가되는 요청을 차단하기 위해서 Application Load Balancer를 위한 시큐리티 그룹을 만든다. 3. Rate 기반의 AWS WAF를 만든 다음 Application Load Balancer의 웹 ACL에 연결한다. 4. AWS WAF에 regular 룰을 만든다음 Application Load Balancer의 웹 ACL에 연결한다. #### 설명 AWS WAF는 CloudFront, Application Load Balancer, Amazon API Gateway 및 AWS AppSync와 긴밀하게 통합된다. Amazon CloudFront에서 AWS WAF를 사용하면 최종 사용자와 가까이에 위치한 모든 AWS Edge 위치에서 WAF가 실행된다. 이는 보안이 성능을 희생시키지 않음을 의미한다. 차단된 요청은 웹 서버에 도달하기 전에 중지된다. Application Load Balancer, Amazon API Gateway 및 AWS AppSync와 같은 리전 서비스에서 AWS WAF를 사용하면 각 리전에서 WAF 규칙이 실행되며, 인터넷으로 연결되는 리소스와 내부 리소스를 보호하는데 사용 할 수 있다. 웹 ACL의 규칙을 사용하여 아래와 같은 기준에 따라 웹 요청을 차단하거나 허용 할 수 있다. * 악성일 가능성이 있는 스크립트. XSS라고 알려진 스크립트를 차단한다. * 요청이 시작되는 IP 주소 혹은 IP 주소 범위 * 요청이 시작되는 국가 또는 지리적 위치 * 쿼리 문자열과 같은 요청에서 지정된 부분의 길이 * 악성일 가능성이 있는 SQL 코드. SQL injection 공격이라고 알려진 것들. * 요청에 나타나는 문자열 웹 ACL는 다양한 규칙에 의해서 작성 할 수 있다. 비율 기반 규칙의 경우 각 발신 IP 주소에 대한 요청 비율을 추적하고 한도를 초과하는 비율의 IPs를 기반으로 규칙을 트리거 할 수 있다. 예를 들어 5분 시간 범위로 특정 IP에서 일정 비율 이상으로 요청이 들어오면 IP를 블럭하라와 같은 규칙을 생성 할 수 있다. 주어진 시나리오는<span> </span>**실제 요청에 영향을 주지 않을 것**을 요구 하고 있다. 이 요구사항을 만족하는 웹 ACL 규칙으 만드는 데는 일반 규칙과 속도 기반 규칙의 두가지 유형이 있다. 이 중 속도 기반 규칙을 사용해야 한다. 이 규칙이 트리거 되면 AWS WAF는 요청 속도가 제한 아래로 떨어질 때까지 IP 주소의 추가 요청 작업을 제한한다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [비율 기반 규칙](https://docs.aws.amazon.com/ko_kr/waf/latest/developerguide/waf-rule-statement-type-rate-based.html) * [AWS WAF FAQ](https://aws.amazon.com/ko/waf/faq/) 답 : 3 ### Question #43 소프트웨어 개발 회사는 서버를 설정하거나 관리하지 않고도 애플리케이션을 실행하기 위해서 AWS Lambda를 기반으로 하는 서버리스 컴퓨팅 환경을 구축했다. 여기에는 인기있는 DBaaS(Database as a Service) 플랫포인 MongoDB Atlas에 연결하는 Lambda 함수가 있으며, 외부 API를 이용해서 애플리케이션에서 사용 할 특저 ㅇ데이터를 가져온다. 개발자 중 한명은 MongoDB 데이터베이스 호스트 이름, 사용자 이름 및 암호등의 환경변수와 DEV, SIT, UAT 및 PROD 환경을 위해 Lambda 함수에서 사용할 API 자격증명을 생성하도록 지시 받았다. Lambda 함수가 민감한 데이터베이스 및 API 자격증명을 저장하고 있다는 점을 고려 할 때, 팀의 다른 개발자나 다른 사람들이 이러한 자격증명을 일반 텍스트로 보지 못하도록 보호해야 한다. 최상의 옵션을 선택하라. 1. 새로운 KMS key 를 만들고 이를 이용하는 암호화 helper를 사용하여 민감한 정보를 저장하고 암호화 한다. 2. 기본적으로 AWS Lambda는 AWS Key Management service를 이용해서 환경변수를 암호화하기 때문에 신경쓸 필요가 없다. 3. AWS Lambda는 환경변수에 대한 암호화를 제공하지 않는다. 대신 EC2 인스턴스에 코드를 배포한다. 4. AWS CloudHSM을 활용하는 SSL 암호화 기능을 활용화해서 민감정보를 암호화하고 저장한다. #### 설명 환경 변수를 사용하면 코드를 업데이트하지 않고도 함수의 동작을 조정할 수 있다. Lambda 런타임은 코드에서 환경변수를 사용 할 수 있게 하고, 함수 호출 및 요청에 대한 정보가 포함된 추가 환경변수를 설정 할 수 있다. Lambda는 계정에서 생성한 키 - AWS 관리형 고객 마스터 키(CMK) - 로 환경변수를 암호화한다. 이 키의 사용은 무료다. 키를 제공하면 키에 대한 액세스 권한이 있는 계정의 사용자만 함수에서 환경변수를 보거나 관리 할 수 있다. 또한 암호화에 사용하는 키를 관리하고 교체 시기를 제어하는 내부 또는 외부 구성요소를 가질 수 있다. Lambda는 기본적으로 환경변수를 암호화하지만 Lambda 콘솔에 액세스 할 수 있는 사용자에게 여전히 민감한 정보가 표시된다. 이는 Lambda가 기본 KMS 키를 사용하여 다른 사용자가 액세스 할 수 있는 변수를 암호화하기 때문이다. 이 시나리오에서는 암호화 도우미를(Enable helpers for encryption in transit) 사용하여 환경변수를 보호하는 것이 좋다. SSL은 전송 구간에서의 암호화 툴이다. 답 : 1 ### Question #44 솔류션 아키텍트는 관계형 데이터베이스를 설정하고 다중 지역 장애를 완화하기 위한 재해 복구 계획을 마련해야 한다. 이 솔류션에서는 1초의 RPO(복구지점 목표)와 1분 미만의 RTO(복구 시간 목표)가 필요하다. 다음 AWS 서비스 중 이 요구사항을 충족하는 것은 무엇인가. 1. Amazon Aurora Global Database 2. Amazon RDS for PostgreSQL with cross-region read replicas 3. AWS Global Accelerator 4. Amazon DynamoDB global tables #### 설명 RTO(복구 시간 목표)는 재해가 발생 한 후 원하는 작업 성능에 도달하기 위해서 걸리는 시간에 대한 목표를 말한다. 예를 들어 DR 기능이 존재하지 않을 경우 1시간 이상 중단이 발생 할 경우, DR을 적용하여 30분 이내에 모든 프로덕션 시스템이 이전 성능의 80%로 실행되도록 RTO를 지정 할 수 있다. 완전한 내 결함성 시스템의 경우에는 재해 발생 중 혹은 재해 발생 후 어떠한 개입도 엇이 시스템이 복구되기 때문에 RTO가 적용되지 않는다. RPO(복구 지점 목표). 개념적으로 RPO는 재해 발생 이전의 알려진 시간대로 롤백 또는 동기화 되는 목표 상태를 의미한다. RPO 목표와 재해 기간 중 발생하는 트랜잭션은 일반적으로 복구 할 수 없다. DR 계획자는 가능하면 RTO와 RPO가 서로 비슷한 수준이 유지될 수 있도록 해야 한다. 예를 들어 RTO가 10분이라면 RPO도 10분 이전이 되어야 할 것이다. 만약 RPO가 20분 이라면 10분 동안의 데이터 트랜잭션을 잃어 버리게 될 것이다. 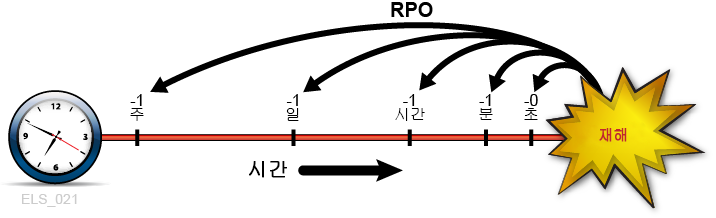 Amazon Aurora 글로벌 데이터베이스는 전 세계적으로 분산된 애플리케이션을 위해 설계되었으며, 단일 Amazon Aurora 데이터베이스를 여러 AWS 리전으로 확장해 준다. 데이터베이스 성능에 영향을 주지 않으며 데이터를 복제하고, 각 리전에서 낮은 지연 시간으로 빠른 로컬 읽기를 지원하며, 리전 규모의 가동 중단 발생시 재해 복구를 제공한다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [재해 복구 소개 - Oracle](https://docs.oracle.com/cd/E65196_01/ELSDR/drintro.htm) 답 : 1 ### Question #45 전 세계에 지사를 두고 있는 글로벌 IT 회사가 있다. 이 회사는 여러 AWS 계정을 보유하고 있다. 효율성을 높이고 비용을 절감하기 위해 CIO는 AWS 리소스를 중앙에서 관리하는 솔류션을 설정하려 한다. 이를 통해 중앙에서 AWS 리소스를 조달하고 다양한 계정에서 AWS Transit Gateway, AWS License Manager, Amazon Route 53 Resolver 규칙과 같은 리소스를 공유 할 수 있어야 한다. 솔류션 아키텍트로서 이 시나리오를 구현하기 위한 옵션 조합을 선택하라(2개) #### 설명 AWS Resource Access Manager(RAM)은 AWS 계정간의 리소스 공유를 지원한다. AWS RAM을 사용해서 AWS 조직 내의 리소스를 쉽게 공유할 수 있다. 관리자는 리소스 공유를 생성하고 이름을 지정한 다음 여기에 하나 이상의 리소스를 추가하고 다른 AWS 계정에 대한 액세스를 부여하면 된다. 조직의 마스터 계정은<span> </span>**Enable sharing within your AWS Organization**을 활성화 해야 한다. 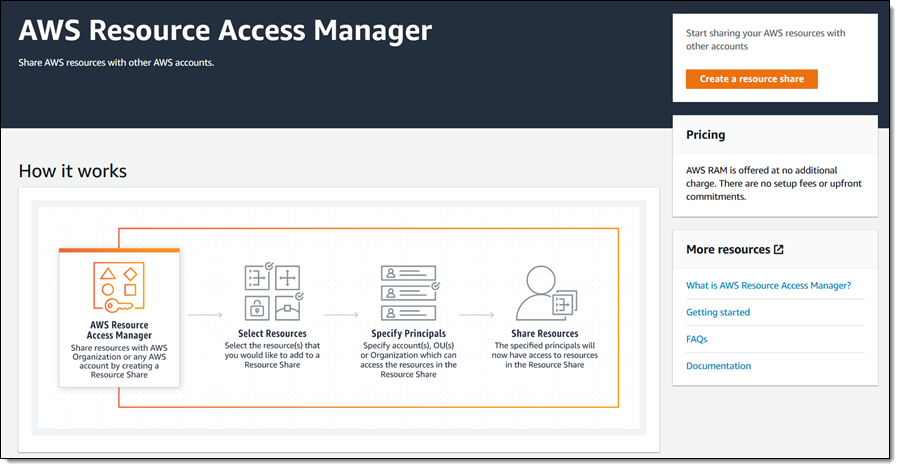 AWS Organizations는 확장된 AWS 리소스를 중앙 집중적으로 관리하고 규제하는데 사용한다. AWS Organization을 통해 프로그래밍 방식으로 새 AWS 계정을 생성하고 리소스를 할당하며, 계정을 그룹화하고 워크플로우를 생성 할 수 있다. 따라서 이 시나리오의 올바른 옵션 조합은 다음과 같다. * AWS Organization을 사용하여 회사의 모든 계정을 통합한다. * AWS RAM 서비스를 사용하여 AWS 계정간에 리소스를 쉽게 공유한다. IAM을 사용해서 다른 AWS 계정에 리소스에 대한 액세스를 위임 할 수 있다. 하지만 교차 계정 접근을 위한 서비스를 제공하지 않는다. AWS Control Tower는 계정을 랜딩하는 서비스다. AWS Control Tower를 이용해서 보안, 운영 및 규정준수를 만족하는 일관된 환경을 구성 할 수 있다. Control Tower는 리소스 공유와 관련된 기능을 제공하지 않으므로 올바른 옵션이 아니다. AWS의 공유 가능한 리소스는 아래와 같다. 이들 리소스는 RAM을 사용해서 공유 할 수 있다. RAM은 리소스를 사용 할 수 있도록 하는 것이지, 관리를 허용하는 것은 아니다. * AWS App Mesh * Amazon Aurora * AWS Certificate Manager * AWS CodeBuild * Amazon EC2 * EC2 이미지 빌더 * AWS Glue * AWS 라이선스 관리자 * AWS 네트워크 방화벽 * AWS OutPost * AWS Resource Groups * Amazon Route 53 * Amazon VPC ### Question #46 회사는 클라우드에 저장된 모든 데이터를 암호화해야 한다. 이를 다른 AWS 서비스와 쉽게 통합하려면 생성된 키의 암호화를 완벽하게 제어하고 AWS KMS에서 키 구성 요소를 즉시 제거 할 수 있어야 한다. 또한 솔류션은 CloudTrail로 사용을 감시해야 한다. 다음 중 이 요구 사항을 충족하는 옵션은 무엇인가. 1. AWS KMS(Key management Service)를 사용하여 AWS 관리형 CMK를 생성하고 키 구성요소를 CloudHSM에 저장한다. 2. AWS KSM를 사용해서 AWS owned CMK를 생성하고 키 구성요소를 CloudHSM에 저장한다. 3. AWS KMS를 사용해서 custom key store에 CMK를 생성하고 키 구성요소를 CloudHSM에 저장한다. 4. AWS KSM를 사용해서 custom key store에 CMK를 생성하고 키 구성요소를 S3에 저장한다. #### 설명 AWS KMS 는 AWS CloudHSM 에서 제공하는 사용자 지정 키 스토어(custom key store)를 제공한다. 사용자 지정 키 스토어에서 AWS KMS 고객 마스터키(CMK)를 생성하면 AWS KMS는 사용자가 소유하고 관리하는 AWS CloudHSM 클러스터의 CMK에 대해서 추출 할 수 없는 키 구성요소를 생성하고 저장한다. CMK가 사용자 지정 키 스토어에서 사용되면 암호화 작업이 클러스터의 HSM에서 수행된다.  AWS KMS는 다른 AWS 서비스와 통합되어 서비스에 저장하는 데이터를 암호화하고 이를 복호화하는 키에 대한 액세스를 제어 할 수 있다. AWS KMS에서 키 구성 요소를 즉시 제거하려면 사용자 지정 키 스토어를 사용하면 된다. 각 사용자 지징 키 스토어는 AWS 계정의 AWS CloudHSM 클러스터와 연결된다. 따라서 사용자 지정 키 스토어에 서 AWS KMS CMK를 생성하면 AWS KMS는 사용자가 소유하고 관리하는 AWS CloudHSM 클러스터의 CMK에 대해 추출 할 수 없는 키 구성요소를 생성하고 저장할 수 있다. 답 : 3 ### Question #47 인기있는 소셜 미디어 웹 서비스는 CloudFront 를 이용해서 전 세계 수백만 명의 사용자에게 정적 콘텐츠를 제공한다. 최근 사용자가 웹 사이트에 로그인하는데 많은 시간이 걸린다는 불만이 제기되고 있다. 사용자에게 HTTP 504 오류가 발생하는 경우도 있다. 관리자는 시스템을 최적화하여 사용자의 로그인 시간을 줄이도록 지시했다. 솔류션 아키텍트는 응용 프로그램의 성능을 향상시킬 수 있는 비용 효율적인 솔류션을 찾아야 한다.(2개 선택) 1. 지리적으로 분산된 여러 AWS 리전에 VPC를 분산 전개하고, VPC들을 연결하여 모든 리소스를 연결한다. 요청을 빠르게 처리하기 위해서 AWS Serverless Application Model을 이용해서 lambda 함수를 설정한다. 2. Lambda@Edge를 사용하여, CloudFront 웹 배포가 사용자에게 제공하는 콘텐츠를 지정하면 Lambda 함수가 사용자와 가장 가까운 AWS 위치에서 인증 프로세스를 실행 할 수 있다. 3. 객체에 Cache-Contrl max-age 지시문을 추가하도록 오리진을 구성하고 max-age에 대해서 가장 긴 값을 지정하여 CloudFront 배포의 캐시 적중률을 높인다. 4. 전 세계 사용자를 수용 할 수 있도록 여러 AWS 리전에 애플리케이션을 배포한다. 지연 라우팅 정책을 사용하여 Route 53 레코드를 설정하여 사용자에게 최소의 지연시간을 제공하는 리전으로 라우팅한다. 5. Origin이 두 개인 Origin 그룹을 생성하여 Orign 장애조치를 설정한다. 하나는 기본 Orign 으로 지정하고 다른 하나는 기본 오리진이 특정 HTTP 상태 코드 실패 응답을 반환 할 때 CloudFront 가 자동으로 전환하는 두번째 오리진으로 지정한다. #### 설명 CloudFront에서 HTTP 504는 "게이트웨이 제한 시간" 오류다. CloudFront 는 오리진 연결을 30초 동안 열린 상태로 유지 할 수 있다. 애플리케이션이 처리하고 응답을 반환하는데 30초 이상이 걸리면 CloudFront는 504 에러를 반환한다. Lambda@Edge를 사용하면 Lambda 함수가 최종 사용자와 가까운 CloudFront 위치에서 함수를 실행 할 수 있다. 이 함수는 서버를 프로비저닝하거나 관리하지 않고 CloudFront 이벤트에 대한 응답으로 실행된다. CloudFront는 장애조치를 위해서 두 개의 Origin을 가질 수 있다. CloudFront는 기본 Origin이 실패하면 자동으로 다음 Origin으로 요청을 하는데, 이를 통해서 HTTP 오류를 완화 할 수 있다. 솔류션 아키텍트는 오리진 응답 시간을 짧게 하여, 로그인 시간을 줄일 수 있다. 지리적으로 분산된 여러 AWS 리전에 VPC를 생성하고 모든 리소스를 연결하는 방법도 사용 할 수 있지만, 높은 설정 및 유지 관리 비용이 들어간다. Cache-Control max-age지시문은 정적 컨텐츠에 대한 히트율을 높이기 위해서 사용한다. 하지만 이 시나리오는 정적 컨텐츠가 아닌 느린 인증 프로세스이므로 적당한 옵션이 아니다. 답 : 2, 5 ### [47.](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#toc)<span> </span>Question #48 온 프레미스 데이터센터에서 호스팅되는 다중 계층 애플리케이션을 AWS로 마이그레이션 할 계획이다. 해당 애플리케이션에는 업계 표준 메시징 API와 프로토콜을 사용하는 메시지 브로커 서비스가 있다. 솔류션 아키텍트는 메시징을 사용하는 애플리케이션의 수정 없이 마이그레이션 해야 한다. 가장 적합한 서비스는 무엇인가 ? 1. Amazon SQS 2. Amazon SNS 3. Amazon MQ 4. Amazon SWF #### 설명 Amazon MQ, Amazon SQS, Amazon SNS는 스타트업에서 엔터프라이즈까지 사용 할 수 있는 메시징 서비스다. Amazon MQ는 업계 표준 MQ인 Apache ActiveMQ와 RabbitMQ용 관리형 메시지 브로커이다. 따라서 솔류션 아키텍트는 Amazon MQ를 제안하면 된다. 클라우드에서 새로 애플리케이션을 구축하는 경우에는 Amazon SQS와 Amazon SNS를 고려하는 것이 좋다. 이들은 서버리스 서비스이기 때문에 운영/관리의 수고 없이 즉시 메시지 서비스를 사용 할 수 있다. Amazon SQS는 완전 관리형 메시지 대기열 서비스이지만 업계 표준 API와 프로토콜 목록을 지원하지 않기 때문에 올바르지 않다. SQS를 사용하려면 애플리케이션을 수정해야 한다. SNS는 메시지 브로커가 아닌 pub/sub 방식의 push 메시징 서비스에 적합하기 때문에 올바르지 않다. Amazon SWF는 상태 추적 및 작업 코디네이터 서비스이기 때문에 올바르지 않다. 답 : 3 ### Question #49 암호 화폐 거래 플랫폼을 서비스하는 회사가 있다. 이 회사는 AWS Lambda 및 API Gateway에 내장된 API를 사용한다. 비트코인, 이더리움 및 기타 암호화폐에 대한 최근 소식으로 인해서 거래 플랫폼은 사이트 방문자와 신규 사용자가 크게 증가 할 것으로 예상된다. 트래픽 급증으로 부터 플랫폼의 백앤드 시스템을 어떻게 보호할 수 있는가 ? 1. Throttling limits를 활성화하고 API Gateway 결과를 캐시한다. 2. Lambda를 VPC 안으로 옮긴다. 3. AWS Lambda와 API Gateway를 더 나은 확장성을 제공하는 ELB와 EC2 instance, Auto Scaling 기반으로 아키텍처링 한다. 4. API gateway앞에 CloudFront를 둬서 캐시 한다. #### 설명 Amazon API gateway는 전역, 서비스 호출 등의 여러 단계에서 세부 조정이 가능하다. 여기에는 속도와 버스트에 대한 제한 설정이 포함된다. 예를 들어 API 소유자는 특정 REST API 에 대해서 초당 1,000개의 요청 속도 제한을 설정 할 수 있으며, 몇 초 동안 초당 2,000개의 요청 버스트를 처리 하도록 Amazon API Gateway를 구성 할 수도 있다. Amazon API Gateway는 초당 요청 수를 추적하며, 제한을 초과하는 요청에 대해서 429 HTTP(Too May Requests) 응답을 반환한다. Amazon API gateway에서 생성한 클라이언트 SDK는 이 응답을 받으면 자동으로 재 호출을 시도한다. 따라서 API Gateway에서 제한 설정과 캐싱을 활성화 하는 것이 정답이다. <br> Amazon API Gateway에서 API 캐싱을 활성화하여 엔드포인트의 응답을 캐싱할 수 있다. 캐싱을 사용하면 엔드포인트에 대한 호출 수를 줄이고 API에 대한 요청 지연 시간을 개선 할 수 있다. 캐시 설정을 사용하면 캐시 키가 작성되는 방식과 각 메서드에 대해 저장된 테이터의 TTL(Time-to-Live)를 제어 할 수 있다. 또한 Amazon API Gateway의 각 단계의 캐시를 무효화하기 위한 관리 API도 제공한다. 캐싱할 수 있는 응답의 최대 크기는 1048576 바이트이다. CloudFront는 컨텐츠의 전송속도를 높여서 사용자에게 더 나은 지연시간 경험을 제공하기 위해서 사용한다. 따라서 API Gateway 앞에서 CloudFront를 사용하여 캐시 역할을 하는 것은 올바르지 않다. 백앤드 서버에는 별 도움이 되지 않는다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [응답성 향상을 위한 API 캐싱 활성화](https://docs.aws.amazon.com/ko_kr/apigateway/latest/developerguide/api-gateway-caching.html) 답 : 1 ### Question #50 한 회사에서 Amazon EC2 인스턴스의 Auto Scaling 그룹에 웹 애플리케이션을 호스팅 할 계획이다. 이 애플리케이션은 사용자가 여러 유형의 파일을 업로드하고 저장하기 위해서 전 세계에서 서비스된다. 사용자 추세에 따라 2년 이상 된 파일은 다른 스토리지 클래스에 저장해야 한다. 회사의 솔류션 아키텍트는 기존 파일을 저장하면서도 내구성과 고 가용성을 제공하는 비용 효율적이고 확장 가능한 솔류션을 만들어야 한다. 다음 중 이 요구사항을 충족하는 솔류션을 선택하라. (2개) 1. Amazon EFS를 사용하고 2년 후 객체를 Amazon EFS-IA로 이동하는 수명주기 정책을 설정한다. 2. Amazon S3를 사용하고 2년 후 Amazon S3 Glacier로 객체를 이동하는 수명주기 정책을 설정한다. 3. Amazon S3를 사용하고 2년 후 Amazon S3 Standard-IA로 객체를 이동하는 수명주기 정책을 설정한다. 4. Amazon EBS 볼륨에 파일을 저정한다. Amazon DLM(Data Lifecycle Manager)를 이용해서 2년 후 볼륨 스냅샷을 생성한다. 5. 여러 Amazon EBS 볼륨을 함께 strip 하는 RAID 0 스토리지 구성을 사용하여 파일을 저장한다. 2년 후 볼륨 스냅샷을 생성하도록 Amazon DLM을 구성한다. #### 설명 AWS Amazon S3는 최고의 확장성, 데이터 가용성, 보안 및 성능을제공하는 객체 스토리지 서비스다. 즉 규모와 업종에 상관없이 이 서비스를 이용해서 데이터 레이크, 웹 사이트, 모바일 애플리케이션, 백업 및 복원, 아카이브, IoT 디바이스, 빅 데이터 분석과 같은 다양한 사용 사례에서 원하는 만큼의 데이터를 저장하고 보호할 수 있다. 사용자는 AWS Amazon S3에 하나 이상의 버킷을 만들고 여기에 파일을 업로드 할 수 있다. 파일을 객체로 업로드 할 때 객체 및 모든 메타 데이터에 대한 권한을 설정 할 수 있다. 버킷은 객체의 컨테이너 역할을 한다. Amazon S3는 여러 스토리지 클래스를 가지고 있으며, 객체의 클래스간 이동이 가능하다. 예를 들어 S3 수명주기 규칙을 사용하여 파일을 S3 Standard IA 또는 Glacier로 전환 할 수 있다. S3 Glacier의 신속 검색을 사용하면 1\~5분 이내에 파일에 빠르게 액세스 할 수 있다. * S3 Standard : 짧은 지연 시간 및 높은 처리량, 연간 99.99%의 가용성 제공 * S3 Intelligent-Tiering : 알 수 없거나 변화하는 액세스. 액세스 패턴이 변화할 때 4개의 액세스 티어 간에 객체를 이동하여 자동 비용 절감 효과를 제공한다. * S3 Standard-IA : 자주 액세스하지 않지만 필요할 때 빠르게 액세스해야 하는 데이터의 저장. * S3 One Zone-IA : 자주 액세스하지 않지만 빠르게 액세스 해야 하는 데이터의 저장. 단일 AZ에 데이터를 저장하기 때문에 20% 정도의 비용 절감 효과가 있다. * S3 Glacier : 장기 아카이브에 이상적이다. 몇 분에서 몇 시간까지의 검색 시간을 가진다. * S3 Glacier Deep Archive : 7-10년 동안 유지되는 데이터의 장기 보관, 12 시간 이내의 검색 시간 EFS도 스토리지 클래스를 가지고 있으며, 수명 주기 설정이 가능하다. 하지만 최대 90일 까지만 사용 할 수 있기 때문에 올바른 선택이 아니다. EFS는 S3 만큼 비용 효율적이지 않으며, S3 만큼 확장할 수 없다. [RAID](https://www.joinc.co.kr/w/man/12/raid)는 더 높은 성능 또는 데이터 내구성을 달성하기 위해 여러 스토리지 장치를 결합하는 데이터 스토리지 가상화 기술 일 뿐이다. 답 : 2, 3 ### Question #51 애플리케이션은 서로 다른 가용 영역의 프라이빗 서브넷에 배치된 여러 EC2 인스턴스에서 실행된다. 애플리케이션은 인터넷에서 인스턴스로 소프트웨어 패치를 다운로드하기 위해서 단일 NAT 게이트웨이를 사용하고 있다. NAT 게이트웨이에 장애가 발생하거나 가용성 영역이 다운되는 경우 단일 장애 지점이 발생 할 수 있다. 솔류션 아키텍트는 가용성과 비용 효율성을 높이기 위한 아키텍처를 제안해야 한다. 1. 각 가용영역에 NAT 게이트웨이를 생성한다. 인스턴스가 동일한 가용 영역의 NAT 게이트웨이를 사용하도록 각 퍼블릭 서브넷에 라우팅 테이블을 설정한다. 2. 각 가용영역에 3개의 NAT 게이트웨이를 생성한다. 인스턴스가 동일한 가용 영역의 NAT 게이트웨이를 사용하도록 각 프라이빗 서브넷에 라우팅을 설정한다. 3. 각 가용영역에 NAT 게이트웨이를 생성한다. 인스턴스가 동일한 가용 영역의 NAT 게이트웨이를 사용하도록 각 프라이빗 서브넷에 라우팅을 설정한다. 4. 각 가용영역에 2개의 NAT 게이트웨이를 생성한다. 인스턴스가 동일한 가용 영역의 NAT 게이트웨이를 사용하도록 퍼블릭 서브넷의 라우팅을 설정한다. #### 설명 NAT 게이트웨이는 프라이빗 서브넷의 리소스들이 인터넷에 액세스하기 위한 고 가용성의 NAT(Network Address Translation) 서비스다. NAT 게이트웨이는 특정 가용 영역에 생성되며, 해당 영역에 중복으로 구현된다. 프라이빗 서브넷의 인스턴스가 인터넷 혹은 다른 AWS 서비스에 연결하려면 퍼블릭 서브넷에 NAT 게이트웨이를 생성하면 된다. 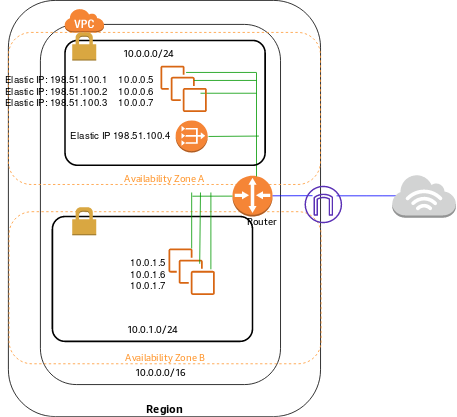 여러 가용 영역에 배치된 리소스들이 하나의 NAT 게이트웨이를 공유 할 경우, NAT 게이트웨이가 배치된 가용역역이 다운되면 다른 가용영역의 리소스가 인터넷에 접근 할 수 없게 된다. 각 가용 영역에 NAT 게이트웨이를 생성하고 리소스가 동일한 가용영역의 NAT 게이트웨이를 사용하도록 라우팅을 구성하면 가용성을 높일 수 있다. NAT 게이트웨이를 만들려면 NAT 게이트웨이가 속할 퍼블릭 서브넷을 지정하고 인터넷에 노출될 EIP를 지정한다. NAT 게이트웨이와 연결한 EIP는 변경 할 수 없다. 그리고 하나 이상의 프라이빗 서브넷과 연결된 라우팅 테이블을 업데이트하여 인터넷 바운드 트래픽이 NAT 게이트웨이를 가리키도록 해야 한다. 각 NAT 게이트웨이는 특정 가용영역에서 중복성을 통해서 구성되므로 하나의 가용영역에 2개 이상의 NAT 게이트웨이를 구성할 필요는 없다. * [참고](https://www.joinc.co.kr/w/man/12/awsCertification/SolutionArchitect/exam#) * [VPC NAT Gateway](https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/vpc-nat-gateway.html) 답 : 3 ### Question #52 금융 애플리케이션은 EC2 인스턴스의 오토 스케일링 그룹, 애플리케이션 로드 밸런서 , Multi-AZ 설정된 MySQL RDS로 구성된다. 고객의 기밀 데이터를 보호하려면 인증 토큰을 통해 EC2 인스턴스에 특정한 자격 증명을 사용해서만 RDS 데이터베이스에 액세스 할 수 있게 해야 한다. 위의 요구사항을 만족시키기 위해서 무엇을 해야 하는가. 1. IAM과 STS를 조합하여 임시토큰을 만들어서 접근을 제한한다. 2. RDS 인스턴스에 접근 할 수 있는 정책을 가진 IAM 롤을 만들어서 EC2 인스턴스에 할당한다. 3. RDS 연결에 SSL을 설정한다. 4. IAM DB 인증을 활성화 한다. #### 설명 AWS IAM 데이터베이스 인증을 사용하여 DB 인스턴스에 인증 할 수 있다. IAM 데이터베이스 인증은 MySQL, PostgreSQL 에서 작동한다. 이 인증 방법을 사용하면 암호가 아닌 인증토큰을 이용해서 연결 할 수 있다. * IAM 데이터베이스 인증 토큰은 AWS 액세스 키를 사용하여 생성된다. 데이터베이스 사용자 자격 증명을 저장 할 필요가 없다. * 인증 토큰의 수명은 15분 이므로 암호를 재설정하도록 강제할 필요가 없다. * IAM 데이터베이스 인증은 보안 소켓 계층(SSL) 연결이 필요하다. 즉 전송계층의 데이터가 암호화 된다. * 애플리케이션이 EC2에서 실행되는 경우, EC2 인스턴스 프로파일 자격 증명을 사용하여 데이터베이스에 액세스 할 수 있다. 인스턴스에 데이터베이스 암호를 저장할 필요가 없다. STS는 인증을 위한 임시 토큰을 만드는데 사용하지만 RDS와 호환되는 사례는 아니다. 답 : 4 ### Question #53 솔류션 아키텍트는 tutorialsdojo라는 Amazon S3 버킷에서 웹 사이트를 호스팅하고 있다. 사용자는 http://tutorialsdojo.s3-website-us-east-1.amazonaws.com URL을 사용하여 웹 사이트를 로드한다. 아키텍트는 인증된 HTTP GET 요청을 수행하기 위해서 웹 페이지에 JavaScript를 추가해야 하는 요구사항을 전달 받았다. Amazon S3 API 엔드포인트를 사용하여 동일한 버킷에 대한 테스트에서 웹 브라우저가 JavaScript의 요청을 허용하지 못하도록 차단하는 것을 확인했다. 아래 옵션 중 이 시나리오를 구현하기에 가장 적합한 솔류션은 무엇인가. 1. Bucket에 대해서 CORS(Cross-origion resource sharing) 설정을 활성화 한다. 2. Cross account access를 활성화 한다. 3. CRR(Cross-Region Replication)을 활성화 한다. 4. Cross-Zone Load Balancing를 활성화 한다. #### 설명 이 문제를 풀려면 CORS(교차 출처 리소스 공유)를 이해해야 한다. 교차 출처 리소스는 추가적인 HTTP 헤더를 사용하여, 특정 출처에서 실행 중인 웹 애플리케이션이 다른 출처의 자원에 접근 할 수 있는 권한을 부여하도록 브라우저에 알려주는 장치다. 예를들어 domain-a.com 에서 domain-b.com에 호스팅된 이미지를 이용하려고 할 때, 대부분의 브라우저에서는 CORS 정책에 의해서 이미지가 로드되지 않는다. CORS 정책이 적용되는 요청은 아래와 같다. * XMLHttpRequest와 FetchAPI * 웹 폰트(CSS내 @font-face에서 교차 도메인 폰트 사용시) * WebGL 텍스처 * drawImage()를 사용해서 캔버스에 그린 이미지/비디오 프레임 * 이미지로부터 추출하는 CSS Shapes Amazon S3는 버킷에 대해서 CORS 구성을 생성 할 수 있다. CORS 구성은 버킷에 대한 액세스를 허용할 오리진, 각 오리진에 대해서 지원되는 작업(HTTP Method)를 식별하는 규칙 및 기타 작업별 정보를 포하는 문서다. 구성당 최대 100개의 규칙을 추가 할 수 있다. S3 콘솔에서 CORS를 구성하는 경우 JSON을 사용하여 CORS 구성을 생성해야 한다. 아래에 CORS 작동을 묘사했다. 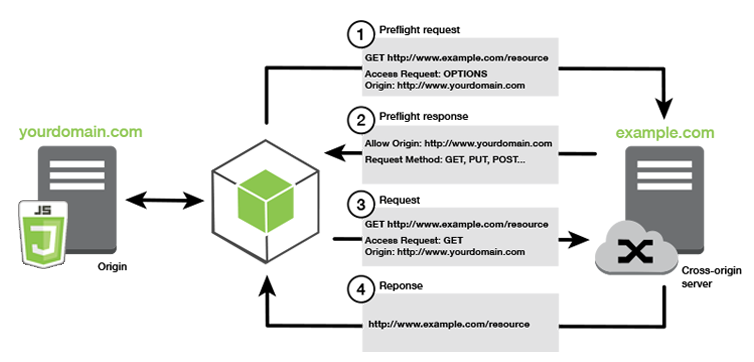 1. Preflight 요청을 전송한다. Origin이 http://www.yourdomain.com 인 요청을 허용하는지를 확인하는 절차다. 2. Preflight 요청에 대한 응답을 전송한다. 해당 Origin의 요청을 허용하는지, 어떤 작업(GET, PUT, POST ...)을 허용하는지를 전송한다. 3. Origin 설정을 하고 example.com 에 요청을 전송한다. 4. example.com이 응답한다. 교차계정액세스는 S3가 아닌 IAM 기능이다. 교차영역로드 밸런싱은 S3가 아닌 ELB에서 사용하는 기능이다. CRR은 AWS 리전의 버킷간에 객체를 비동기 복사하는 기능이다. 답 : 1 ### Question #54 귀하가 근무하는 ELB와 오토스케일링 설정된 EC2 인스턴스로 구성된 고 가용성 아키텍처를 가지고 있다. CloudWatch에서 얻을 수 없는 특정 지표를 기반으로 EC2 인스턴스를 모니터링 하려고 한다. 다음 중 수동으로 설정해야 하는 CloudWatch의 사용자 정의 지표는 무엇인가. ? 1. EC2 인스턴스의 메모리 사용율 2. EC2 인스턴스의 CPU 사용율 3. EC2 인스턴스의 네트워크 출력 패킷 4. EC2 인스턴스의 디스크 읽기 #### 설명 CloudWatch는 EC2를 모니터링 하기 위한 다양한 지표를 제공한다. 여기에는 CPU 사용율, 네트워크 사용율, 디스크 읽기/쓰기 측정 메트릭들이 포함된다. 하지만 메모리 사용율, 디스크 사용율 등은 지표로 제공하지 않는다. 왜냐하면 CloudWatch는 VM 레벨에서의 모니터링 시스템인데, 메모리 사용율, 디스크 사용율은 운영체제에서 관리하는 것으로 CloudWatch가 접근 할 수 없기 때문이다. 이런 지표는 CloudWatch 모니터링 스크립트를 이용해서 운영체제 내에서 실행해줘야 한다. AWS에서 제공하는 모니터링 스크립트는 아래의 추가적인 목록을 제공한다. * 디스크 사용율 * 메모리 사용율 * 디스크 공간 활용 * 페이지 파일 사용율 * 로그 수집 답 : 1 ### Question #55 한 제약회사는 온 프레미스 네트워크와 AWS 클라우드 모두에서 호스팅되는 리소스를 보유하고 있다. 모든 소프트웨어 아키텍트가 Activie Directory에 저장된 온-프레미스 자격 증명을 사용하여 두 환경 리소스에 액세스 하기를 원한다. 이 시나리오를 충족하는 솔류션은 무엇인가 ? 1. 웹 identity federation을 이용해서 SAML 2.0 기반 페더레이션을 설정한다. 2. Microsoft Active Directory Federation Service를 이용해서 SAML 2.0 기반 페더레이션을 설정한다. 3. IAM users를 이용한다. 4. Amazon VPC를 이용한다. #### 설명 이 회사는 SAML(Security Assertion Markup Language)를 구현하는 Microsoft Active Directory를 사용하고 있으므로 AWS 클라우드에서 제공하는 API에 액세스하기 위해 SAML 페어레이션을 설정 할 수 있다. 이러한 방식으로 온 프레미스 네트워크의 로그인 자격증명을 사용하여 AWS에 쉽게 연결 할 수 있다. <br> AWS는 많은 자격증명공급자(ldp)가 사용하는 개방형 표준인 SAML 2.0을 사용한 자격 증명 연동을 지원한다. 이 기능은 페더레이션된 SSO를 활성화하므로 사용자는 조직의 모든 사람에 대한 IAM을 생성하지 않고도 AWS Management Console에 로그인하거나 AWS API를 호출 할 수 있다. SAML을 사용하면 사용자 지정 자격 증명 프록시 코드를 작성하는 대신 ldp 서비스를 사용 할 수 있기 때문에 AWS의 연동 구성 프로세스를 단순화 할 수 있다. 이 시나리오를 구축하기 위해서는 조직의 ldp와 AWS 계정이 서로를 신뢰하도록 구성해야 한다. 웹 자격 증명 연동을 사용한 SAML 2.0은 올바르지 않다. 이것은 주로 사용자가 Amazon, Facebook, Google과 같은 잘 알려진 외부 자격 증명 공급자(ldp)를 통해 로그인 할 수 있도록 사용하기 때문이다. 답 : 2 ### Question #56 이 기술 회사는 온 디맨드 EC2 인스턴스의 오토 스케일링 그룹에서 호스팅되는 CRM 애플리케이션을 보유하고 있다. 이 응용 프로그램은 오전 9시 부터 오후 5시까지 근무 시간동안 광범위하게 사용된다. CRM 사용자는 처음 업무 시작동안 응용 프로그램이 느려지며, 몇 시간 후에 정상적으로 작동한다고 불평하고 있다. 다음 중 하루를 시작 할 때 애플리케이션이 제대로 작동하는지 확인하기 위해서 수행 할 수 있는 것은 무엇인가 ? 1. CPU 사용율을 기반으로 새 인스턴스를 실행하도록 오토 스케일링 그룹에 대한 Dynamic Scaling 정책을 구성한다. 2. 하루 업무 시작전에 새 인스턴스를 시작하는 스케쥴 스케일링 정책을 가지는 오토 스케일링 그룹을 설정한다. 3. 메모리 사용율을 기반으로 새 인스턴스를 실행하도록 오토 스케일링 그룹에 대한 Dynamic Scaling 정책을 구성한다. 4. 트래픽이 인스턴스에 올바르게 분산되도록 아키텍처에 Application Load balancer를 설정한다. #### 설명 스케쥴 기반의 스케일링은 예측 가능한 부하의 변화에 대응하여 애플리케이션을 확장 할 수 있다. 예를 들어 매주 주말에 트래픽이 집중 하거나, 스포츠 이벤트에 트래픽이 집중한다면, 해당 스케쥴에 맞춰서 스케일 인/아웃 하는 오토스케일링 정책을 수립 할 수 있다. 스케쥴 기반의 스케일링은 Amazon EC2 오토 스케일링이 지정된 시간에 조정 작업을 하도록 지시한다. 조정 작업이 적용될 시간을 설정하고 확장할 인스턴스의 최소, 최대 크기를 지정한다. 문제의 시나리오는 업무시작 시간에 성능이 느려지고, 몇 시간이 지난 후 정상 성능이 나온다고 했다. 우리는 사용자들이 출근해서 대량의 EC2 인스턴스를 필요로 하고, 이 인스턴스들이 점진적으로 스케일링 되면서 원하는 성능이 나오지 않을 것을 예상 할 수 있다. 따라서 하루 일과가 시작되기 전에, 충분한 수의 인스턴스를 미리 실행하는 것으로 문제를 해결 할 수 있을 것이다. <br> CPU 사용율을 기반으로 새 인스턴스를 시작하는 방안, Meomory 기반으로 새 인스턴스를 시작하도록 오토 스케일링 정책을<span> </span>**동적으로 설정**하는 것은 올바르지 않다. 이 시나리오에서는 애플리케이션의 정확한 사용용량을 알고 있으므로 스케쥴 기반의 조정 정책을 사용하는 것이 더 좋다. CPU 나 메모리가 최대치에 도달 할 때 애플리케이션을 실행 할 경우, 이미 사용자는 성능 하락을 경험하고 있기 때문에 좋은 방법이 아니다. 답 : 2 ### Question #57 RDS 데이터베이스 인스턴스의 가용영역에서 데이터베이스에 대한 액세스 권한을 읽을 때 많은 중단지점이 발생한다. 이 이벤트가 발생하는 경우 데이터베이스에 대한 액세스 손실을 방지하려면 어떻게 해야 하는가. 1. 데이터베이스의 스냅샷을 생성한다. 2. 읽기 전용 리플리카를 생성한다. 3. 데이터베이스 인스턴스의 크기를 증가한다. 4. Multi-AZ failover를 활성화 한다. #### 설명 Amazon RDS Multi-AZ 배포는 데이터베이스 인스턴스에 향상된 가용성과 내구성을 제공하므로 프러덕션 레벨의 워크로드에 적당하다. 답은 Multi-AZ failver의 활성화다. Multi-AZ 인스턴스를 프로저닝하면, 두 개 이상의 가용영역에 대기(Standby) 상태의 데이터베이스 인스턴스가 생성된다. Active 인스턴스와 Standby 인스턴스는 동기적으로 데이터블 복제한다. 만약 Active 인스턴스가 실패한다면, Standby 인스턴스가 Active 인스턴스로 승격해서 서비스를 계속한다.  인프라에 장애가 발생하는 경우 Amazon RDS가 standby(Amazon Aurora의 경우 읽기 전용 복제본)로 자동으로 장애조치를 수행하므로 짧은 장애조치 후 즉시 데이터베이스 작업을 재개 할 수 있다. 데이터베이스의 스냅샷을 만들면 데이터를 백업 할 수 있지만, 즉각적인 가용성을 제공하지는 않는다. 데이터베이스 인스턴스 크기를 늘리는 것은 용량 업그레이드 필요성에 대응하는 것이지 장애조치에 대한 대응은 아니다. 읽기 전용 복제본은 데이터베이스에 향상된 성능을 제공하는 것을 목표로 하기 때문에 올바르지 않다. 읽기 전용 복제본을 승격 할 수 있지만 읽기 전용 복제본는 비동기식 복제를 사용하기 때문에 최신 버전의 데이터베이스를 제공하지 않을 수 있다. 답 : 4 ### Question #58 소매 웹 사이트는 간헐적이고 산발적이며 예측 할 수 없는 워크로드가 발생한다. 이 웹 사이트는 온-프레미스에서 호스팅되고 있으며, AWS로 마이그레이션 할 예정이다. 애플리케이션의 최대 부하 요구사항을 충족하기 위해 용량을 자동으로 확장하고 활동 급증이 끝나면 다시 축소하는 새로운 관계형 데이터베이스가 필요하다. 다음 중 이 시나리오에 사용 할 수 있는 비용 효율적이고 적합한 데이터베이스 설정은 무엇인가. ? 1. 클러스터에 최소/최대 용량을 설정한 Amazon Aurora Serverless DB 클러스터를 실행한다. 2. Concurrency 스케일링을 적용한 Amazon Redshift 데이터웨어 하우스를 실행한다. 3. 오토 스케일링 설정한 DyanmoDB 글로벌 테이블을 생성한다. 4. burstable performance DB 인스턴스 타입으로 Aurora Provisioned DB 클러스터를 실행한다. #### 설명 Amazon Aurora Serverless는 자동확장구성을 제공하는 서버리스 데이터베이스 서비스다. Aurora Serverless DB 클러스터는 애플리케이션의 요구 사항에 따라 컴퓨팅 용량을 자동으로 확장, 축소, 시작, 종료할 수 있다. Aurora Serverless는 드물고 간헐적이나 예측 할 수 없는 워크로드에 대해서 간단하고 비용 효율적인 옵션을 제공한다. Aurora 용 non-serverless DB 클러스터를 프로비저닝된 DB 클러스터라고 한다. Aurora Serverless DB 클러스터로 작업하는 경우 DB 인스턴스의 크기를 선택하고 Aurora 복제본을 생성하여 읽기 처리량을 조절 할 수 있다. 워크로드가 변경되면 DB 인스턴스 클래스 크기를 수정하고 Aurora 복제본 수를 변경 할 수 있다. 이 모델은 예상되는 워크로드에 따라서 수동으로 용량을 조절 할 수 있으므로 데이터베이스 워크로드를 예측 할 수 있을 때 잘 작동한다. Amazon Aurora DB 클러스터는 하나 이상의 DB 인스턴스와 이 DB 인스턴스의 데이터를 관리하는 클러스터 볼륨으로 구성된다. * 기본 DB 인스턴스 : 읽기 및 쓰기 작업을 지원하고, 클러스터 볼륨의 모든 데이터 수정을 실행한다. Aurora DB 클러스터 마다 하나의 기본 DB 인스턴스가 있다. * Aurora 복제본 : 기본 DB 인스턴스와 동일한 스토리지 볼륨에 연결되며 읽기 작업만 지원한다. 각 Aurora DB 클러스터는 최대 15개까지 Aurora 복제본을 구성 할 수 있다. 기본 DB 인스턴스가 사용 할 수 없게 되면 Aurora는 Aurora 복제본으로 자동 장애조치 한다. * Aurora 멀티/마스터 클러스터의 경우 모든 DB에 읽기/쓰기 기능이 있다. 이 경우, 기본 인스턴스와 Aurora 복제본의 차이가 사라진다.  Aurora Serverless를 사용하면 DB 인스턴스 클래스를 지정하지 않고도 데이터베이스 엔드 포인트를 생성 할 수 있다. 최소 및 최대 용량을 설정하면 된다. Aurora Serverless는 데이터베이스 엔드 포인트가 자동으로 확장되는 리소스 집합을 가지고 있으며 워크로드를 라우팅하는 프록시 집합에 연결된다. 이 프록시 집합을 이용해서 Aurora Serverless가 최소 및 최대 용량 사양에 따라 리소스를 자동으로 확장하여 연결 할 수 있다. 이러한 연결은 Aurora serverless가 자동으로 관리한다. 자원은 즉시 사용 가능한 "웜 리소스 풀"을 사용하기 때문에 확장이 빠르다. 스토리지와 컴퓨팅이 분리되어 있으므로 처리 용량을 줄이고 스토리지에 대해서만 비용을 지불 하는 등의 전략을 사용 할 수도 있다.  프로비저닝된 Aurora DB 클러스터는 간헐적이고 예측 할 수 없는 트랜잭션 워크로드에는 적합하지 않으므로 버스트 가능한 performance DB 인스턴스 클래스 유형은 올바른 답이 아니다. 답 : 1 ### Question #59 한 회사가 Amazon EC2과 Amazon RDS 를 이용해서 웹 사이트를 호스팅 하기로 결정했다. 차량이 판매되면 목록이 자동으로 제거된다. 솔류션 아키텍트는 자동화된 DB 스냅샷을 모니터링 하고 데이터를 여러 대상 그룹에 전달하는 솔류션을 구현해야 한다. 다음 중 주어진 요구사항을 충족하는 옵션은 무엇인가. 1. RDS event subscription을 생성하고 Amazon SNS로 알림을 전송한다. 그리고 다중의 Amazon SQS 큐로 이벤트를 전송하도록 SNS 토픽을 설정한다. Lambda 함수를 이용하도록 타겟 그룹을 설정한다. 2. Amazon RDS에 AWS Lambda를 실행하는 네이티브 함수 혹은 스토어 프로시저를 생성한다. 람다는 다중의 Amazon SNS 토픽에 이벤트를 전송하도록 한다. 3. RDS event subscript를 생성하고 AWS Lambda를 실행한다. 람다는 다중의 SQS 큐에 이벤트를 전송한다. 4. RDS event sbuscription을 생성하고 Amazon SQS에 알림을 전송한다. 그리고 다중의 Amazon SNS topic에 이벤트 알림을 전송하도록 SQS 큐를 설정한다. #### 설명 Amazon SNS와 Amazon Simple Queue 서비스는 긴밀하게 작동한다. SNS를 사용하면 푸시(Push) 매커니즘을 통해 여러 구독자에게 중요 메시지를 보낼 수 있으므로 변경사항을 주기적으로 사용하거나 폴링 할 필요가 없다. Amazon SQS는 폴링 모델을 통해서 메시지를 교환하는데 사용하는 분산 메시지 대기열 서비스다. Amazon SNS와 Amazon SQS를 함께 사용하면 이벤트에 대한 즉각적인 알림을 애플리케이션이 수신 할 수 있도록 설정 할 수 있다.  Amazon RDS 이벤트 알림 구독을 설정하면 특정 DB 인스턴스, DB 스냅샷, DB 보안 그룹 또는 DB 파라미터 그룹에 대해 발생한 이벤트 알림을 받을 수 있다. 구독을 생성하는 가장 간단한 방법은 RDS 콘솔을 사용하는 것이다. 이벤트 알림 구독을 만들기로 선택한 경우 Amazon Simple Notification Service 주제를 생성할 수 있다. Amazon RDS는 Amazon SNS를 사용하여 데이터베이스 이벤트 알림을 보낼 수 있다. 알림은 이메일, 문자 메시지, HTTP 엔드 포인트 호출 등이 있다. 이 시나리오에서는 Amazon SNS와 Amazon SQS를 이용하여 팬아웃 메시징을 구현 할 수 있다. SNS와 SQS를 조합하여 메시징 시스템을 구축하면, 여러 구독자에게 동일한 메시지를 푸시 할 수 있다. 예를 들어 자동화된 DB 스냅샷이 생성 될 때마다 SNS 주제에 메시지를 보낼 수 있다. 해당 주제를 구독하는 sQS 대기열은 해당 작업에 대해서 동일한 알림을 받을 수 있다. 이제 Lambda 함수로 이벤트 알람을 처리 하면 된다. RDS는 Lambda를 직접 호출 할 수 없다. Amazon Aurora만 직접 Lambda를 호출 할 수 있는데, 자동화된 스냅샷 모니터링이 아니라 데이터 변경에 주로 사용한다. 답 : 1 ### Question #60 회사는 Redshift 클러스터를 사용하는 온라인 분석 애플리케이션을 설계해야 한다. 다음 서비스 중 Redshift 인스턴스에서 발생하는 모든 API 호출을 모니터링하고 감사 및 규정 준수 목적의 보안 데이터를 제공 할 수 있는 서비스는 무엇인가. 1. AWS X-RAY 2. Amazon Redshift Spectrum 3. AWS CloudTrail 4. Amazon CloudWatch #### 설명 AWS CloudTrail은 계정의 거버넌스, 규정준수, 운영 및 위험 감사를 활성화 하도록 도와주는 서비스다. 사용자, 역할 또는 AWS가 서비스가 수행하는 작업들은 CloudTrail에 이벤트로 기록된다. 이 이벤트에는 AWS Management 콘솔, AWS Command Line Interface, AWS 및 SDK에서 수행된 작업들이 포함된다. CloudTrai은 두 가지 유형의 추적이 가능하다. * 모든 리전에 적용되는 추적 : 모든 리전에 적용되는 추적을 생성하면, CloudTrail은 각 리전에 이벤트를 기록하고 CloudTrail 이벤트 로그파일을 지정한 S#로 전송한다. 모든 리전에 적용되는 추적은 CloudTrail의 권장 사항이므로 기본 옵션으로 설정된다. * 단일 리전에 적용되는 추적 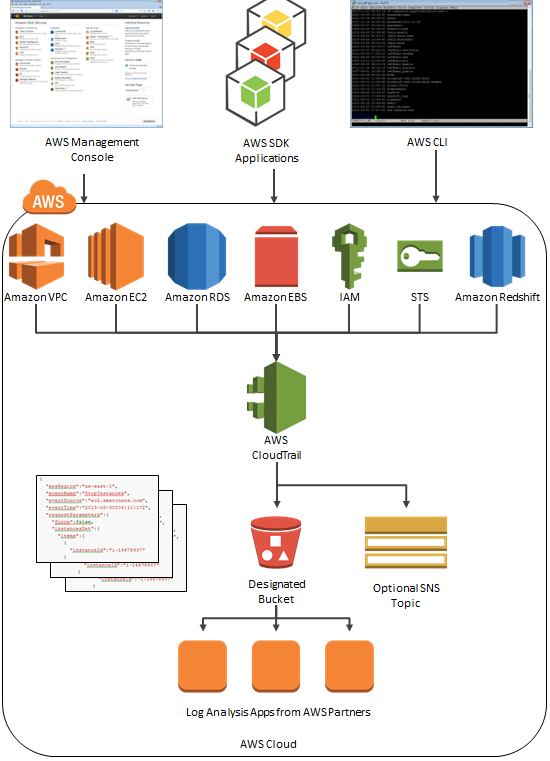 따라서 정답은 AWS CloudTrail 이다. * Amazon CloudWatch는 모니터링 서비스이기는 하지만 API 호출을 추적 할 수 없기 때문에 올바르지 않다. * Amazon Redshift Spectrum은 S3 테이블의 데이터를 쿼리하고 분석할 수 있는 Redshift 서비스이므로 올바르지 않다. * AWS X-Ray는 AWS 리소스에 대한 각 API 호출을 추적하는데 사용하므로 적합한 서비스가 아니다. 답 : 3 ### Question #61 웹 애플리케이션 제품군은 3개의 가용영역에 걸쳐 EC2 인스턴스의 기본 설정을 가진 오토 스케일링 그룹에서 호스팅 되고 있다. 앞단에는 Application Load Balancer가 있다, 애플리케이션으로 들어오는 트래픽이 적기 때문에 축소 정책이 트리거 되었다. 오토 스케일링 그룹에서 가장 먼저 종룟 할 EC2 인스턴스는 무엇인가 ? 1. 유저 세션이 가장 적은 EC2 인스턴스 2. 가장 오랜시간 시간 실행된 EC2 인스턴스 3. 랜덤으로 선택 4. 가장 오래된 설정에서 시작된 EC2 인스턴스 #### 설명 기본 종료 정책은 아키텍처가 가용 영역을 균등하게 확장하도록 설계되어 있다. 기본 정책을 사용하는 경우 오토 스케일링 그룹의 동작은 아래와 같다. 1. 종료할 인스턴스를 결정하고 종료 중인 온디맨드 또는 스팟 인스턴스의 할당 전략에 나머지 인스턴스를 맞춘다. 2. 가장 오래된 시작 템플릿 또는 구성을 사용하는 인스턴스가 있는지 확인한다. 3. 위의 기준에 따라 종료할 비보호 인스턴스가 여러 개 있는 경우, 다음 결제 시간에 가장 근접한 인스턴스가 무엇인지 확인한다. 다음 번 결제 시간에 가장 근접한 인스턴스가 여러 개인 경우 이러한 인스턴스 중 하나를 임의로 종료한다. 답 : 4 ### Question #62 인기있는 소셜 네트워크 서비스는 AWS에서 호스팅 되며 DynamoDB 테이블을 데이터베이스로 사용한다. 사용자가 특정 사용자가 만든 업데이트를 구독하고 이메일로 알림을 받을 수 있는 팔로우 기능을 구현해야 한다. 이 요구사항을 충족하기 위해 구현해야 하는 가장 적합한 솔류션은 무엇인가. 1. DynamoDB Stream을 활성화하고 AWS Lambda 트리거를 생성한다. 이 Lambda 함수는 런타임에 필요한 모든 권한을 가진다. 스트림의 데이터는 Lambda에 의해서 처리되고 SNS에 메시를 게시하여 Email로 사용자에게 전송한다. 2. DynamoDB 테이블에 대해서 DAX cluster 설정을 한다. 새로운 DynamoDB trigger와 Lambda 함수를 설정한다. 사용자 데이터에 대한 업데이트가 발생 할 때마다 Lambda 함수를 실행하고 SNS를 이용해서 Email을 전송한다. 3. Kinesis Client Library(KCL)을 이용해서 DynamoDB Stream 엔드포인트에서 데이터를 가져오는 DynamoDB Stream Kinesis Adapter를 만든다. 특정 사용자가 업데이트를 하면 SNS를 이용해서 사용자에게 알림을 전송한다. 4. Kinesis Client Library(KCL)을 이용해서 DynamoDB Stream 엔드포인트에서 데이터를 가져오는 DynamoDB Stream Kinesis Adapter를 만든다. 특정 사용자의 데이터가 업데이트 되면 메일을 전송하도록 SNS 토픽을 설정한다. #### 설명 DynamoDB 스티름은 어떤 DynamoDB 테이블에서든 시간 순서에 따라 항목 수정사항을 캡처하여 이 정보를 최대 24시간 동안 로그에 저장한다. 로그와 데이터 항목은 거의 실시간으로 기록되기 때문에 이러한 로그와 데이터에 엑세스 할 수 있다. 애플리케이션에서 테이블 항목을 생성, 삭제 업데이트 또는 삭제할 때마다 DynamoDB 스트림은 수정된 항목의 기본 키 속성을 사용하여 스트림 레코드를 작성한다. 스트림 레코드에는 DynamoDB 테이블의 단일 항목에 대한 변경정보가 포함된다. DynamoDB 스트림은 AWS Lambda와 통합되어 있으므로 DynamoDB 스트림의 이벤트에 자동으로 응답하는 코드의 트리거를 생성할 수 있다. 트리거를 사용하면 DynamoDB 테이블의 데이터 수정에 반응하는 애플리케이션을 구축할 수 있다. 테이블에서 DynamoDB 스트림을 활성화하면 스트림의 ARN을 Lambda 함수와 연결할 수 있다. 테이블의 항목이 수정 된 직후 테이블의 스트림에 새로운 레코드가 생성된다. AWS Lambda는 스트림을 폴링하고 새 스트림 레코드를 감지하면 Lambda 함수를 동기식으로 호출한다.  1. 사용자는 DynamoDB 테이블(BarkTable)에 항목을 작성한다. 2. 작성된 새 스트림 레코드는 새 항목이 BarkTable에 추가되었다는 것을 반영한다. 3. 새 스트림 레코드에서 AWS Lambda 함수(publishNewBark)를 트리거한다. 4. 스트림 레코드가 새 항목이 BarkTable에 추가되었음을 나타내는 경우 Lambda 함수는 스트림 코드에서 데이터를 읽고 SNS 주제에 메시지를 개시한다. 5. Amazon SNS 주제 구독자는 메시지를 수신한다. KCL을 사용하여 DynamoDB Streams 엔드포인트에서 데이터를 가져올 DynamoDB Streams Kinesis 어댑터를 작성하고, 특정 사용자가 업데이트 한 경우 SNS를 사용하여 이메일을 전송하는 것은 유효한 솔류션이다. 하지만 DynamoDB 스트림을 활성화하는 중요 단계가 빠졌기 때문에 올바른 답이 아니다. DAX(DynamoDB Accelerator)은 인-메모리를 이용한 읽기 성능을 향상하는데 사용하기 때문에 올바른 답이 아니다. ### Question #63 인기있는 모바일 게임은 CloudFront, Lambda, DynamoDB를 이용한 백앤드로 구축되어 있다. 사용자 데이터는 DynamoDB 테이블에 유지되며, 정적자산은 CloudFront에 배포된다. 그러나 사용자 정보를 저장하고 검색하는데 많은 시간이 걸린다는 불만이 있다. 게임 성능을 개선하기 위해서 DynamoDB 응답 시간을 밀리초에서 마이크로초로 줄이는데 사용 할 수 있는 AWS 서비스는 무엇인가. 1. AWS Device Farm 2. DynamoDB Auto SCaling 3. Amazon DynamoDB Accelerator (DAX) 4. Amazon ElastiCache #### 설명 DAX는 Amazon DynamoDB를 위한 뛰어난 가용성의 완전관리형 인 메모리 Cache로, 초당 요청 수가 몇 백만 개인 경우에도 몇 밀리초에서 몇 마이크로 초까지 최대 10배의 성능을 제공한다. 개발자는 캐시 무효화, 클러스터 관리 또는 데이터 집단을 관리할 필요 없이 DynamoDB 인 메모리 가속화를 위한 모든 작업을 수행한다. 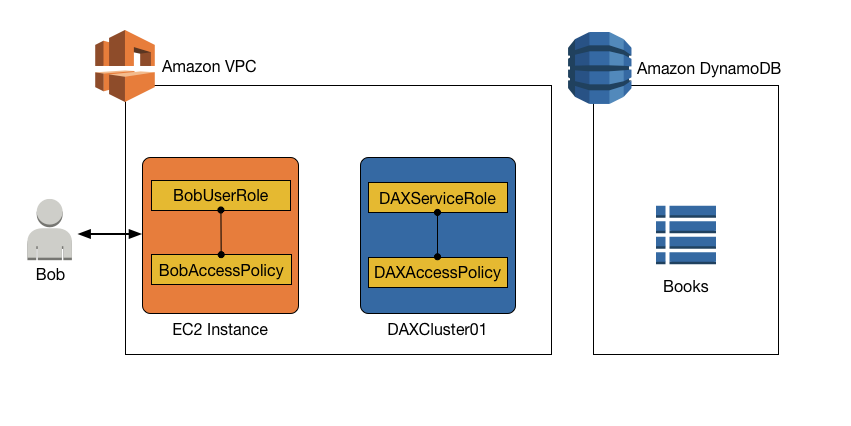 * Amazon ElastiCache를 데이터베이스 캐시로 사용할 수 있지만 DAX와 비교하여 응답 시간을 마이크로 초 단위로 줄일 수 없기 때문에 올바르지 않다. * AWS Device Farm은 한 번에 여러 디바이스에서 Android, iOS 및 웹 앱을 테스트하는 웹 테스트 서비스다. * DynamoDB Auto Scaling은 용량관리를 자동화하기 위한 솔류션이다. 답 : 3 ### Question #64 회사는 애플리케이션의 일반 워크로드를 지원하기 위해서 최소 2개의 EC2 인스턴스를 배포하고 최대 워크로드를 처리하기 위해서 최대 6개의 EC2 인스턴스로 자동확장해야 한다. 아키텍처는 미션 크리티컬 워크로드를 처리해야 하므로 고 가용성과 내결함성을 가져야 한다. 회사의 솔류션 아키텍트로서 위의 요구사항을 충족하려면 어떻게 해야 하는가 ? 1. 최소 용량이 2이고 최대 용량이 4인 EC2 인스턴스용 오토 스케일링 그룹을 생성한다. 가용 영역 A에 2개의 인스턴스를 배치하고, 가용 영역 B에 2개의 인스턴스를 배치한다. 2. 최소 용량이 2이고 최대 용량이 6인 EC2 인스턴스용 오토 스케일링 그룹을 생성한다. 가용 영역 A에 4개의 인스턴스를 배치한다. 3. 최소 용량이 2이고 최대 용량이 6인 EC2 인스턴스용 오토 스케일링 그룹을 생성한다. 2개의 가용영역에 각 1개의 인스턴스를 배치한다. 4. 최소 용량이 4이고 최대 용량이 6인 EC2 인스턴스용 오토 스케일링 그룹을 생성한다. 가용 영역 A와 B에 2개씩의 인스턴스를 배치한다. #### 설명 고가용성 및 내결함성을 가지는 애플리케이션을 위해서는 인스턴스를 서로 다른 가용 영역에 배포해야 한다. 이렇게 하면 특정 가용 영역에 문제가 생기더라도 다른 가용 영역에서 서비스를 계속 할 수 있다. 내 결함성을 달성하려면 서버 장애 또는 가용 영역 중단시 시스템 성능 저하를 방지하기 위한 최소한의 중복 리소스가 있어야 한다. 시나리오에서 일반 트래픽을 처리하는데 최소 2개 이상의 인스턴스가 필요하다고 했다. 가용 영역이 중단되더라도 2개의 인스턴스가 실행되고 있어야 하므로 두 개의 가용 영역에 걸쳐서 4개의 인스턴스가 실행되고 있어야 한다. 가용 영역 A와 가용 영역 B에 각각 2개씩의 인스턴스가 실행되어야 한다. 답 : 4 ### Question #65 한 회사에서 소프트웨어 개발 및 인프라 관리 프로세스를 처리하는 3명의 DevOps 엔지니어가 있다. 엔지니어 중 한명이 Amazon S3에 호스팅된 파일을 실수로 삭제하여 서비스 중단을 일으켰다. 이러한 일이 다시 발생하지 않도록 DevOps 엔지니어는 무엇을 할 수 있는가 ? 1. 모든 유저가 서명된 URL을 사용하도록 한다. 2. 버킷의 객체를 지울 수 없는 IAM을 생성한다. 3. S3 IA 스토리지에 데이터를 저장한다. 4. S3 version을 활성화하고 버킷 삭제에 대해서 MFA를 활성화 한다. #### 설명 Amazon S3 버킷에서 실수로 데이터가 삭제되지 않도록 하려면 아래의 작업을 수행하면 된다. * S3 버전 관리 활성화 * MFA 활성화 버전 관리는 객체의 여러 변형을 동일한 버킷에 보관하는 수단이다. 버전 관리를 사용하여 S3에 저장된 모든 객체의 모든 버전을 보전, 검색 및 복원 할 수 있다. 이를 이용해서 의도하지 않은 사용자 작업으로 부터 객체를 복구 할 수 있다. MFA 삭제가 활성화된 경우 아래의 작업을 하기 위해서는 추가 인증이 필요하다. 1. 버킷의 버전 관리 상태 변경 2. 객체 버전을 영구적으로 삭제 답 : 4 ### 참고 * [Amazon RedShift 지역간 스냅샷 전송 성능 개선](https://aws.amazon.com/ko/about-aws/whats-new/2019/10/amazon-redshift-improves-performance-of-inter-region-snapshot-transfers/) * [Amazon RedShift, 지역 간 스냅샷 전송](https://aws.amazon.com/ko/about-aws/whats-new/2019/10/amazon-redshift-improves-performance-of-inter-region-snapshot-transfers/) * [AWS Lambda 내부 동작 및 활용 방법 자세히 살펴보기](https://www.slideshare.net/awskorea/aws-lambda-aws-aws-summit-seoul-2019) * [보안 또는 민감한 데이터를 Amazon ECS 태스크의 컨테이너에 안전하게 전달하려면 어떻게 해야 합니까 ?](https://aws.amazon.com/ko/premiumsupport/knowledge-center/ecs-data-security-container-task/)
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
architecture
aws
devops
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags