Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
Joinc와 함께하는 LLM - 개인 PC에 LLM 환경 구축하기
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2024-06-07
2024-06-06
2838
 ### LLM LLM은 "Large Language Model"의 약자로 우리나라 말로는 "대규모 언어 모델"이라고 부르곤 한다. LLM은 자연어 처리 작업을 수행하기 위해서 훈련된 신경망 모델이다. 간단히 말해서 대량의 텍스트 데이터를 학습해서 인간의 언어를 이해하고(정말 인간의 언어를 이해하는지는 여기에서 다룰 수 있는 내용은 아니다.) 인간과 상호작용 할 수 있는 능력을 가진 모델이다. ### LLM의 인기 LLM을 이용하면 방대한 양의 텍스트 데이터를 학습을 할 수 있고, 사용자는 인간의 언어를 이용해서 원하는 정보를 얻을 수 있다. 문서를 요약해주고, 코드를 만들어주고, 특정 주제에 대한 정리된 답을 얻을 수 있다. 챗봇, 번역, 글쓰기 보조, 코드 생성, 추천 시스템, 질문/응답, 감정 분석 등 폭넓은 영역에서 사용 할 수 있다. 이 때문에 많은 기업들이 LLM에 관심을 가지고 있다.  ### ollama를 이용한 LLM 학습 LLM이 주목을 받는 상황에서 개발자에게 가장 중요한 것은 "LLM에 대한 학습 환경"일 것이다. 가능한 저렴하고 빠르게 학습 할 수 있는 환경이 필요하다. 문제는 **고성능의 하드웨어**가 필요하다는 것이다. 일반적으로 LLM으로 무언가를 하려면 대규모의 GPU 클러스터가 필요하다. 클라우드를 이용 할 경우 더 많은 비용이 들어갈 것이다. **ollama**를 이용하면 개인 데스크탑에서도 LLM 학습 환경 구축이 가능하다. ### 데스크탑 환경 내 데스크탑 환경은 아래와 같다. * CPU: AMD Ryzen 5 5600X 6-Core processor * Memory: 16 Giga * GPU: Nvidia GeForce GTX 1660 Super 6G * 운영체제: 우분투 리눅스 23.10 매우 평범한 시스템이다. 2022년 쯤 사양인데, 100만원 정도면 더 나은 환경을 구축할 수 있을 것이다. 그리고 좀 느린 것만 빼면, GPU가 없이도 LLM 환경을 구축 할 수 있다. ### ollama Ollama는 LLM 학습과 이를 이용한 애플리케이션을 쉽게 개발할 수 있도록 지원하는 소프트웨어 플랫폼이다. 여러 모델을 관리 할 수 있으며, 훈련과 튜닝을 간단하게 할 수 있다. 로컬에서 사용할 수 있는데 Docker를 이용하면 더욱 쉽게 설치 할 수 있다. 👨🏫 [우분투리눅스에 Docker 설치하기](https://www.joinc.co.kr/w/man/12/docker/install) ### Docker로 ollama 설치하기 여기에서는 docker를 이용해서 ollama를 설치 할 것이다. ollama는 아래와 같이 CPU만으로 모델을 실행 할 수 있다. ``` docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama ``` Docker 컨테이너에서 Nvidia GPU를 사용하려면 [Nvidia container toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#installation)를 설치해야 한다. 나는 GPU를 가지고 있었으므로 아래와 같이 GPU를 사용 할 수 있도록 컨테이너를 실행했다. ``` docker run -d --gpus=all -v ollama:$HOME/.ollama -p 11434:11434 --name ollama ollama/ollama ``` 아래와 같이 컨테이너가 실행된 것을 확인 할 수 있다. ``` $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ec57dfdf91f1 ollama/ollama "/bin/ollama serve" 6 seconds ago Up 6 seconds 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama ``` GPU가 없다면 아래와 같이 컨테이너를 실행한다. ``` docker run -d -v ollama:$HOME/.ollama -p 11434:11434 --name ollama ollama/ollama ``` ### ollama가 지원하는 LLM 모델 ollama가 지원하는 모델은 [ollama model library](https://ollama.com/library)에서 확인 할 수 있다. 2024년 6월 현재 지원하는 모델은 아래와 같다. | Model | Parameters | Size | Download | | ------------------ | ---------- | ----- | ------------------------------ | | Llama 3 | 8B | 4.7GB | `ollama run llama3` | | Llama 3 | 70B | 40GB | `ollama run llama3:70b` | | Phi 3 Mini | 3.8B | 2.3GB | `ollama run phi3` | | Phi 3 Medium | 14B | 7.9GB | `ollama run phi3:medium` | | Gemma | 2B | 1.4GB | `ollama run gemma:2b` | | Gemma | 7B | 4.8GB | `ollama run gemma:7b` | | Mistral | 7B | 4.1GB | `ollama run mistral` | | Moondream 2 | 1.4B | 829MB | `ollama run moondream` | | Neural Chat | 7B | 4.1GB | `ollama run neural-chat` | | Starling | 7B | 4.1GB | `ollama run starling-lm` | | Code Llama | 7B | 3.8GB | `ollama run codellama` | | Llama 2 Uncensored | 7B | 3.8GB | `ollama run llama2-uncensored` | | LLaVA | 7B | 4.5GB | `ollama run llava` | | Solar | 10.7B | 6.1GB | `ollama run solar` | 나는 Meta의 Llama3 8B 모델을 사용하기로 했다. ### ollama 구조 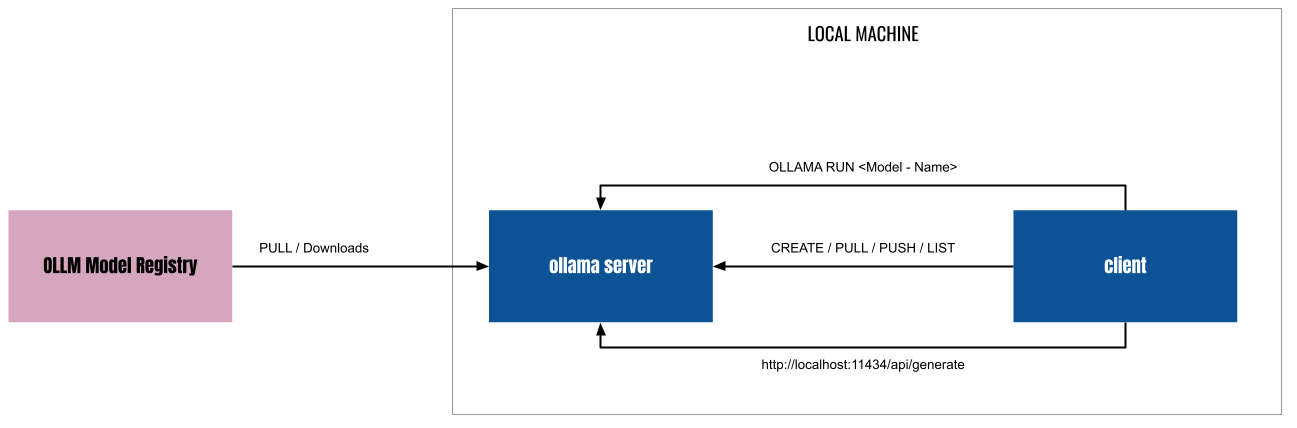 ollama는 **server / clinet** 모델로 작동한다. ollama 를 실행하면 server 가 실행되는데 http API를 이용해서 모델의 설치, 실행, 관리, 프롬프팅 등의 작업을 할 수 있다. ### LLAMA3에 대하여 [Llama3](https://llama.meta.com/llama3/)는 Meta(예전 Facebook)가 2024년 4월 공개한 LLM이다. 8B 모델과 70B 2개의 모델이 있는데, 8B 모델을 사용할 것이다. 70B 모델을 실행하기 위해서는 40G 이상의 메모리를 가진 NVIDIA A100, V100, H100 가 필요하기 때문에 데스크탑 환경에서 돌릴 수 있는 모델은 아니다. 학습목적으로는 8B면 충분하다. 아래는 Llama3의 벤치마크 자료다. 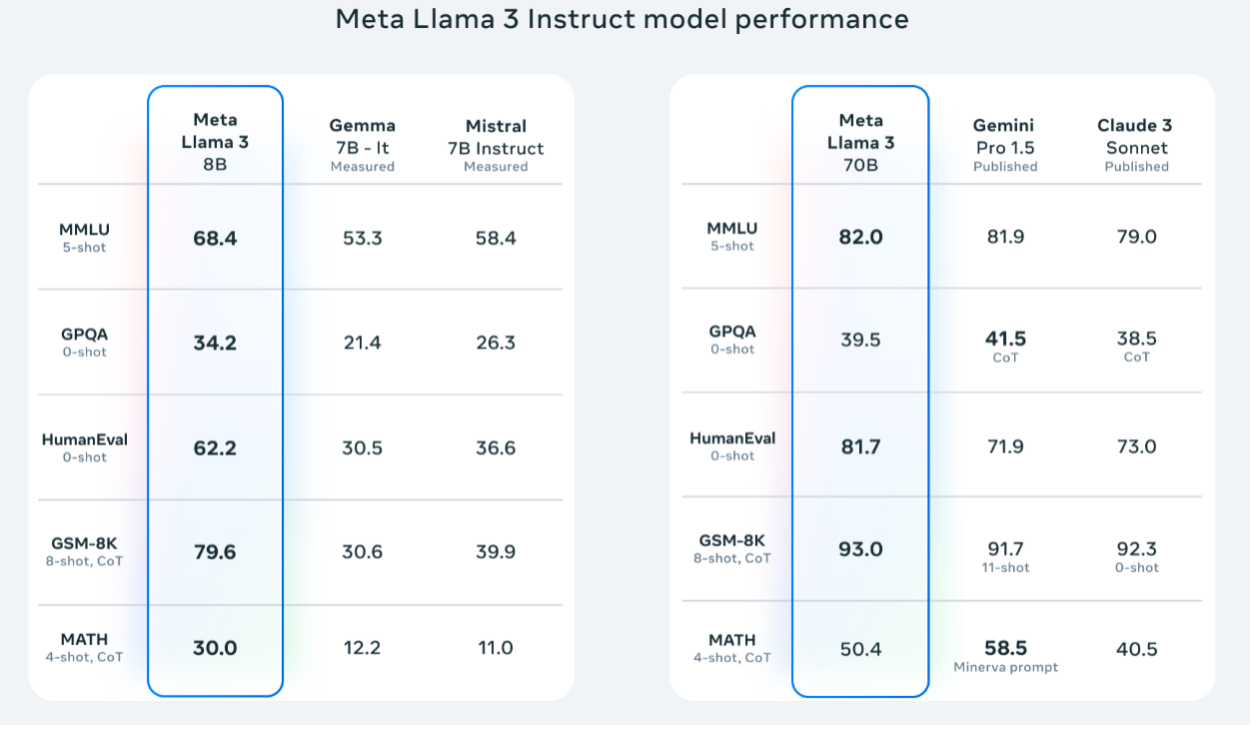 ### LLAMA3 모델 설치 및 테스트 docker로 실행한 ollama 서버가 작동하고 있는지 테스트해보자. ``` $ curl localhost:11434 Ollama is running ``` 이제 Llama3 모델을 로딩 한다. 모델의 크기가 4.7G 정도 되므로 다운로드하는데 시간이 좀 걸릴 것이다. ``` docker exec -it ollama ollama run llama3 ``` 다운로드가 끝나면 프롬프트가 뜨는데, 이를 이용해서 테스트를 할 수 있다. ``` >>> Tell me about South Korea's President Yoon Seok-yeol. A great topic! Yoon Seok-yeol (, 1958-) is a South Korean attorney and politician who served as the 13th President of South Korea from March 2022 to February 2023. Here are some key facts about him: 1. **Background**: Yoon was born in Gwangju, South Korea. He earned his law degree from Seoul National University and later worked as a prosecutor and attorney. .... ``` **curl** 로도 테스트 해볼 수 있다. ``` curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt": "Why is the sky blue?" }' ``` ### GPU 모니터링 하기 **nvidia-smi** 프로그램을 이용하면 GPU 상태를 모니터링 할 수 있다. watch 와 함께 사용하면 테스트 중 GPU의 사용량을 주기적으로 모니터링 할 수 있다. ``` watch -n 0.5 nvidia-smi ``` 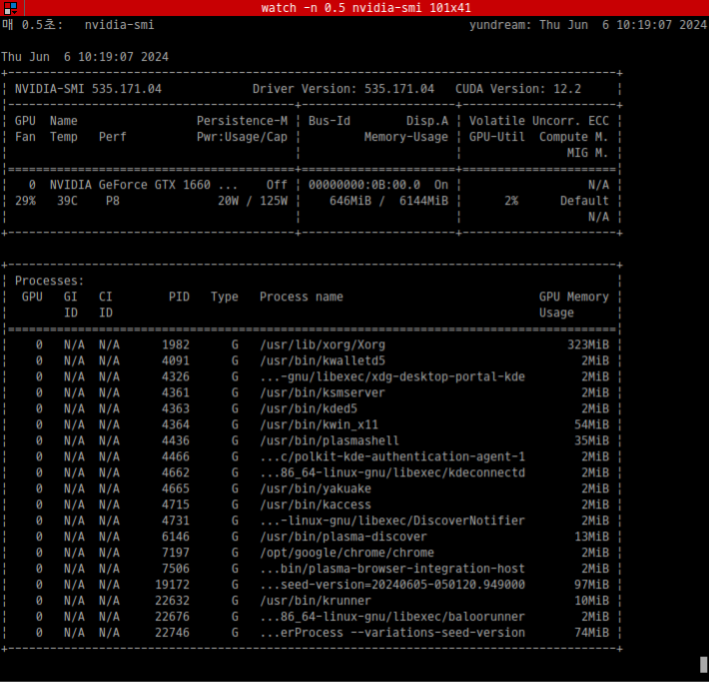 ### WebUI 설치 CLI 프롬프트나 curl 대신 ollama의 open-webui를 이용해서 chatgpt와 같은 환경을 만들 수 있다. 역시 docker를 이용해서 설치해보자. ``` docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main ``` * -d: 데몬 모드로 시작한다. * --network=host: ollama server에 연결해야 하기 때문에, docker의 브릿지 네트워크가 아닌 호스트 네트워크에 연결하도록 설정한다. * -v open-webui:/app/backend/data: open-webui 컨테이너가 사용할 볼륨을 설정한다. * -e OLLAMA_BASE_URL: Ollama의 기본 URL을 환경변수로 설정한다. http://localhost:8080 으로 접속하면 아래와 같이 web page를 확인 할 수 있다.  앞서 설치한 llama3 모델을 선택한다. 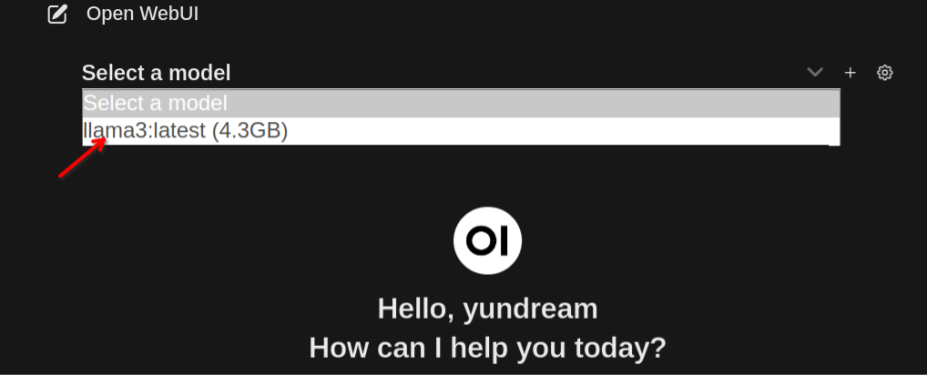 이제 메시지를 입력하면, 답을 주는 것을 확인 할 수 있다.  ### 정리 이렇게 개인 PC에 ollama를 이용해서 최신 언어모델인 Llama3 를 실행했다. 다음 블로그에서는 Ollama를 이용해서 **Embedding models**을 살펴볼 생각이다(아마도).
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
AI
Joinc와 함께하는 LLM
LLM
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags