Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
Joinc와 함께하는 LLM - LangChain & OpenAI 기반 RAG 구성
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2024-06-15
2024-06-15
787
 ### 소개 여기에서는 LangChain과 OpenAI API를 사용해서 RAG 시스템을 구현해 볼 것이다. 이 문서의 내용을 따라하기 위해서는 OpenAI API를 가지고 있어야 하며, Python을 사용할 줄 알아야 한다. * OpenAI API: https://platform.openai.com/ 을 방문하여 가입한 후 API Key를 발급 받을 수 있다. 이 문서의 목표는 아래와 같다. 1. 추가적인 정보(기업의 정보 혹은 내가 가지고 있는 정보)를 기반으로 AI를 강화하기 위한 RAG 시스템을 이해한다. 2. 정보 검색 시스템을 기반으로 AI를 강화하기 위해서 데이터를 준비하고 [벡터화](https://www.joinc.co.kr/w/vector_embedding_basic) 한다. 3. RAG 시스템을 활용하는 대화형 AI의 제작 ### 환경 1. 우분투 리눅스 2. Python 3.x 3. VS Code 4. LangChain 5. OpenAI 6. Pinecone ### RAG ChatGPT와 같은 AI 서비스는 매우 많은 데이터를 기반으로 응답을 제공한다. 하지만 완벽하지는 않다. 계속해서 추가되는 데이터들을 반영하는데 시간이 걸리며, 특히 기업과 개인이 가지고 있는 전문 지식들의 경우 학습이 어렵거나 불가능하기 때문에 답을 얻기가 쉽지 않다. RAG는 검색 기반으로 AI를 강화한다. 새로운 정보를 데이터베이스에 저장하고, 이 정보들을 LLM에 제공함으로써, LLM 모델의 내부 지식외에도 다양한 외부 정보 소스를 활용하여 보다 정확하고 상황에 맞는 응답을 제공 할 수 있다. 실제로 RAG는 먼저 사용자의 쿼리를 분석한 다음, 대규모 데이터베이스를 검색하여 관련 정보를 검색하고 가장 관련성이 높은 데이터를 선택하여서 응답을 생성하는 방식으로 작동한다. 이로 인해서 RAG는 실질적으로 정확한 정보들을 제공하기 때문에, 높은 신뢰성을 제공해야 하는 전문 영역에서 특히 효과적으로 사용 할 수 있다. ### 아키텍처 우리가 만들 RAG 시스템 아키텍처는 아래와 같다. 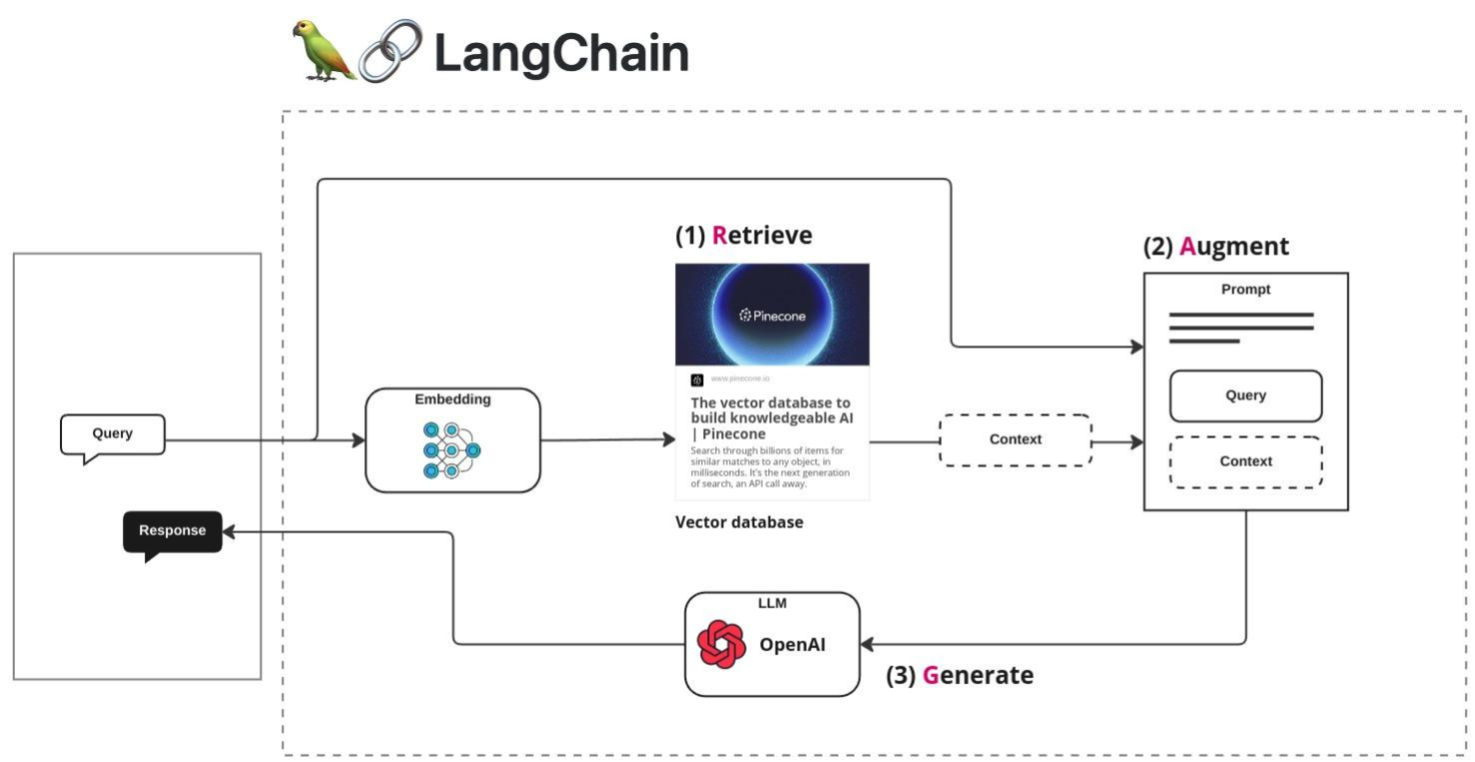 아래 모든 과정은 **LangChain** 이 처리한다. 1. 벡터 데이터베이스로 Pinecone를 사용한다. 여기에 medium.com의 기사를 벡터화 해서 저장을 한다. 2. 사용자가 쿼리를 내리면 임베딩 모델에 따라서 벡터화가 되고, Pinecone는 Similarity search를 이용해서 쿼리에 맞는 문장을 리턴한다. 3. 사용자 쿼리와 검색된 컨텍스트를 OpenAI API로 전달하면 OpenAI는 응답을 만들어서 리턴한다. ### Pinecone [Pinecone.io](https://www.pinecone.io/)는 벡터 데이터베이스(Vector Database)를 제공하는 서비스 업체다. SaaS 형태로 제공되기 때문에 따로 벡터 데이터베이스를 설치할 필요가 없어서 빠르게 RAG 시스템을 구축 할 수 있다. 무료로도 테스트 정도는 충분히 할 수 있다. 서비스 가입한 한 후 API Key를 다운로드 받도록 하자. 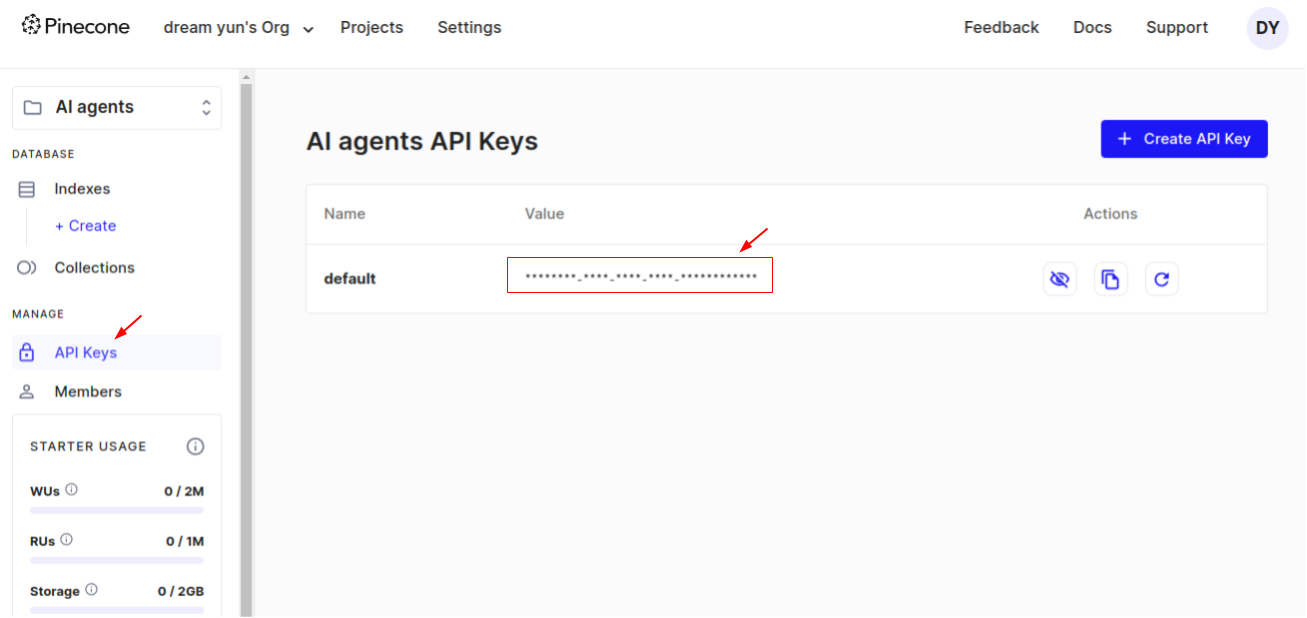 ### 준비 확인 아래의 것들이 준비되어 있는지 확인한다. * OPENAI API KEY: Chat 모델은 gpt-4o를 선택했다. gpt-3.5-turbo의 경우 제대로 작동하지 않을 수 있다. * PINECONE API KEY * PINECONE Vector Index: meduim-blog 로 생성. 이 값들은 .env 파일에 저장해서 사용하도록 하자. ``` OPENAI_API_KEY=sk-proj-7zb................................S INDEX_NAME=medium-blog PINECONE_API_KEY=a....................................55 ``` ### Ingestion RAG에 사용할 문서를 준비하고 이를 Pinecone 벡터 데이터베이스에 색인한다. 이 과정을 **Ingestion** 이라고 하는데, 아래와 같은 과정을 거친다.  1. medium.com 블로그 문서를 로딩: TextLoader 2. 문서를 chunk 단위로 분할: TextSplitter 3. Chunk를 임베드하고 벡터를 얻는다: OpenAIEmbedding 4. Pinecone vectorstore에 벡터를 임베딩: PineconeVectorStore 이 순서대로 작동하는 코드를 만들면 된다. 복잡해 보일 수 있지만 **LangChain**을 이용하면 간단하게 수행 할 수 있다. ### medium.com 문서 로딩 medium blog에 있는 [Vector Database: What is it and why you should know it?](https://medium.com/@EjiroOnose/vector-database-what-is-it-and-why-you-should-know-it-ae7e7dca82a4#:~:text=Vector%20databases%20can%20be%20used,not%20all%20vectors%20are%20embeddings) 문서의 내용 임베딩하겠다. 텍스트 내용은 그냥 브라우저에서 복사&붙여넣기 했다. 파일의 이름은 medium_blog.txt로 했다. 파일을 로딩하고 임베딩하기 전까지의 전처리 과정을 살펴보자. ```python import os from dotenv import load_dotenv from langchain_community.document_loaders import TextLoader from langchain_text_splitters import CharacterTextSplitter from langchain_openai import OpenAIEmbeddings from langchain_pinecone import PineconeVectorStore load_dotenv() if __name__ == "__main__": print("Ingesting...") loader = TextLoader("./medium_blog.txt") document = loader.load() print("splitting...") text_splitter = CharacterTextSplitter(chunk_size = 1000, chunk_overlap=0) texts = text_splitter.split_documents(document) print("splitting completing") ``` **TextLoader** 함수를 이용해서 문서를 로딩한다. [document loaders](https://python.langchain.com/v0.2/docs/integrations/document_loaders/) 페이지를 방문하면, 커뮤니티에서 지원하는 수십개의 로더를 확인 할 수 있다. **CharacterTextSplitter** 함수를 이용해서 문서를 chunk 단위로 나눴다. 긴 문서를 하나의 벡터로 변환하면 특정 문장이나 단락에 대한 검색이 어렵다. chunk 단위로 나누어 벡터화하면 보다 구체적이고 정확한 검색이 가능하다. 또한 대부분의 자연어 처리 모델은 입력길이에 제한이 있다. 예를 들어 BERT와 같은 모델은 최대 토큰 수가 정해져 있어서 긴 문서를 그대로 입력할 수 없다. chunk로 나누어 입력해야 한다. 여기에서는 chunk 크기를 1000(chunk_size=1000)으로 했다. 디버그 모드에서 살펴보면 16개의 청크로 나누어진 것을 확인 할 수 있다.  ### Ingesting 앞에서 사전 준비된 문서를 Pinecone Vector Store에 임베딩해보자. 앞의 코드에 계속 이어서 만들면 된다. ```python print("splitting completing") embeddings = OpenAIEmbeddings(openai_api_key = os.environ.get("OPENAI_API_KEY")) print("ingesting....") PineconeVectorStore.from_documents(texts, embeddings, index_name=os.environ['INDEX_NAME']) ``` **OpenAIEmbeddings** 함수를 이용해서 임베딩 모델에 접근한다. OpenAI는 3개의 임베딩 모델을 제공한다. | MODEL | ~ PAGES PER DOLLAR | PERFORMANCE ON [MTEB](https://github.com/embeddings-benchmark/mteb) EVAL | MAX INPUT | | ---------------------- | ------------------ | ------------------------------------------------------------------------ | --------- | | text-embedding-3-small | 62,500 | 62.3% | 8191 | | text-embedding-3-large | 9,615 | 64.6% | 8191 | | text-embedding-ada-002 | 12,500 | 61.0% | 8191 | 코드를 성공적으로 실행하면 medium-blog 인덱스에 벡터가 만들어진 것을 확인 할 수 있다. 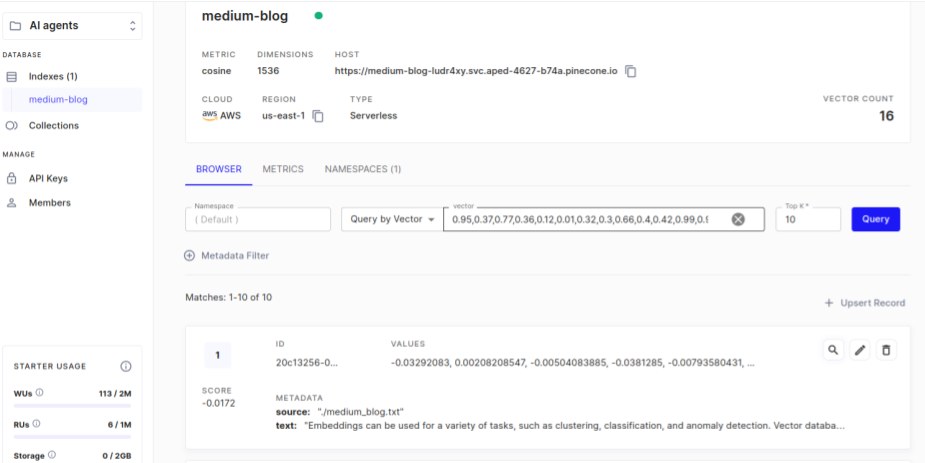 ### Retrieval **벡터 데이터베이스**로 부터 정보를 **검색**하여 컨텍스트를 추가 한다음 LLM에 응답을 요청할 것이다. 아래 그림은 이 과정을 묘사하고 있다.  사용자가 Query(질문)를 만든다. 이 질문은 벡터 임베딩되고 벡터 데이터베이스에서 검색된다. 질문에 유사한 문장을 리턴을 하면, 이 문장으로 프롬프트를 만들어서 LLM에 전달한다. 현재 Pinecone 데이터베이스에는 LangChain과 문서가 저장되어 있으므로, LangChain 관련 문장을 가져와서 LLM에 전달할 것이다. LLM이 이 문장을 요약해서 응답한다. RAG를 적용하기 전의 응답을 살펴보자. ```python from dotenv import load_dotenv from langchain_core.prompts import PromptTemplate from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_pinecone import PineconeVectorStore load_dotenv() if __name__ == "__main__": print("Retrieving...") llm = ChatOpenAI() query = "what is Pinecone in machine learning ?" chain = PromptTemplate.from_template(template=query) | llm result = chain.invoke(input={}) print(result.content) ``` RAG 없이 실행해보자. 이 경우 OpenAI의 응답을 출력하게 된다. ``` Retrieving... In machine learning, a pinecone refers to a type of algorithm used for hierarchical clustering. This algorithm works by creating a tree structure of clusters, with each cluster containing subsets of data points that are similar to each other. The pinecone algorithm is named for its resemblance to a pinecone, with the data points forming the bracts of the cone. This algorithm is commonly used for grouping data points into clusters based on their similarity, making it useful for tasks such as customer segmentation, image segmentation, and pattern recognition. ``` ### RAG 적용 PineconeVector Store에 저장된 벡터를 기반으로 RAG를 적용한 코드다. ```python import os from dotenv import load_dotenv from langchain_core.prompts import PromptTemplate from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_pinecone import PineconeVectorStore from langchain import hub from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains.retrieval import create_retrieval_chain load_dotenv() if __name__ == "__main__": print("Retrieving...") embeddings = OpenAIEmbeddings() llm = ChatOpenAI() query = "what is Pinecone in machine learning ?" chain = PromptTemplate.from_template(template=query) | llm result = chain.invoke(input={}) print(result.content) vectorstore = PineconeVectorStore( index_name=os.environ["INDEX_NAME"], embedding=embeddings ) retrieval_qa_chat_prompt = hub.pull("langchain-ai/retrieval-qa-chat") combine_docs_chain = create_stuff_documents_chain(llm, retrieval_qa_chat_prompt) retrival_chain = create_retrieval_chain( retriever = vectorstore.as_retriever(), combine_docs_chain = combine_docs_chain ) result = retrival_chain.invoke(input= {"input":query}) print(result) ``` **OpenAIEmbeddings**: 임베딩 모델을 로딩한다. 임베딩 모델을 설정하지 않으면 "text-embedding-ada-002" 모델을 사용한다. model 매개 변수를 이용해서 임베딩 모델을 설정 할 수 있다. ```python OpenAIEmbeddings(model="text-embedding-ada-002") ``` **PineconeVectorStore**: PineCone 벡터 데이터베이스와 상호 작용하기 위해 사용되는 클래스다. **medium-blog** 색인을 연결했으며, OpenAIEmbedding 임베딩 모델을 사용했다. **hub.pull**: [LangChain Hub](https://smith.langchain.com/hub)는 LangChain 프레임워크에서 사용하는 모델, 데이터베이스, 에이전트, 체인, 프롬프트 등을 저장하고 있는 일종의 라이브러리 저장소다. hub.pull을 이용해서 LangChain Hub에 있는 여러 리소스를 가져다 사용 할 수 있다. 여기에서는 qa 검색을 위한 프롬프트 템플릿을 사용하고 있다. 해당 템플릿의 내용은 [https://smith.langchain.com/hub/langchain-ai/retrieval-qa-chat](https://smith.langchain.com/hub/langchain-ai/retrieval-qa-chat) 에서 확인 할 수 있다.  **create_stuff_documents_chain** 은 문서처리를 위한 체인을 설정하기 위해서 사용한다. retrieval_qa_chat_prompt를 이용한 OpenAI 체인을 설정했다. **create_retrieval_chain** 을 이용, 벡터 검색을 할 vector store를 설정하고 LLM 체인을 설정한다. 마지막으로 retrival_chain.invoke 를 이용해서 "query"를 실행한다. 실행 결과는 아래와 같다. 첫번째 결과는 RAG 없이 OpenAI에 요청한 결과다. ``` In machine learning, a pinecone is a type of data structure used to represent a decision tree. Decision trees are a popular machine learning algorithm used for classification and regression tasks. The pinecone structure is similar to a tree structure, with nodes representing decision points and branches representing possible outcomes. The pinecone structure is used to efficiently store and manipulate decision trees in machine learning models. ``` 아래 결과는 RAG 결과다. 내용이 길어서 일부 생략했다. ``` Pinecone is designed to be fast and scalable, allowing for efficient retrieval of similar data points based on their vector representations.\nIt can handle large-scale ML applications with millions or billions of data points.\nPinecone provides infrastructure management or maintenance to its users.\nPinecone can handle high query throughput and low latency search.\nPinecone is a secure platform that meets the security needs of businesses and ... ``` ### 정리 RAG? 어렵게 생각 할 것 없다. 현실에서 여러분이 누군가의 질문에 답을 해줘야 하는 상황이라고 가정해 보자. 여러분에게 충분한 지식이 없다면, 1. 인터넷으로 검색을 한다음에: Vector database 2. 문장 능력을 이용해서 이를 요약해서 응답을 전달: LLM 할 것이다. RAG가 하는 일이다.
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
AI
Joinc와 함께하는 LLM
LangChain
LLM
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags